 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Architecture Adaptation for Object Detection by Searching Channel Dimensions and Mapping Pre-trained Parameters
Jun 17, 2022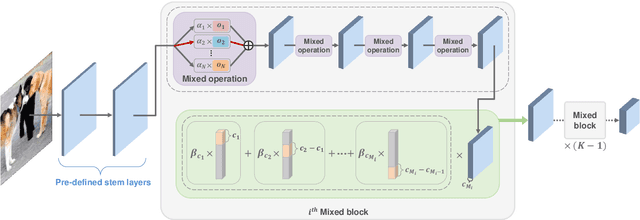

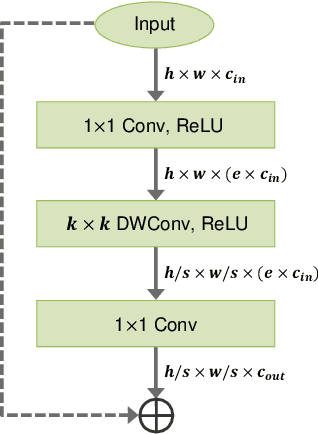

Most object detection frameworks use backbone architectures originally designed for image classification, conventionally with pre-trained parameters on ImageNet. However, image classification and object detection are essentially different tasks and there is no guarantee that the optimal backbone for classification is also optimal for object detection. Recent neural architecture search (NAS) research has demonstrated that automatically designing a backbone specifically for object detection helps improve the overall accuracy. In this paper, we introduce a neural architecture adaptation method that can optimize the given backbone for detection purposes, while still allowing the use of pre-trained parameters. We propose to adapt both the micro- and macro-architecture by searching for specific operations and the number of layers, in addition to the output channel dimensions of each block. It is important to find the optimal channel depth, as it greatly affects the feature representation capability and computation cost. We conduct experiments with our searched backbone for object detection and demonstrate that our backbone outperforms both manually designed and searched state-of-the-art backbones on the COCO dataset.
Precise Aerial Image Matching based on Deep Homography Estimation
Jul 19, 2021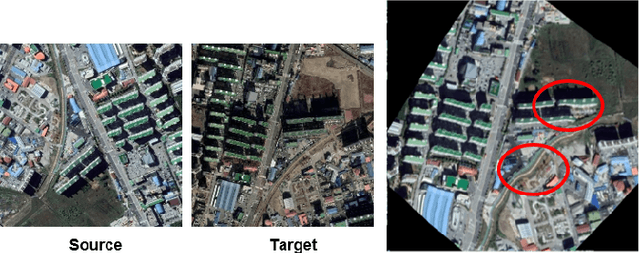

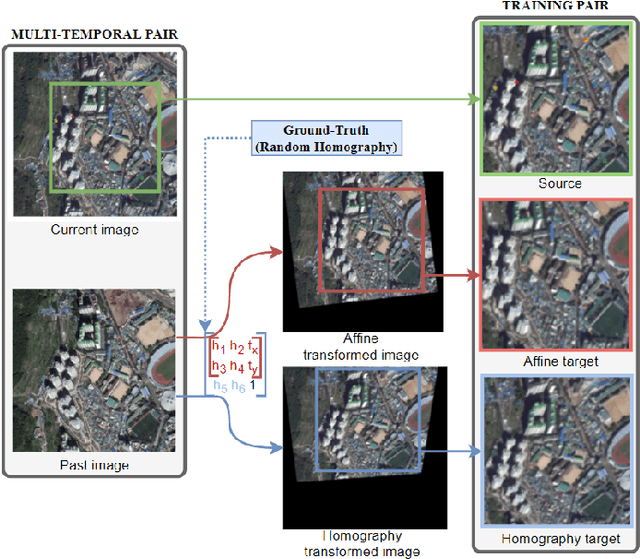

Aerial image registration or matching is a geometric process of aligning two aerial images captured in different environments. Estimating the precise transformation parameters is hindered by various environments such as time, weather, and viewpoints. The characteristics of the aerial images are mainly composed of a straight line owing to building and road. Therefore, the straight lines are distorted when estimating homography parameters directly between two images. In this paper, we propose a deep homography alignment network to precisely match two aerial images by progressively estimating the various transformation parameters. The proposed network is possible to train the matching network with a higher degree of freedom by progressively analyzing the transformation parameters. The precision matching performances have been increased by applying homography transformation. In addition, we introduce a method that can effectively learn the difficult-to-learn homography estimation network. Since there is no published learning data for aerial image registration, in this paper, a pair of images to which random homography transformation is applied within a certain range is used for learning. Hence, we could confirm that the deep homography alignment network shows high precision matching performance compared with conventional works.
Learning Free-Form Deformation for 3D Face Reconstruction from In-The-Wild Images
May 31, 2021


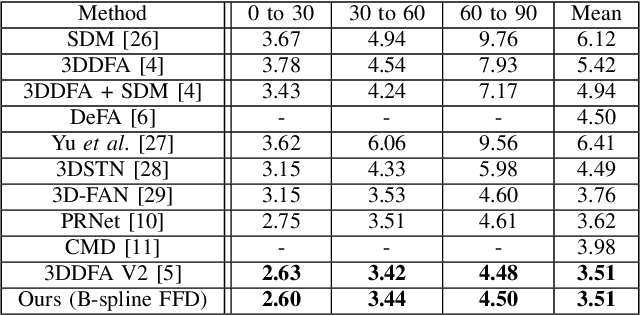
The 3D Morphable Model (3DMM), which is a Principal Component Analysis (PCA) based statistical model that represents a 3D face using linear basis functions, has shown promising results for reconstructing 3D faces from single-view in-the-wild images. However, 3DMM has restricted representation power due to the limited number of 3D scans and the global linear basis. To address the limitations of 3DMM, we propose a straightforward learning-based method that reconstructs a 3D face mesh through Free-Form Deformation (FFD) for the first time. FFD is a geometric modeling method that embeds a reference mesh within a parallelepiped grid and deforms the mesh by moving the sparse control points of the grid. As FFD is based on mathematically defined basis functions, it has no limitation in representation power. Thus, we can recover accurate 3D face meshes by estimating appropriate deviation of control points as deformation parameters. Although both 3DMM and FFD are parametric models, it is difficult to predict the effect of the 3DMM parameters on the face shape, while the deformation parameters of FFD are interpretable in terms of their effect on the final shape of the mesh. This practical advantage of FFD allows the resulting mesh and control points to serve as a good starting point for 3D face modeling, in that ordinary users can fine-tune the mesh by using widely available 3D software tools. Experiments on multiple datasets demonstrate how our method successfully estimates the 3D face geometry and facial expressions from 2D face images, achieving comparable performance to the state-of-the-art methods.