 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOurDB: Ouroboric Domain Bridging for Multi-Target Domain Adaptive Semantic Segmentation
Mar 18, 2024

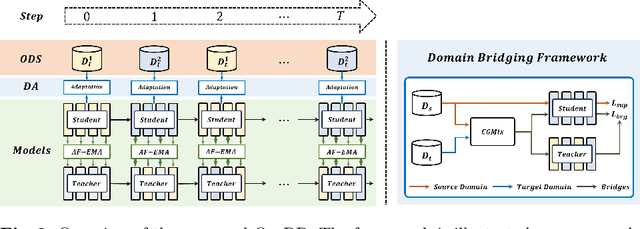

Multi-target domain adaptation (MTDA) for semantic segmentation poses a significant challenge, as it involves multiple target domains with varying distributions. The goal of MTDA is to minimize the domain discrepancies among a single source and multi-target domains, aiming to train a single model that excels across all target domains. Previous MTDA approaches typically employ multiple teacher architectures, where each teacher specializes in one target domain to simplify the task. However, these architectures hinder the student model from fully assimilating comprehensive knowledge from all target-specific teachers and escalate training costs with increasing target domains. In this paper, we propose an ouroboric domain bridging (OurDB) framework, offering an efficient solution to the MTDA problem using a single teacher architecture. This framework dynamically cycles through multiple target domains, aligning each domain individually to restrain the biased alignment problem, and utilizes Fisher information to minimize the forgetting of knowledge from previous target domains. We also propose a context-guided class-wise mixup (CGMix) that leverages contextual information tailored to diverse target contexts in MTDA. Experimental evaluations conducted on four urban driving datasets (i.e., GTA5, Cityscapes, IDD, and Mapillary) demonstrate the superiority of our method over existing state-of-the-art approaches.
Localization Uncertainty Estimation for Anchor-Free Object Detection
Jun 28, 2020

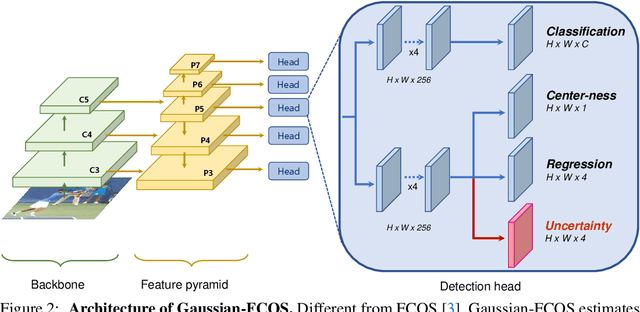
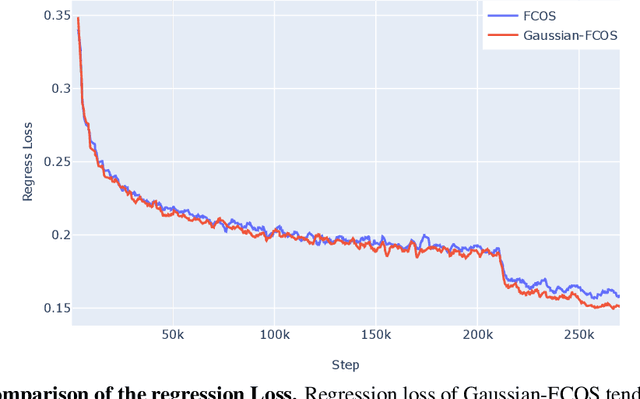
Since many safety-critical systems such as surgical robots and autonomous driving cars are in unstable environments with sensor noise or incomplete data, it is desirable for object detectors to take the confidence of the localization prediction into account. Recent attempts to estimate localization uncertainty for object detection focus only anchor-based method that captures the uncertainty of different characteristics such as location (center point) and scale (width, height). Also, anchor-based methods need to adjust sensitive anchor-box settings. Therefore, we propose a new object detector called Gaussian-FCOS that estimates the localization uncertainty based on an anchor-free detector that captures the uncertainty of similar property with four directions of box offsets (left, right, top, bottom) and avoids the anchor tuning. For this purpose, we design a new loss function, uncertainty loss, to measure how uncertain the estimated object location is by modeling the uncertainty as a Gaussian distribution. Then, the detection score is calibrated through the estimated uncertainty. Experiments on challenging COCO datasets demonstrate that the proposed new loss function not only enables the network to estimate the uncertainty but produces a synergy effect with regression loss. In addition, our Gaussian-FCOS reduces false positives with the estimated localization uncertainty and finds more missing-objects, boosting both Average Precision (AP) and Recall (AR). We hope Gaussian-FCOS serve as a baseline for the reliability-required task.
An Energy and GPU-Computation Efficient Backbone Network for Real-Time Object Detection
Apr 22, 2019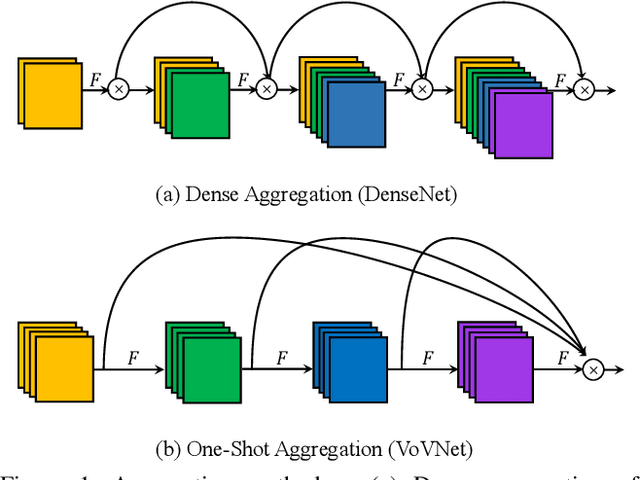
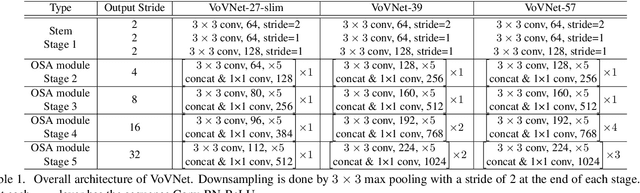
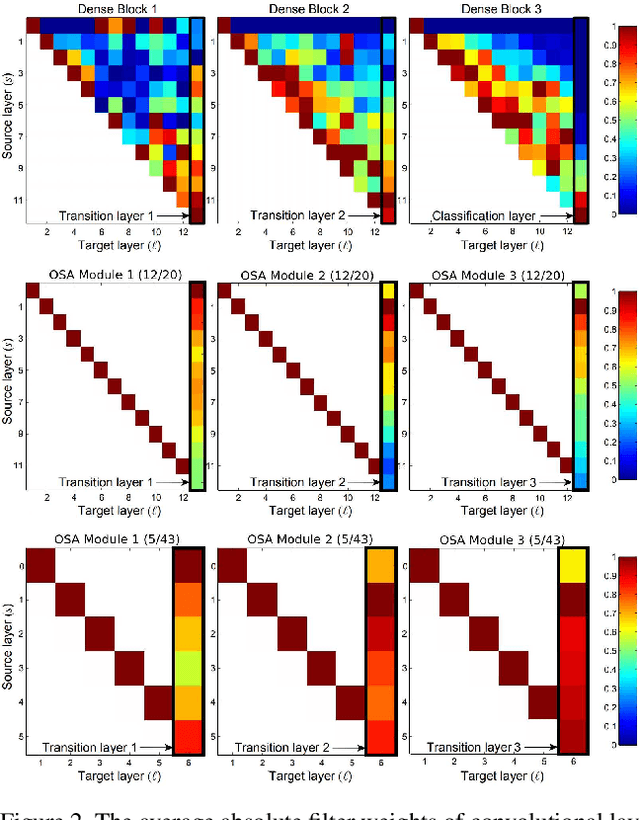
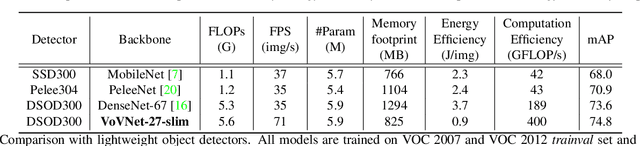
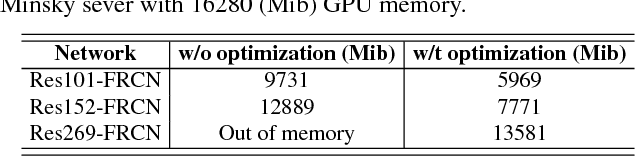
As DenseNet conserves intermediate features with diverse receptive fields by aggregating them with dense connection, it shows good performance on the object detection task. Although feature reuse enables DenseNet to produce strong features with a small number of model parameters and FLOPs, the detector with DenseNet backbone shows rather slow speed and low energy efficiency. We find the linearly increasing input channel by dense connection leads to heavy memory access cost, which causes computation overhead and more energy consumption. To solve the inefficiency of DenseNet, we propose an energy and computation efficient architecture called VoVNet comprised of One-Shot Aggregation (OSA). The OSA not only adopts the strength of DenseNet that represents diversified features with multi receptive fields but also overcomes the inefficiency of dense connection by aggregating all features only once in the last feature maps. To validate the effectiveness of VoVNet as a backbone network, we design both lightweight and large-scale VoVNet and apply them to one-stage and two-stage object detectors. Our VoVNet based detectors outperform DenseNet based ones with 2x faster speed and the energy consumptions are reduced by 1.6x - 4.1x. In addition to DenseNet, VoVNet also outperforms widely used ResNet backbone with faster speed and better energy efficiency. In particular, the small object detection performance has been significantly improved over DenseNet and ResNet.
Rank of Experts: Detection Network Ensemble
Dec 01, 2017
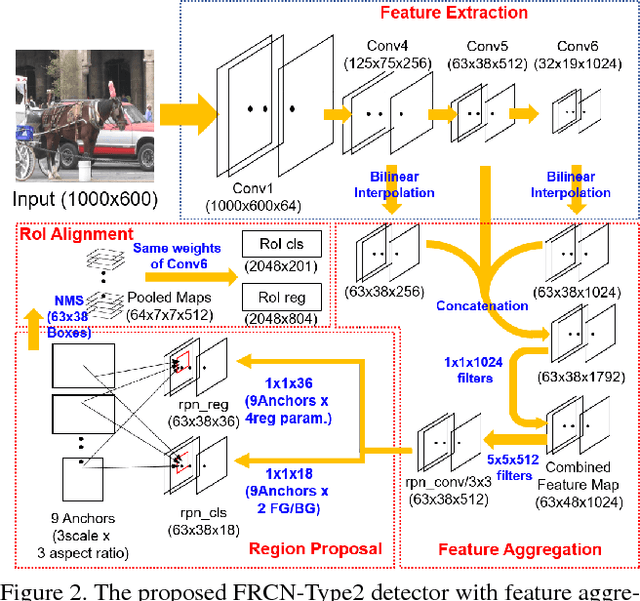
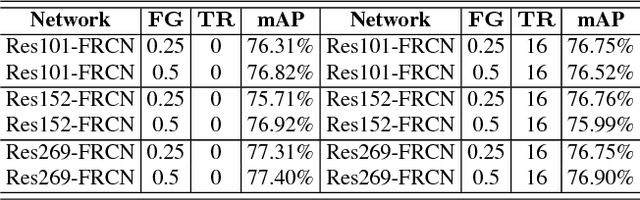
The recent advances of convolutional detectors show impressive performance improvement for large scale object detection. However, in general, the detection performance usually decreases as the object classes to be detected increases, and it is a practically challenging problem to train a dominant model for all classes due to the limitations of detection models and datasets. In most cases, therefore, there are distinct performance differences of the modern convolutional detectors for each object class detection. In this paper, in order to build an ensemble detector for large scale object detection, we present a conceptually simple but very effective class-wise ensemble detection which is named as Rank of Experts. We first decompose an intractable problem of finding the best detections for all object classes into small subproblems of finding the best ones for each object class. We then solve the detection problem by ranking detectors in order of the average precision rate for each class, and then aggregate the responses of the top ranked detectors (i.e. experts) for class-wise ensemble detection. The main benefit of our method is easy to implement and does not require any joint training of experts for ensemble. Based on the proposed Rank of Experts, we won the 2nd place in the ILSVRC 2017 object detection competition.