 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMA-EgoQA: Question Answering over Egocentric Videos from Multiple Embodied Agents
Mar 11, 2026As embodied models become powerful, humans will collaborate with multiple embodied AI agents at their workplace or home in the future. To ensure better communication between human users and the multi-agent system, it is crucial to interpret incoming information from agents in parallel and refer to the appropriate context for each query. Existing challenges include effectively compressing and communicating high volumes of individual sensory inputs in the form of video and correctly aggregating multiple egocentric videos to construct system-level memory. In this work, we first formally define a novel problem of understanding multiple long-horizon egocentric videos simultaneously collected from embodied agents. To facilitate research in this direction, we introduce MultiAgent-EgoQA (MA-EgoQA), a benchmark designed to systemically evaluate existing models in our scenario. MA-EgoQA provides 1.7k questions unique to multiple egocentric streams, spanning five categories: social interaction, task coordination, theory-of-mind, temporal reasoning, and environmental interaction. We further propose a simple baseline model for MA-EgoQA named EgoMAS, which leverages shared memory across embodied agents and agent-wise dynamic retrieval. Through comprehensive evaluation across diverse baselines and EgoMAS on MA-EgoQA, we find that current approaches are unable to effectively handle multiple egocentric streams, highlighting the need for future advances in system-level understanding across the agents. The code and benchmark are available at https://ma-egoqa.github.io.
HoliSafe: Holistic Safety Benchmarking and Modeling with Safety Meta Token for Vision-Language Model
Jun 05, 2025Despite emerging efforts to enhance the safety of Vision-Language Models (VLMs), current approaches face two main shortcomings. 1) Existing safety-tuning datasets and benchmarks only partially consider how image-text interactions can yield harmful content, often overlooking contextually unsafe outcomes from seemingly benign pairs. This narrow coverage leaves VLMs vulnerable to jailbreak attacks in unseen configurations. 2) Prior methods rely primarily on data-centric tuning, with limited architectural innovations to intrinsically strengthen safety. We address these gaps by introducing a holistic safety dataset and benchmark, HoliSafe, that spans all five safe/unsafe image-text combinations, providing a more robust basis for both training and evaluation. We further propose SafeLLaVA, a novel VLM augmented with a learnable safety meta token and a dedicated safety head. The meta token encodes harmful visual cues during training, intrinsically guiding the language model toward safer responses, while the safety head offers interpretable harmfulness classification aligned with refusal rationales. Experiments show that SafeLLaVA, trained on HoliSafe, achieves state-of-the-art safety performance across multiple VLM benchmarks. Additionally, the HoliSafe benchmark itself reveals critical vulnerabilities in existing models. We hope that HoliSafe and SafeLLaVA will spur further research into robust and interpretable VLM safety, expanding future avenues for multimodal alignment.
UniversalRAG: Retrieval-Augmented Generation over Multiple Corpora with Diverse Modalities and Granularities
Apr 29, 2025



Retrieval-Augmented Generation (RAG) has shown substantial promise in improving factual accuracy by grounding model responses with external knowledge relevant to queries. However, most existing RAG approaches are limited to a text-only corpus, and while recent efforts have extended RAG to other modalities such as images and videos, they typically operate over a single modality-specific corpus. In contrast, real-world queries vary widely in the type of knowledge they require, which a single type of knowledge source cannot address. To address this, we introduce UniversalRAG, a novel RAG framework designed to retrieve and integrate knowledge from heterogeneous sources with diverse modalities and granularities. Specifically, motivated by the observation that forcing all modalities into a unified representation space derived from a single combined corpus causes a modality gap, where the retrieval tends to favor items from the same modality as the query, we propose a modality-aware routing mechanism that dynamically identifies the most appropriate modality-specific corpus and performs targeted retrieval within it. Also, beyond modality, we organize each modality into multiple granularity levels, enabling fine-tuned retrieval tailored to the complexity and scope of the query. We validate UniversalRAG on 8 benchmarks spanning multiple modalities, showing its superiority over modality-specific and unified baselines.
VideoRAG: Retrieval-Augmented Generation over Video Corpus
Jan 10, 2025


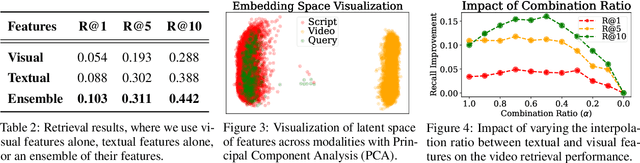
Retrieval-Augmented Generation (RAG) is a powerful strategy to address the issue of generating factually incorrect outputs in foundation models by retrieving external knowledge relevant to queries and incorporating it into their generation process. However, existing RAG approaches have primarily focused on textual information, with some recent advancements beginning to consider images, and they largely overlook videos, a rich source of multimodal knowledge capable of representing events, processes, and contextual details more effectively than any other modality. While a few recent studies explore the integration of videos in the response generation process, they either predefine query-associated videos without retrieving them according to queries, or convert videos into the textual descriptions without harnessing their multimodal richness. To tackle these, we introduce VideoRAG, a novel framework that not only dynamically retrieves relevant videos based on their relevance with queries but also utilizes both visual and textual information of videos in the output generation. Further, to operationalize this, our method revolves around the recent advance of Large Video Language Models (LVLMs), which enable the direct processing of video content to represent it for retrieval and seamless integration of the retrieved videos jointly with queries. We experimentally validate the effectiveness of VideoRAG, showcasing that it is superior to relevant baselines.
VideoICL: Confidence-based Iterative In-context Learning for Out-of-Distribution Video Understanding
Dec 03, 2024
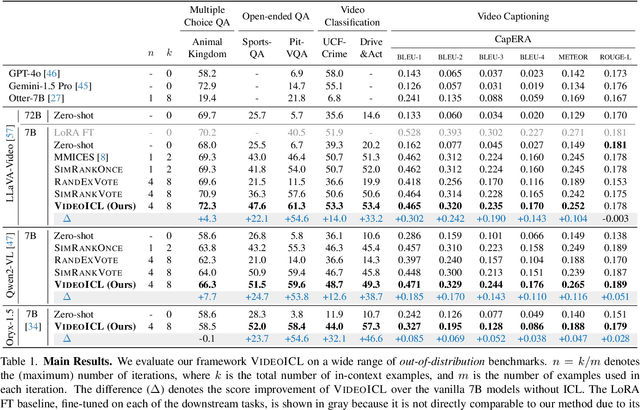


Recent advancements in video large multimodal models (LMMs) have significantly improved their video understanding and reasoning capabilities. However, their performance drops on out-of-distribution (OOD) tasks that are underrepresented in training data. Traditional methods like fine-tuning on OOD datasets are impractical due to high computational costs. While In-context learning (ICL) with demonstration examples has shown promising generalization performance in language tasks and image-language tasks without fine-tuning, applying ICL to video-language tasks faces challenges due to the limited context length in Video LMMs, as videos require longer token lengths. To address these issues, we propose VideoICL, a novel video in-context learning framework for OOD tasks that introduces a similarity-based relevant example selection strategy and a confidence-based iterative inference approach. This allows to select the most relevant examples and rank them based on similarity, to be used for inference. If the generated response has low confidence, our framework selects new examples and performs inference again, iteratively refining the results until a high-confidence response is obtained. This approach improves OOD video understanding performance by extending effective context length without incurring high costs. The experimental results on multiple benchmarks demonstrate significant performance gains, especially in domain-specific scenarios, laying the groundwork for broader video comprehension applications. Code will be released at https://github.com/KangsanKim07/VideoICL
BlendX: Complex Multi-Intent Detection with Blended Patterns
Mar 27, 2024


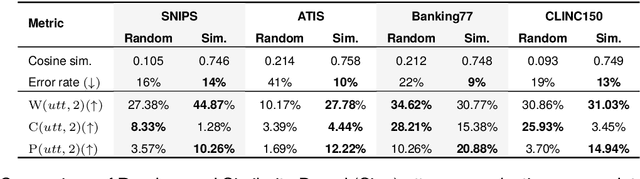
Task-oriented dialogue (TOD) systems are commonly designed with the presumption that each utterance represents a single intent. However, this assumption may not accurately reflect real-world situations, where users frequently express multiple intents within a single utterance. While there is an emerging interest in multi-intent detection (MID), existing in-domain datasets such as MixATIS and MixSNIPS have limitations in their formulation. To address these issues, we present BlendX, a suite of refined datasets featuring more diverse patterns than their predecessors, elevating both its complexity and diversity. For dataset construction, we utilize both rule-based heuristics as well as a generative tool -- OpenAI's ChatGPT -- which is augmented with a similarity-driven strategy for utterance selection. To ensure the quality of the proposed datasets, we also introduce three novel metrics that assess the statistical properties of an utterance related to word count, conjunction use, and pronoun usage. Extensive experiments on BlendX reveal that state-of-the-art MID models struggle with the challenges posed by the new datasets, highlighting the need to reexamine the current state of the MID field. The dataset is available at https://github.com/HYU-NLP/BlendX.