 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHoliSafe: Holistic Safety Benchmarking and Modeling with Safety Meta Token for Vision-Language Model
Jun 05, 2025Despite emerging efforts to enhance the safety of Vision-Language Models (VLMs), current approaches face two main shortcomings. 1) Existing safety-tuning datasets and benchmarks only partially consider how image-text interactions can yield harmful content, often overlooking contextually unsafe outcomes from seemingly benign pairs. This narrow coverage leaves VLMs vulnerable to jailbreak attacks in unseen configurations. 2) Prior methods rely primarily on data-centric tuning, with limited architectural innovations to intrinsically strengthen safety. We address these gaps by introducing a holistic safety dataset and benchmark, HoliSafe, that spans all five safe/unsafe image-text combinations, providing a more robust basis for both training and evaluation. We further propose SafeLLaVA, a novel VLM augmented with a learnable safety meta token and a dedicated safety head. The meta token encodes harmful visual cues during training, intrinsically guiding the language model toward safer responses, while the safety head offers interpretable harmfulness classification aligned with refusal rationales. Experiments show that SafeLLaVA, trained on HoliSafe, achieves state-of-the-art safety performance across multiple VLM benchmarks. Additionally, the HoliSafe benchmark itself reveals critical vulnerabilities in existing models. We hope that HoliSafe and SafeLLaVA will spur further research into robust and interpretable VLM safety, expanding future avenues for multimodal alignment.
KOALA: Self-Attention Matters in Knowledge Distillation of Latent Diffusion Models for Memory-Efficient and Fast Image Synthesis
Dec 07, 2023



Stable diffusion is the mainstay of the text-to-image (T2I) synthesis in the community due to its generation performance and open-source nature. Recently, Stable Diffusion XL (SDXL), the successor of stable diffusion, has received a lot of attention due to its significant performance improvements with a higher resolution of 1024x1024 and a larger model. However, its increased computation cost and model size require higher-end hardware(e.g., bigger VRAM GPU) for end-users, incurring higher costs of operation. To address this problem, in this work, we propose an efficient latent diffusion model for text-to-image synthesis obtained by distilling the knowledge of SDXL. To this end, we first perform an in-depth analysis of the denoising U-Net in SDXL, which is the main bottleneck of the model, and then design a more efficient U-Net based on the analysis. Secondly, we explore how to effectively distill the generation capability of SDXL into an efficient U-Net and eventually identify four essential factors, the core of which is that self-attention is the most important part. With our efficient U-Net and self-attention-based knowledge distillation strategy, we build our efficient T2I models, called KOALA-1B & -700M, while reducing the model size up to 54% and 69% of the original SDXL model. In particular, the KOALA-700M is more than twice as fast as SDXL while still retaining a decent generation quality. We hope that due to its balanced speed-performance tradeoff, our KOALA models can serve as a cost-effective alternative to SDXL in resource-constrained environments.
Precise Aerial Image Matching based on Deep Homography Estimation
Jul 19, 2021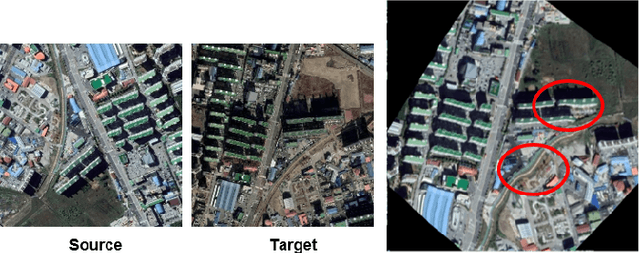

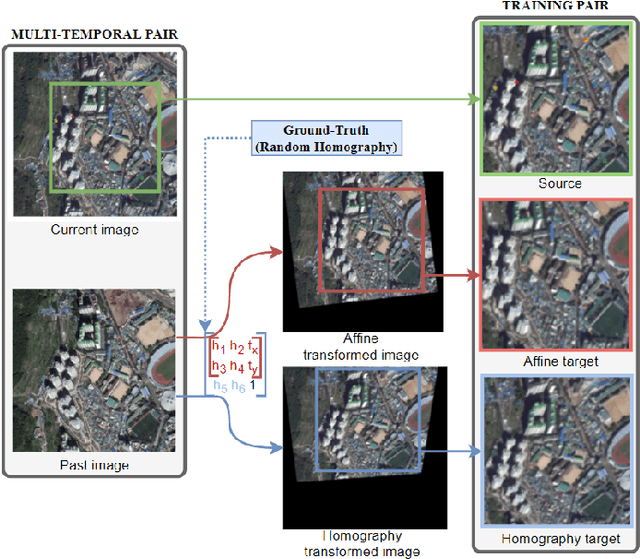

Aerial image registration or matching is a geometric process of aligning two aerial images captured in different environments. Estimating the precise transformation parameters is hindered by various environments such as time, weather, and viewpoints. The characteristics of the aerial images are mainly composed of a straight line owing to building and road. Therefore, the straight lines are distorted when estimating homography parameters directly between two images. In this paper, we propose a deep homography alignment network to precisely match two aerial images by progressively estimating the various transformation parameters. The proposed network is possible to train the matching network with a higher degree of freedom by progressively analyzing the transformation parameters. The precision matching performances have been increased by applying homography transformation. In addition, we introduce a method that can effectively learn the difficult-to-learn homography estimation network. Since there is no published learning data for aerial image registration, in this paper, a pair of images to which random homography transformation is applied within a certain range is used for learning. Hence, we could confirm that the deep homography alignment network shows high precision matching performance compared with conventional works.