 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultihopSpatial: Multi-hop Compositional Spatial Reasoning Benchmark for Vision-Language Model
Mar 19, 2026Spatial reasoning is foundational for Vision-Language Models (VLMs), particularly when deployed as Vision-Language-Action (VLA) agents in physical environments. However, existing benchmarks predominantly focus on elementary, single-hop relations, neglecting the multi-hop compositional reasoning and precise visual grounding essential for real-world scenarios. To address this, we introduce MultihopSpatial, offering three key contributions: (1) A comprehensive benchmark designed for multi-hop and compositional spatial reasoning, featuring 1- to 3-hop complex queries across diverse spatial perspectives. (2) Acc@50IoU, a complementary metric that simultaneously evaluates reasoning and visual grounding by requiring both answer selection and precise bounding box prediction - capabilities vital for robust VLA deployment. (3) MultihopSpatial-Train, a dedicated large-scale training corpus to foster spatial intelligence. Extensive evaluation of 37 state-of-the-art VLMs yields eight key insights, revealing that compositional spatial reasoning remains a formidable challenge. Finally, we demonstrate that reinforcement learning post-training on our corpus enhances both intrinsic VLM spatial reasoning and downstream embodied manipulation performance.
MA-EgoQA: Question Answering over Egocentric Videos from Multiple Embodied Agents
Mar 11, 2026As embodied models become powerful, humans will collaborate with multiple embodied AI agents at their workplace or home in the future. To ensure better communication between human users and the multi-agent system, it is crucial to interpret incoming information from agents in parallel and refer to the appropriate context for each query. Existing challenges include effectively compressing and communicating high volumes of individual sensory inputs in the form of video and correctly aggregating multiple egocentric videos to construct system-level memory. In this work, we first formally define a novel problem of understanding multiple long-horizon egocentric videos simultaneously collected from embodied agents. To facilitate research in this direction, we introduce MultiAgent-EgoQA (MA-EgoQA), a benchmark designed to systemically evaluate existing models in our scenario. MA-EgoQA provides 1.7k questions unique to multiple egocentric streams, spanning five categories: social interaction, task coordination, theory-of-mind, temporal reasoning, and environmental interaction. We further propose a simple baseline model for MA-EgoQA named EgoMAS, which leverages shared memory across embodied agents and agent-wise dynamic retrieval. Through comprehensive evaluation across diverse baselines and EgoMAS on MA-EgoQA, we find that current approaches are unable to effectively handle multiple egocentric streams, highlighting the need for future advances in system-level understanding across the agents. The code and benchmark are available at https://ma-egoqa.github.io.
HoliSafe: Holistic Safety Benchmarking and Modeling with Safety Meta Token for Vision-Language Model
Jun 05, 2025Despite emerging efforts to enhance the safety of Vision-Language Models (VLMs), current approaches face two main shortcomings. 1) Existing safety-tuning datasets and benchmarks only partially consider how image-text interactions can yield harmful content, often overlooking contextually unsafe outcomes from seemingly benign pairs. This narrow coverage leaves VLMs vulnerable to jailbreak attacks in unseen configurations. 2) Prior methods rely primarily on data-centric tuning, with limited architectural innovations to intrinsically strengthen safety. We address these gaps by introducing a holistic safety dataset and benchmark, HoliSafe, that spans all five safe/unsafe image-text combinations, providing a more robust basis for both training and evaluation. We further propose SafeLLaVA, a novel VLM augmented with a learnable safety meta token and a dedicated safety head. The meta token encodes harmful visual cues during training, intrinsically guiding the language model toward safer responses, while the safety head offers interpretable harmfulness classification aligned with refusal rationales. Experiments show that SafeLLaVA, trained on HoliSafe, achieves state-of-the-art safety performance across multiple VLM benchmarks. Additionally, the HoliSafe benchmark itself reveals critical vulnerabilities in existing models. We hope that HoliSafe and SafeLLaVA will spur further research into robust and interpretable VLM safety, expanding future avenues for multimodal alignment.
VideoICL: Confidence-based Iterative In-context Learning for Out-of-Distribution Video Understanding
Dec 03, 2024
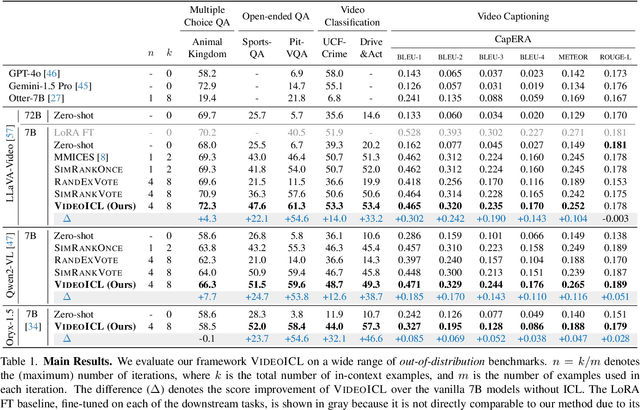


Recent advancements in video large multimodal models (LMMs) have significantly improved their video understanding and reasoning capabilities. However, their performance drops on out-of-distribution (OOD) tasks that are underrepresented in training data. Traditional methods like fine-tuning on OOD datasets are impractical due to high computational costs. While In-context learning (ICL) with demonstration examples has shown promising generalization performance in language tasks and image-language tasks without fine-tuning, applying ICL to video-language tasks faces challenges due to the limited context length in Video LMMs, as videos require longer token lengths. To address these issues, we propose VideoICL, a novel video in-context learning framework for OOD tasks that introduces a similarity-based relevant example selection strategy and a confidence-based iterative inference approach. This allows to select the most relevant examples and rank them based on similarity, to be used for inference. If the generated response has low confidence, our framework selects new examples and performs inference again, iteratively refining the results until a high-confidence response is obtained. This approach improves OOD video understanding performance by extending effective context length without incurring high costs. The experimental results on multiple benchmarks demonstrate significant performance gains, especially in domain-specific scenarios, laying the groundwork for broader video comprehension applications. Code will be released at https://github.com/KangsanKim07/VideoICL
Training-Free Exponential Extension of Sliding Window Context with Cascading KV Cache
Jun 24, 2024
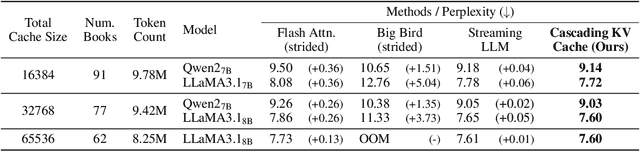


The context window within a transformer provides a form of active memory for the current task, which can be useful for few-shot learning and conditional generation, both which depend heavily on previous context tokens. However, as the context length grows, the computational cost increases quadratically. Recent works have shown that saving a few initial tokens along with a fixed-sized sliding window leads to stable streaming generation with linear complexity in transformer-based Large Language Models (LLMs). However, they make suboptimal use of the fixed window by naively evicting all tokens unconditionally from the key-value (KV) cache once they reach the end of the window, resulting in tokens being forgotten and no longer able to affect subsequent predictions. To overcome this limitation, we propose a novel mechanism for storing longer sliding window contexts with the same total cache size by keeping separate cascading sub-cache buffers whereby each subsequent buffer conditionally accepts a fraction of the relatively more important tokens evicted from the previous buffer. Our method results in a dynamic KV cache that can store tokens from the more distant past than a fixed, static sliding window approach. Our experiments show improvements of 5.6% on long context generation (LongBench), 1.2% in streaming perplexity (PG19), and 0.6% in language understanding (MMLU STEM) using LLMs given the same fixed cache size. Additionally, we provide an efficient implementation that improves the KV cache latency from 1.33ms per caching operation to 0.54ms, a 59% speedup over previous work.
HiP Attention: Sparse Sub-Quadratic Attention with Hierarchical Attention Pruning
Jun 14, 2024In modern large language models (LLMs), increasing sequence lengths is a crucial challenge for enhancing their comprehension and coherence in handling complex tasks such as multi-modal question answering. However, handling long context sequences with LLMs is prohibitively costly due to the conventional attention mechanism's quadratic time and space complexity, and the context window size is limited by the GPU memory. Although recent works have proposed linear and sparse attention mechanisms to address this issue, their real-world applicability is often limited by the need to re-train pre-trained models. In response, we propose a novel approach, Hierarchically Pruned Attention (HiP), which simultaneously reduces the training and inference time complexity from $O(T^2)$ to $O(T \log T)$ and the space complexity from $O(T^2)$ to $O(T)$. To this end, we devise a dynamic sparse attention mechanism that generates an attention mask through a novel tree-search-like algorithm for a given query on the fly. HiP is training-free as it only utilizes the pre-trained attention scores to spot the positions of the top-$k$ most significant elements for each query. Moreover, it ensures that no token is overlooked, unlike the sliding window-based sub-quadratic attention methods, such as StreamingLLM. Extensive experiments on diverse real-world benchmarks demonstrate that HiP significantly reduces prompt (i.e., prefill) and decoding latency and memory usage while maintaining high generation performance with little or no degradation. As HiP allows pretrained LLMs to scale to millions of tokens on commodity GPUs with no additional engineering due to its easy plug-and-play deployment, we believe that our work will have a large practical impact, opening up the possibility to many long-context LLM applications previously infeasible.
PC-LoRA: Low-Rank Adaptation for Progressive Model Compression with Knowledge Distillation
Jun 13, 2024Low-rank adaption (LoRA) is a prominent method that adds a small number of learnable parameters to the frozen pre-trained weights for parameter-efficient fine-tuning. Prompted by the question, ``Can we make its representation enough with LoRA weights solely at the final phase of finetuning without the pre-trained weights?'' In this work, we introduce Progressive Compression LoRA~(PC-LoRA), which utilizes low-rank adaptation (LoRA) to simultaneously perform model compression and fine-tuning. The PC-LoRA method gradually removes the pre-trained weights during the training process, eventually leaving only the low-rank adapters in the end. Thus, these low-rank adapters replace the whole pre-trained weights, achieving the goals of compression and fine-tuning at the same time. Empirical analysis across various models demonstrates that PC-LoRA achieves parameter and FLOPs compression rates of 94.36%/89.1% for vision models, e.g., ViT-B, and 93.42%/84.2% parameters and FLOPs compressions for language models, e.g., BERT.
Visualizing the loss landscape of Self-supervised Vision Transformer
May 28, 2024

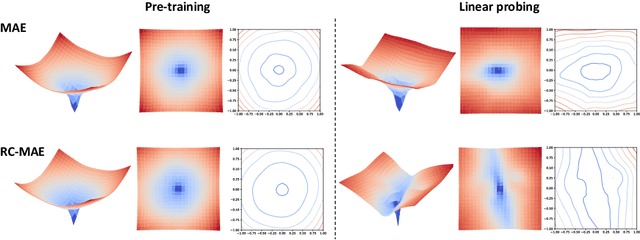
The Masked autoencoder (MAE) has drawn attention as a representative self-supervised approach for masked image modeling with vision transformers. However, even though MAE shows better generalization capability than fully supervised training from scratch, the reason why has not been explored. In another line of work, the Reconstruction Consistent Masked Auto Encoder (RC-MAE), has been proposed which adopts a self-distillation scheme in the form of an exponential moving average (EMA) teacher into MAE, and it has been shown that the EMA-teacher performs a conditional gradient correction during optimization. To further investigate the reason for better generalization of the self-supervised ViT when trained by MAE (MAE-ViT) and the effect of the gradient correction of RC-MAE from the perspective of optimization, we visualize the loss landscapes of the self-supervised vision transformer by both MAE and RC-MAE and compare them with the supervised ViT (Sup-ViT). Unlike previous loss landscape visualizations of neural networks based on classification task loss, we visualize the loss landscape of ViT by computing pre-training task loss. Through the lens of loss landscapes, we find two interesting observations: (1) MAE-ViT has a smoother and wider overall loss curvature than Sup-ViT. (2) The EMA-teacher allows MAE to widen the region of convexity in both pretraining and linear probing, leading to quicker convergence. To the best of our knowledge, this work is the first to investigate the self-supervised ViT through the lens of the loss landscape.
Dynamic and Super-Personalized Media Ecosystem Driven by Generative AI: Unpredictable Plays Never Repeating The Same
Feb 19, 2024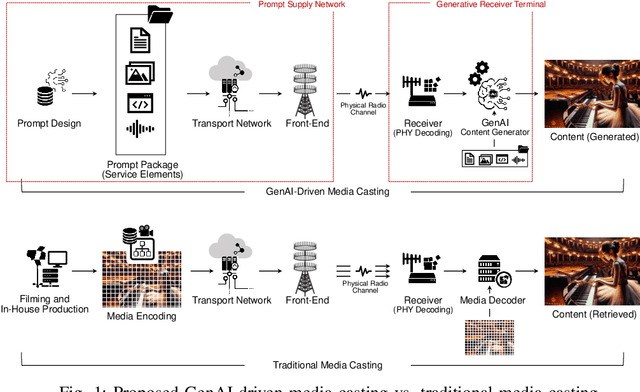

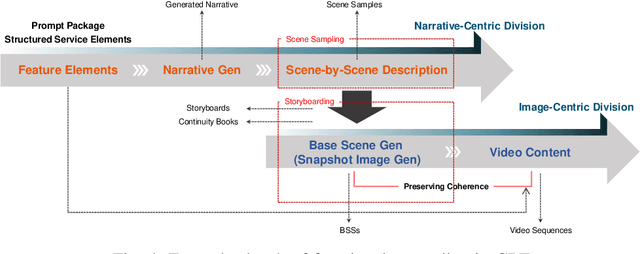
This paper introduces a media service model that exploits artificial intelligence (AI) video generators at the receive end. This proposal deviates from the traditional multimedia ecosystem, completely relying on in-house production, by shifting part of the content creation onto the receiver. We bring a semantic process into the framework, allowing the distribution network to provide service elements that prompt the content generator, rather than distributing encoded data of fully finished programs. The service elements include fine-tailored text descriptions, lightweight image data of some objects, or application programming interfaces, comprehensively referred to as semantic sources, and the user terminal translates the received semantic data into video frames. Empowered by the random nature of generative AI, the users could then experience super-personalized services accordingly. The proposed idea incorporates the situations in which the user receives different service providers' element packages; a sequence of packages over time, or multiple packages at the same time. Given promised in-context coherence and content integrity, the combinatory dynamics will amplify the service diversity, allowing the users to always chance upon new experiences. This work particularly aims at short-form videos and advertisements, which the users would easily feel fatigued by seeing the same frame sequence every time. In those use cases, the content provider's role will be recast as scripting semantic sources, transformed from a thorough producer. Overall, this work explores a new form of media ecosystem facilitated by receiver-embedded generative models, featuring both random content dynamics and enhanced delivery efficiency simultaneously.
KOALA: Self-Attention Matters in Knowledge Distillation of Latent Diffusion Models for Memory-Efficient and Fast Image Synthesis
Dec 07, 2023



Stable diffusion is the mainstay of the text-to-image (T2I) synthesis in the community due to its generation performance and open-source nature. Recently, Stable Diffusion XL (SDXL), the successor of stable diffusion, has received a lot of attention due to its significant performance improvements with a higher resolution of 1024x1024 and a larger model. However, its increased computation cost and model size require higher-end hardware(e.g., bigger VRAM GPU) for end-users, incurring higher costs of operation. To address this problem, in this work, we propose an efficient latent diffusion model for text-to-image synthesis obtained by distilling the knowledge of SDXL. To this end, we first perform an in-depth analysis of the denoising U-Net in SDXL, which is the main bottleneck of the model, and then design a more efficient U-Net based on the analysis. Secondly, we explore how to effectively distill the generation capability of SDXL into an efficient U-Net and eventually identify four essential factors, the core of which is that self-attention is the most important part. With our efficient U-Net and self-attention-based knowledge distillation strategy, we build our efficient T2I models, called KOALA-1B & -700M, while reducing the model size up to 54% and 69% of the original SDXL model. In particular, the KOALA-700M is more than twice as fast as SDXL while still retaining a decent generation quality. We hope that due to its balanced speed-performance tradeoff, our KOALA models can serve as a cost-effective alternative to SDXL in resource-constrained environments.