 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFalse Positive Sampling-based Data Augmentation for Enhanced 3D Object Detection Accuracy
Mar 07, 2024Recent studies have focused on enhancing the performance of 3D object detection models. Among various approaches, ground-truth sampling has been proposed as an augmentation technique to address the challenges posed by limited ground-truth data. However, an inherent issue with ground-truth sampling is its tendency to increase false positives. Therefore, this study aims to overcome the limitations of ground-truth sampling and improve the performance of 3D object detection models by developing a new augmentation technique called false-positive sampling. False-positive sampling involves retraining the model using point clouds that are identified as false positives in the model's predictions. We propose an algorithm that utilizes both ground-truth and false-positive sampling and an algorithm for building the false-positive sample database. Additionally, we analyze the principles behind the performance enhancement due to false-positive sampling and propose a technique that applies the concept of curriculum learning to the sampling strategy that encompasses both false-positive and ground-truth sampling techniques. Our experiments demonstrate that models utilizing false-positive sampling show a reduction in false positives and exhibit improved object detection performance. On the KITTI and Waymo Open datasets, models with false-positive sampling surpass the baseline models by a large margin.
SBNet: Segmentation-based Network for Natural Language-based Vehicle Search
Apr 22, 2021

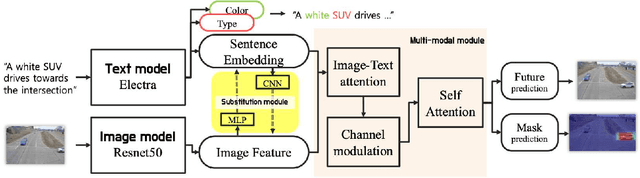
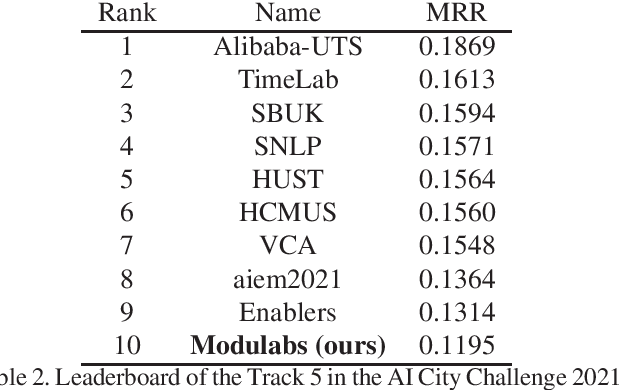
Natural language-based vehicle retrieval is a task to find a target vehicle within a given image based on a natural language description as a query. This technology can be applied to various areas including police searching for a suspect vehicle. However, it is challenging due to the ambiguity of language descriptions and the difficulty of processing multi-modal data. To tackle this problem, we propose a deep neural network called SBNet that performs natural language-based segmentation for vehicle retrieval. We also propose two task-specific modules to improve performance: a substitution module that helps features from different domains to be embedded in the same space and a future prediction module that learns temporal information. SBnet has been trained using the CityFlow-NL dataset that contains 2,498 tracks of vehicles with three unique natural language descriptions each and tested 530 unique vehicle tracks and their corresponding query sets. SBNet achieved a significant improvement over the baseline in the natural language-based vehicle tracking track in the AI City Challenge 2021.
Multi-Attention-Based Soft Partition Network for Vehicle Re-Identification
Apr 21, 2021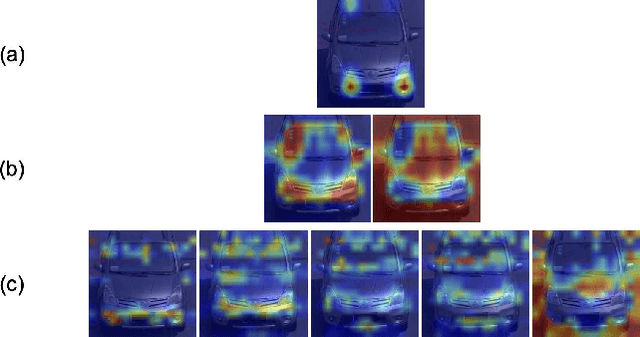
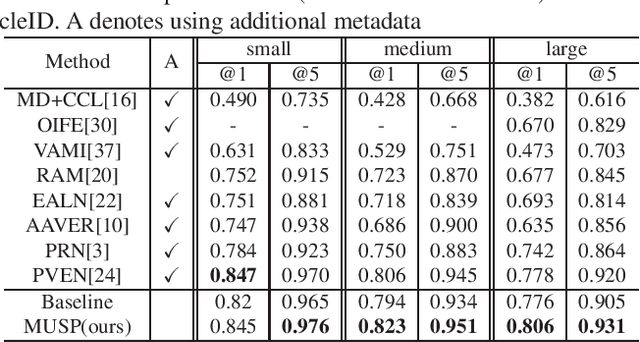
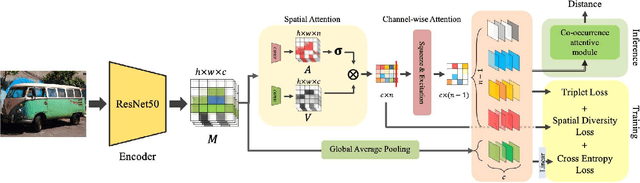

Vehicle re-identification (Re-ID) distinguishes between the same vehicle and other vehicles in images. It is challenging due to significant intra-instance differences between identical vehicles from different views and subtle inter-instance differences of similar vehicles. Researchers have tried to address this problem by extracting features robust to variations of viewpoints and environments. More recently, they tried to improve performance by using additional metadata such as key points, orientation, and temporal information. Although these attempts have been relatively successful, they all require expensive annotations. Therefore, this paper proposes a novel deep neural network called a multi-attention-based soft partition (MUSP) network to solve this problem. This network does not use metadata and only uses multiple soft attentions to identify a specific vehicle area. This function was performed by metadata in previous studies. Experiments verified that MUSP achieved state-of-the-art (SOTA) performance for the VehicleID dataset without any additional annotations and was comparable to VeRi-776 and VERI-Wild.
StRDAN: Synthetic-to-Real Domain Adaptation Network for Vehicle Re-Identification
Apr 25, 2020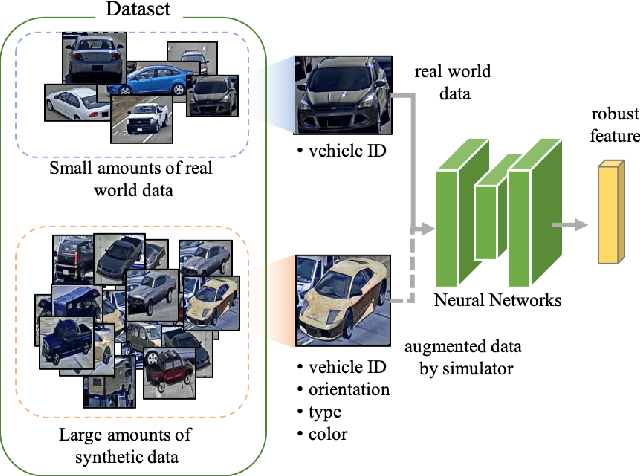
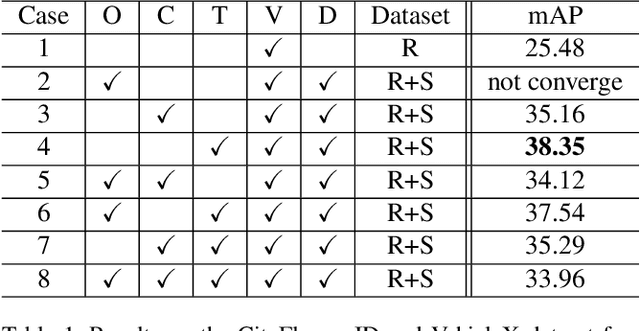
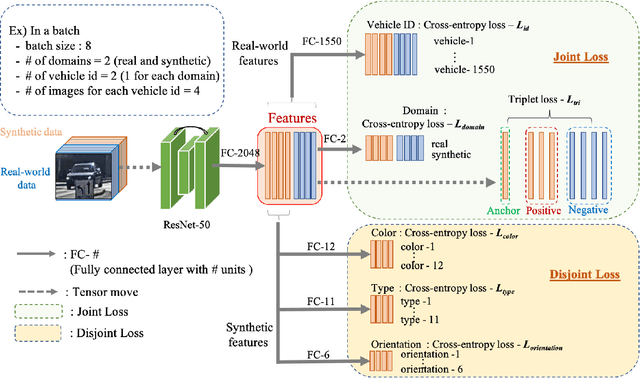
Vehicle re-identification aims to obtain the same vehicles from vehicle images. It is challenging but essential for analyzing and predicting traffic flow in the city. Although deep learning methods have achieved enormous progress in this task, requiring a large amount of data is a critical shortcoming. To tackle this problem, we propose a novel framework called Synthetic-to-Real Domain Adaptation Network (StRDAN), which is trained with inexpensive large-scale synthetic data as well as real data to improve performance. The training method for StRDAN is combined with domain adaptation and semi-supervised learning methods and their associated losses. StRDAN shows a significant improvement over the baseline model, which is trained using only real data, in two main datasets: VeRi and CityFlow-ReID. Evaluating with the mean average precision (mAP) metric, our model outperforms the reference model by 12.87% in CityFlow-ReID and 3.1% in VeRi.