 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisually Dehallucinative Instruction Generation: Know What You Don't Know
Feb 15, 2024



"When did the emperor Napoleon invented iPhone?" Such hallucination-inducing question is well known challenge in generative language modeling. In this study, we present an innovative concept of visual hallucination, referred to as "I Know (IK)" hallucination, to address scenarios where "I Don't Know" is the desired response. To effectively tackle this issue, we propose the VQAv2-IDK benchmark, the subset of VQAv2 comprising unanswerable image-question pairs as determined by human annotators. Stepping further, we present the visually dehallucinative instruction generation method for IK hallucination and introduce the IDK-Instructions visual instruction database. Our experiments show that current methods struggle with IK hallucination. Yet, our approach effectively reduces these hallucinations, proving its versatility across different frameworks and datasets.
Visual Question Answering Instruction: Unlocking Multimodal Large Language Model To Domain-Specific Visual Multitasks
Feb 13, 2024
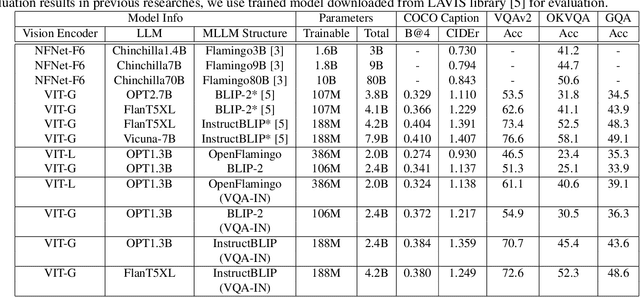

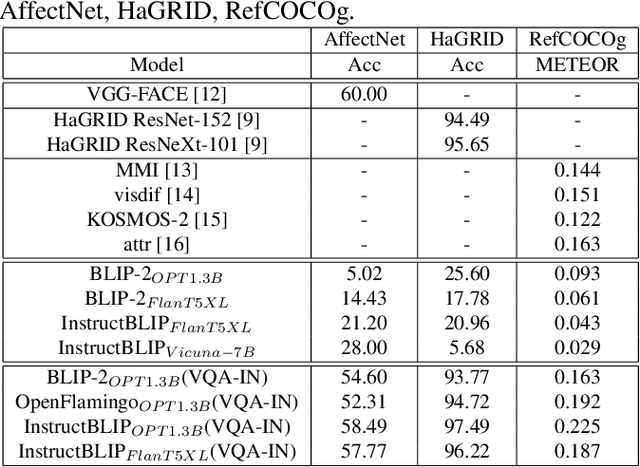
Having revolutionized natural language processing (NLP) applications, large language models (LLMs) are expanding into the realm of multimodal inputs. Owing to their ability to interpret images, multimodal LLMs (MLLMs) have been primarily used for vision-language tasks. Currently, MLLMs have not yet been extended for domain-specific visual tasks, which require a more explicit understanding of visual information. We developed a method to transform domain-specific visual and vision-language datasets into a unified question answering format called Visual Question Answering Instruction (VQA-IN), thereby extending MLLM to domain-specific tasks. The VQA-IN was applied to train multiple MLLM architectures using smaller versions of LLMs (sLLMs). The experimental results indicated that the proposed method achieved a high score metric on domainspecific visual tasks while also maintaining its performance on vision-language tasks in a multitask manner.
Visually Dehallucinative Instruction Generation
Feb 13, 2024In recent years, synthetic visual instructions by generative language model have demonstrated plausible text generation performance on the visual question-answering tasks. However, challenges persist in the hallucination of generative language models, i.e., the generated image-text data contains unintended contents. This paper presents a novel and scalable method for generating visually dehallucinative instructions, dubbed CAP2QA, that constrains the scope to only image contents. Our key contributions lie in introducing image-aligned instructive QA dataset CAP2QA-COCO and its scalable recipe. In our experiments, we compare synthetic visual instruction datasets that share the same source data by visual instruction tuning and conduct general visual recognition tasks. It shows that our proposed method significantly reduces visual hallucination while consistently improving visual recognition ability and expressiveness.
Neural Architecture Adaptation for Object Detection by Searching Channel Dimensions and Mapping Pre-trained Parameters
Jun 17, 2022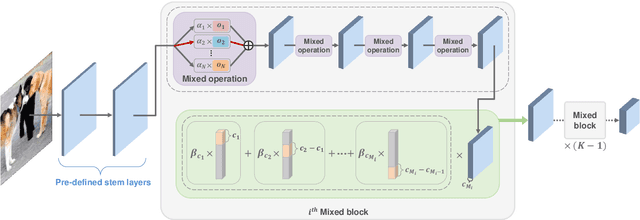

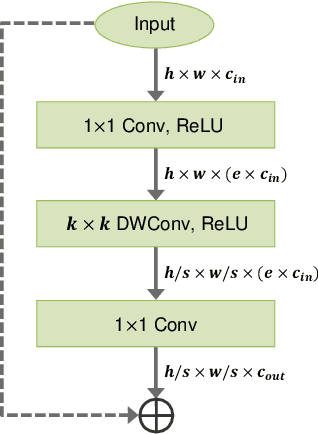

Most object detection frameworks use backbone architectures originally designed for image classification, conventionally with pre-trained parameters on ImageNet. However, image classification and object detection are essentially different tasks and there is no guarantee that the optimal backbone for classification is also optimal for object detection. Recent neural architecture search (NAS) research has demonstrated that automatically designing a backbone specifically for object detection helps improve the overall accuracy. In this paper, we introduce a neural architecture adaptation method that can optimize the given backbone for detection purposes, while still allowing the use of pre-trained parameters. We propose to adapt both the micro- and macro-architecture by searching for specific operations and the number of layers, in addition to the output channel dimensions of each block. It is important to find the optimal channel depth, as it greatly affects the feature representation capability and computation cost. We conduct experiments with our searched backbone for object detection and demonstrate that our backbone outperforms both manually designed and searched state-of-the-art backbones on the COCO dataset.