 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeESGCN: Edge Squeeze Attention Graph Convolutional Network for Traffic Flow Forecasting
Jul 12, 2023Traffic forecasting is a highly challenging task owing to the dynamical spatio-temporal dependencies of traffic flows. To handle this, we focus on modeling the spatio-temporal dynamics and propose a network termed Edge Squeeze Graph Convolutional Network (ESGCN) to forecast traffic flow in multiple regions. ESGCN consists of two modules: W-module and ES module. W-module is a fully node-wise convolutional network. It encodes the time-series of each traffic region separately and decomposes the time-series at various scales to capture fine and coarse features. The ES module models the spatio-temporal dynamics using Graph Convolutional Network (GCN) and generates an Adaptive Adjacency Matrix (AAM) with temporal features. To improve the accuracy of AAM, we introduce three key concepts. 1) Using edge features to directly capture the spatiotemporal flow representation among regions. 2) Applying an edge attention mechanism to GCN to extract the AAM from the edge features. Here, the attention mechanism can effectively determine important spatio-temporal adjacency relations. 3) Proposing a novel node contrastive loss to suppress obstructed connections and emphasize related connections. Experimental results show that ESGCN achieves state-of-the-art performance by a large margin on four real-world datasets (PEMS03, 04, 07, and 08) with a low computational cost.
Decompose, Adjust, Compose: Effective Normalization by Playing with Frequency for Domain Generalization
Mar 15, 2023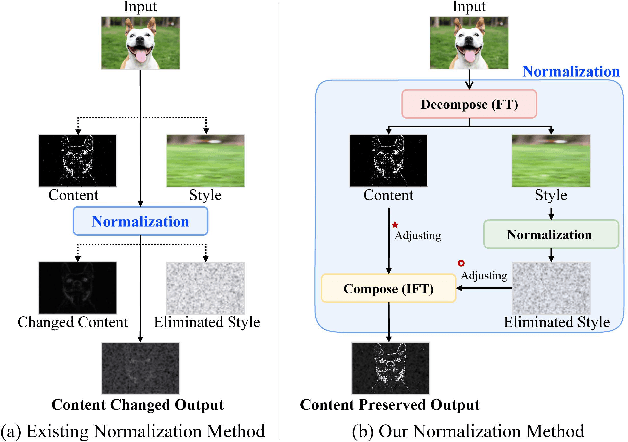



Domain generalization (DG) is a principal task to evaluate the robustness of computer vision models. Many previous studies have used normalization for DG. In normalization, statistics and normalized features are regarded as style and content, respectively. However, it has a content variation problem when removing style because the boundary between content and style is unclear. This study addresses this problem from the frequency domain perspective, where amplitude and phase are considered as style and content, respectively. First, we verify the quantitative phase variation of normalization through the mathematical derivation of the Fourier transform formula. Then, based on this, we propose a novel normalization method, PCNorm, which eliminates style only as the preserving content through spectral decomposition. Furthermore, we propose advanced PCNorm variants, CCNorm and SCNorm, which adjust the degrees of variations in content and style, respectively. Thus, they can learn domain-agnostic representations for DG. With the normalization methods, we propose ResNet-variant models, DAC-P and DAC-SC, which are robust to the domain gap. The proposed models outperform other recent DG methods. The DAC-SC achieves an average state-of-the-art performance of 65.6% on five datasets: PACS, VLCS, Office-Home, DomainNet, and TerraIncognita.
SoccerNet 2022 Challenges Results
Oct 05, 2022



The SoccerNet 2022 challenges were the second annual video understanding challenges organized by the SoccerNet team. In 2022, the challenges were composed of 6 vision-based tasks: (1) action spotting, focusing on retrieving action timestamps in long untrimmed videos, (2) replay grounding, focusing on retrieving the live moment of an action shown in a replay, (3) pitch localization, focusing on detecting line and goal part elements, (4) camera calibration, dedicated to retrieving the intrinsic and extrinsic camera parameters, (5) player re-identification, focusing on retrieving the same players across multiple views, and (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams. Compared to last year's challenges, tasks (1-2) had their evaluation metrics redefined to consider tighter temporal accuracies, and tasks (3-6) were novel, including their underlying data and annotations. More information on the tasks, challenges and leaderboards are available on https://www.soccer-net.org. Baselines and development kits are available on https://github.com/SoccerNet.
SBNet: Segmentation-based Network for Natural Language-based Vehicle Search
Apr 22, 2021

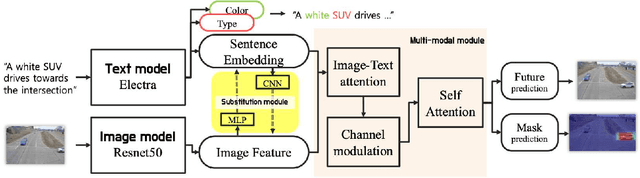
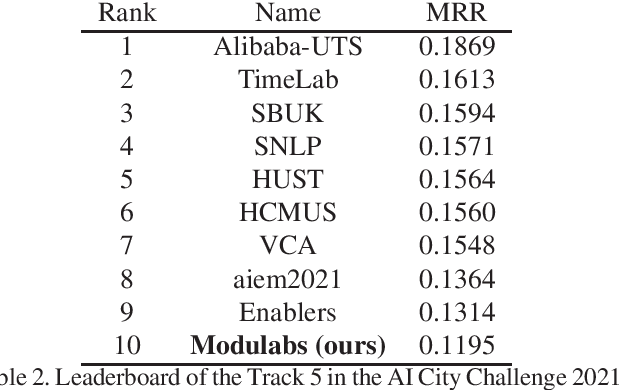
Natural language-based vehicle retrieval is a task to find a target vehicle within a given image based on a natural language description as a query. This technology can be applied to various areas including police searching for a suspect vehicle. However, it is challenging due to the ambiguity of language descriptions and the difficulty of processing multi-modal data. To tackle this problem, we propose a deep neural network called SBNet that performs natural language-based segmentation for vehicle retrieval. We also propose two task-specific modules to improve performance: a substitution module that helps features from different domains to be embedded in the same space and a future prediction module that learns temporal information. SBnet has been trained using the CityFlow-NL dataset that contains 2,498 tracks of vehicles with three unique natural language descriptions each and tested 530 unique vehicle tracks and their corresponding query sets. SBNet achieved a significant improvement over the baseline in the natural language-based vehicle tracking track in the AI City Challenge 2021.
Multi-Attention-Based Soft Partition Network for Vehicle Re-Identification
Apr 21, 2021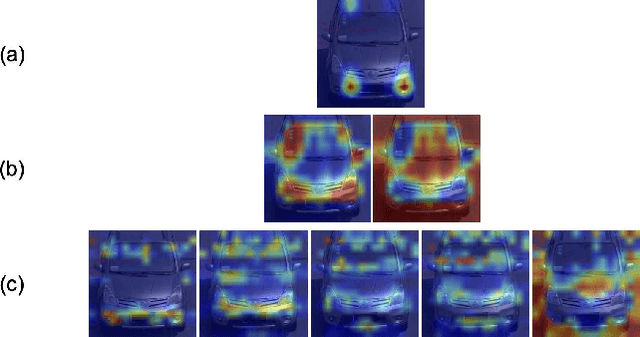
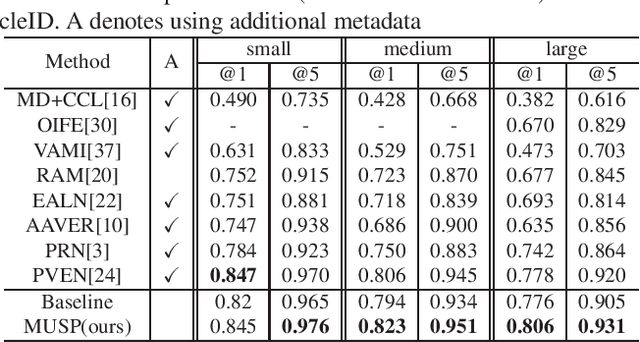
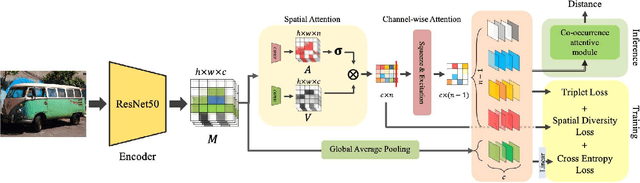

Vehicle re-identification (Re-ID) distinguishes between the same vehicle and other vehicles in images. It is challenging due to significant intra-instance differences between identical vehicles from different views and subtle inter-instance differences of similar vehicles. Researchers have tried to address this problem by extracting features robust to variations of viewpoints and environments. More recently, they tried to improve performance by using additional metadata such as key points, orientation, and temporal information. Although these attempts have been relatively successful, they all require expensive annotations. Therefore, this paper proposes a novel deep neural network called a multi-attention-based soft partition (MUSP) network to solve this problem. This network does not use metadata and only uses multiple soft attentions to identify a specific vehicle area. This function was performed by metadata in previous studies. Experiments verified that MUSP achieved state-of-the-art (SOTA) performance for the VehicleID dataset without any additional annotations and was comparable to VeRi-776 and VERI-Wild.
StRDAN: Synthetic-to-Real Domain Adaptation Network for Vehicle Re-Identification
Apr 25, 2020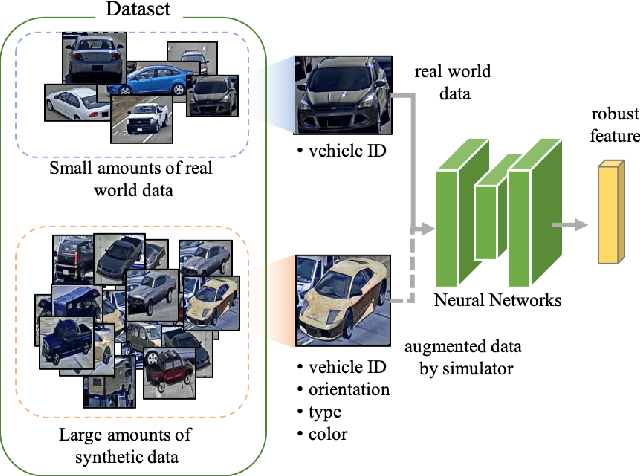
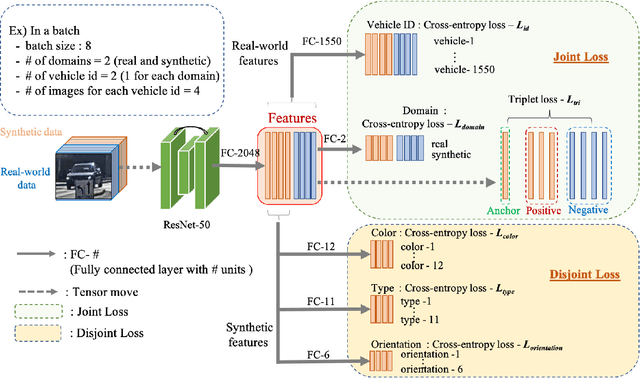
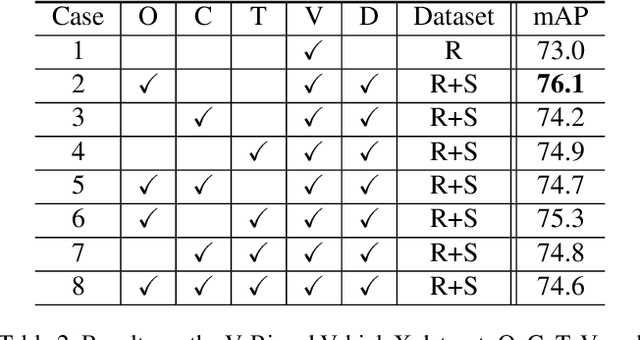
Vehicle re-identification aims to obtain the same vehicles from vehicle images. It is challenging but essential for analyzing and predicting traffic flow in the city. Although deep learning methods have achieved enormous progress in this task, requiring a large amount of data is a critical shortcoming. To tackle this problem, we propose a novel framework called Synthetic-to-Real Domain Adaptation Network (StRDAN), which is trained with inexpensive large-scale synthetic data as well as real data to improve performance. The training method for StRDAN is combined with domain adaptation and semi-supervised learning methods and their associated losses. StRDAN shows a significant improvement over the baseline model, which is trained using only real data, in two main datasets: VeRi and CityFlow-ReID. Evaluating with the mean average precision (mAP) metric, our model outperforms the reference model by 12.87% in CityFlow-ReID and 3.1% in VeRi.
An Energy and GPU-Computation Efficient Backbone Network for Real-Time Object Detection
Apr 22, 2019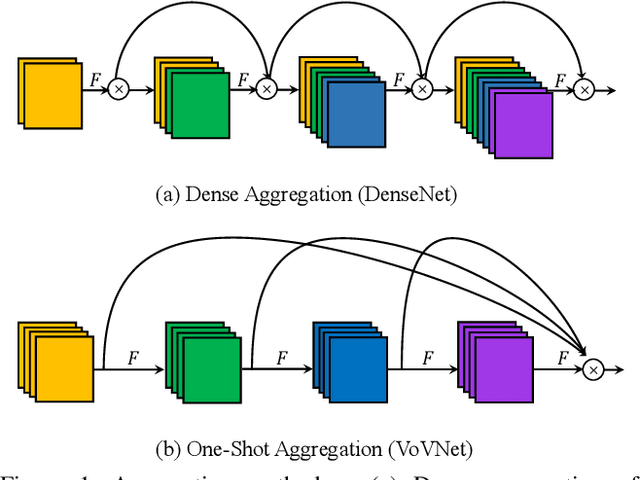
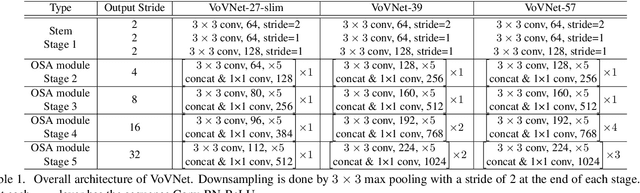
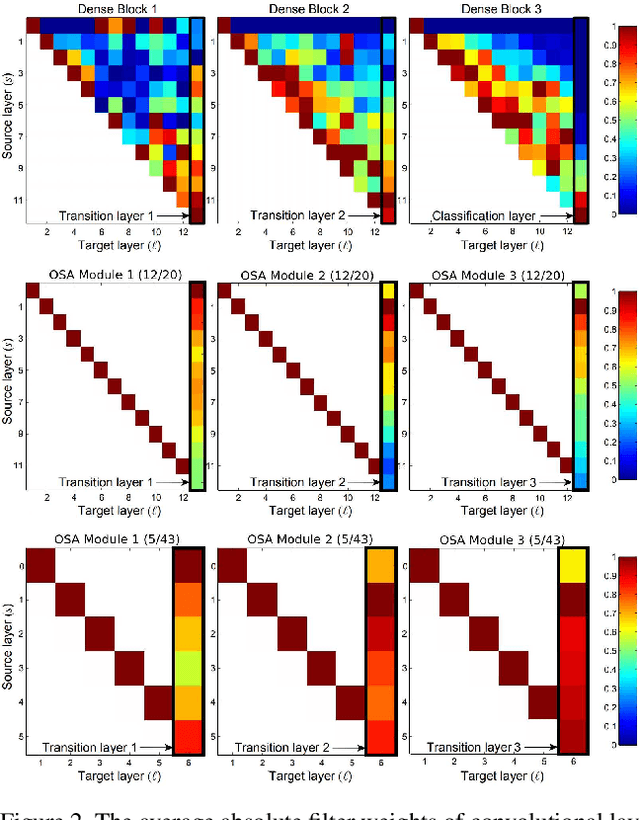
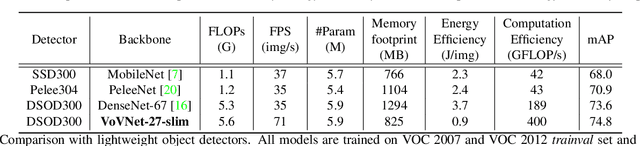
As DenseNet conserves intermediate features with diverse receptive fields by aggregating them with dense connection, it shows good performance on the object detection task. Although feature reuse enables DenseNet to produce strong features with a small number of model parameters and FLOPs, the detector with DenseNet backbone shows rather slow speed and low energy efficiency. We find the linearly increasing input channel by dense connection leads to heavy memory access cost, which causes computation overhead and more energy consumption. To solve the inefficiency of DenseNet, we propose an energy and computation efficient architecture called VoVNet comprised of One-Shot Aggregation (OSA). The OSA not only adopts the strength of DenseNet that represents diversified features with multi receptive fields but also overcomes the inefficiency of dense connection by aggregating all features only once in the last feature maps. To validate the effectiveness of VoVNet as a backbone network, we design both lightweight and large-scale VoVNet and apply them to one-stage and two-stage object detectors. Our VoVNet based detectors outperform DenseNet based ones with 2x faster speed and the energy consumptions are reduced by 1.6x - 4.1x. In addition to DenseNet, VoVNet also outperforms widely used ResNet backbone with faster speed and better energy efficiency. In particular, the small object detection performance has been significantly improved over DenseNet and ResNet.