 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniRetrieval: Unified Retrieval across Heterogeneous Knowledge Sources
May 28, 2026Real-world information needs require access to structurally diverse knowledge sources, from unstructured text and relational tables to knowledge graphs and property graphs. Existing retrievers, however, operate over one source at a time under a fixed query language, leaving the broader landscape of available knowledge fragmented behind incompatible interfaces. A natural attempt at unification would collapse these sources into a shared space, but this erases the structural affordances (such as schemas, ontologies, compositional operators) that give each source its expressive power. Effective retrieval over diverse knowledge, therefore, requires not homogenization but an overarching layer that meets each source on its own terms. To achieve this, we present OmniRetrieval, a framework that takes any natural-language query, identifies appropriate knowledge sources, and dispatches source-native queries to their native execution engines. Across an extensive benchmark spanning 13 datasets and 309 distinct knowledge bases over text, relational, and graph-structured sources, OmniRetrieval exceeds single-source baselines, demonstrating that it can serve as a general-purpose interface to the heterogeneous sources while preserving the structural distinctions that make each source valuable.
It Takes Two: Complementary Self-Distillation for Contextual Integrity in LLMs
May 18, 2026Contextual Integrity (CI) defines privacy not merely as keeping information hidden, but as governing information flows according to the norms of a given context. As large language models are increasingly deployed as personal agents handling sensitive workflows, adhering to CI becomes critical. However, even frontier models remain unreliable in making disclosure decisions, and existing mitigation strategies often degrade underlying task performance. To overcome this privacy-utility trade-off, we propose SELFCI, a complementary self-distillation framework that decouples information suppression from task resolution. SELFCI jointly optimizes two independent reverse KL divergences over distinct teacher distributions derived from feedback: one encourages preserving task-relevant information for utility, while the other enforces minimal and appropriate disclosure. This complementary formulation induces a Product-of-Experts (PoE) target, aligning the policy with the intersection of capability and privacy requirements. Empirical evaluations demonstrate that SELFCI, without relying on costly external supervision, consistently outperforms competitive baselines such as online reinforcement learning algorithms (e.g., GRPO). These trends further extend to out-of-domain settings involving agentic workflows and accumulated private context, suggesting that SELFCI provides a practical path toward CI alignment.
MA-EgoQA: Question Answering over Egocentric Videos from Multiple Embodied Agents
Mar 11, 2026As embodied models become powerful, humans will collaborate with multiple embodied AI agents at their workplace or home in the future. To ensure better communication between human users and the multi-agent system, it is crucial to interpret incoming information from agents in parallel and refer to the appropriate context for each query. Existing challenges include effectively compressing and communicating high volumes of individual sensory inputs in the form of video and correctly aggregating multiple egocentric videos to construct system-level memory. In this work, we first formally define a novel problem of understanding multiple long-horizon egocentric videos simultaneously collected from embodied agents. To facilitate research in this direction, we introduce MultiAgent-EgoQA (MA-EgoQA), a benchmark designed to systemically evaluate existing models in our scenario. MA-EgoQA provides 1.7k questions unique to multiple egocentric streams, spanning five categories: social interaction, task coordination, theory-of-mind, temporal reasoning, and environmental interaction. We further propose a simple baseline model for MA-EgoQA named EgoMAS, which leverages shared memory across embodied agents and agent-wise dynamic retrieval. Through comprehensive evaluation across diverse baselines and EgoMAS on MA-EgoQA, we find that current approaches are unable to effectively handle multiple egocentric streams, highlighting the need for future advances in system-level understanding across the agents. The code and benchmark are available at https://ma-egoqa.github.io.
UniversalRAG: Retrieval-Augmented Generation over Multiple Corpora with Diverse Modalities and Granularities
Apr 29, 2025



Retrieval-Augmented Generation (RAG) has shown substantial promise in improving factual accuracy by grounding model responses with external knowledge relevant to queries. However, most existing RAG approaches are limited to a text-only corpus, and while recent efforts have extended RAG to other modalities such as images and videos, they typically operate over a single modality-specific corpus. In contrast, real-world queries vary widely in the type of knowledge they require, which a single type of knowledge source cannot address. To address this, we introduce UniversalRAG, a novel RAG framework designed to retrieve and integrate knowledge from heterogeneous sources with diverse modalities and granularities. Specifically, motivated by the observation that forcing all modalities into a unified representation space derived from a single combined corpus causes a modality gap, where the retrieval tends to favor items from the same modality as the query, we propose a modality-aware routing mechanism that dynamically identifies the most appropriate modality-specific corpus and performs targeted retrieval within it. Also, beyond modality, we organize each modality into multiple granularity levels, enabling fine-tuned retrieval tailored to the complexity and scope of the query. We validate UniversalRAG on 8 benchmarks spanning multiple modalities, showing its superiority over modality-specific and unified baselines.
VideoICL: Confidence-based Iterative In-context Learning for Out-of-Distribution Video Understanding
Dec 03, 2024
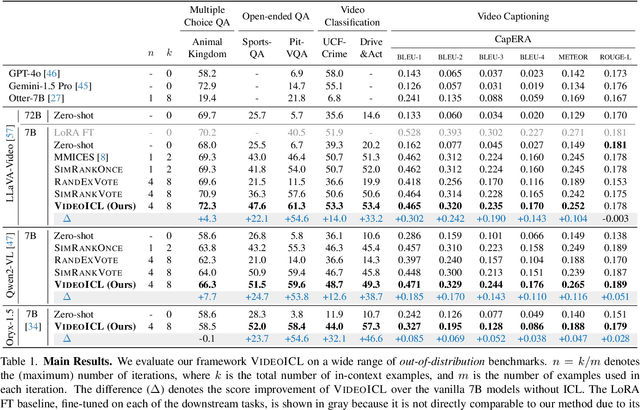


Recent advancements in video large multimodal models (LMMs) have significantly improved their video understanding and reasoning capabilities. However, their performance drops on out-of-distribution (OOD) tasks that are underrepresented in training data. Traditional methods like fine-tuning on OOD datasets are impractical due to high computational costs. While In-context learning (ICL) with demonstration examples has shown promising generalization performance in language tasks and image-language tasks without fine-tuning, applying ICL to video-language tasks faces challenges due to the limited context length in Video LMMs, as videos require longer token lengths. To address these issues, we propose VideoICL, a novel video in-context learning framework for OOD tasks that introduces a similarity-based relevant example selection strategy and a confidence-based iterative inference approach. This allows to select the most relevant examples and rank them based on similarity, to be used for inference. If the generated response has low confidence, our framework selects new examples and performs inference again, iteratively refining the results until a high-confidence response is obtained. This approach improves OOD video understanding performance by extending effective context length without incurring high costs. The experimental results on multiple benchmarks demonstrate significant performance gains, especially in domain-specific scenarios, laying the groundwork for broader video comprehension applications. Code will be released at https://github.com/KangsanKim07/VideoICL