 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniRetrieval: Unified Retrieval across Heterogeneous Knowledge Sources
May 28, 2026Real-world information needs require access to structurally diverse knowledge sources, from unstructured text and relational tables to knowledge graphs and property graphs. Existing retrievers, however, operate over one source at a time under a fixed query language, leaving the broader landscape of available knowledge fragmented behind incompatible interfaces. A natural attempt at unification would collapse these sources into a shared space, but this erases the structural affordances (such as schemas, ontologies, compositional operators) that give each source its expressive power. Effective retrieval over diverse knowledge, therefore, requires not homogenization but an overarching layer that meets each source on its own terms. To achieve this, we present OmniRetrieval, a framework that takes any natural-language query, identifies appropriate knowledge sources, and dispatches source-native queries to their native execution engines. Across an extensive benchmark spanning 13 datasets and 309 distinct knowledge bases over text, relational, and graph-structured sources, OmniRetrieval exceeds single-source baselines, demonstrating that it can serve as a general-purpose interface to the heterogeneous sources while preserving the structural distinctions that make each source valuable.
GFlowPO: Generative Flow Network as a Language Model Prompt Optimizer
Feb 03, 2026Finding effective prompts for language models (LMs) is critical yet notoriously difficult: the prompt space is combinatorially large, rewards are sparse due to expensive target-LM evaluation. Yet, existing RL-based prompt optimizers often rely on on-policy updates and a meta-prompt sampled from a fixed distribution, leading to poor sample efficiency. We propose GFlowPO, a probabilistic prompt optimization framework that casts prompt search as a posterior inference problem over latent prompts regularized by a meta-prompted reference-LM prior. In the first step, we fine-tune a lightweight prompt-LM with an off-policy Generative Flow Network (GFlowNet) objective, using a replay-based training policy that reuses past prompt evaluations to enable sample-efficient exploration. In the second step, we introduce Dynamic Memory Update (DMU), a training-free mechanism that updates the meta-prompt by injecting both (i) diverse prompts from a replay buffer and (ii) top-performing prompts from a small priority queue, thereby progressively concentrating the search process on high-reward regions. Across few-shot text classification, instruction induction benchmarks, and question answering tasks, GFlowPO consistently outperforms recent discrete prompt optimization baselines.
TS-Debate: Multimodal Collaborative Debate for Zero-Shot Time Series Reasoning
Jan 27, 2026Recent progress at the intersection of large language models (LLMs) and time series (TS) analysis has revealed both promise and fragility. While LLMs can reason over temporal structure given carefully engineered context, they often struggle with numeric fidelity, modality interference, and principled cross-modal integration. We present TS-Debate, a modality-specialized, collaborative multi-agent debate framework for zero-shot time series reasoning. TS-Debate assigns dedicated expert agents to textual context, visual patterns, and numerical signals, preceded by explicit domain knowledge elicitation, and coordinates their interaction via a structured debate protocol. Reviewer agents evaluate agent claims using a verification-conflict-calibration mechanism, supported by lightweight code execution and numerical lookup for programmatic verification. This architecture preserves modality fidelity, exposes conflicting evidence, and mitigates numeric hallucinations without task-specific fine-tuning. Across 20 tasks spanning three public benchmarks, TS-Debate achieves consistent and significant performance improvements over strong baselines, including standard multimodal debate in which all agents observe all inputs.
Rethinking Reward Models for Multi-Domain Test-Time Scaling
Oct 02, 2025The reliability of large language models (LLMs) during test-time scaling is often assessed with \emph{external verifiers} or \emph{reward models} that distinguish correct reasoning from flawed logic. Prior work generally assumes that process reward models (PRMs), which score every intermediate reasoning step, outperform outcome reward models (ORMs) that assess only the final answer. This view is based mainly on evidence from narrow, math-adjacent domains. We present the first unified evaluation of four reward model variants, discriminative ORM and PRM (\DisORM, \DisPRM) and generative ORM and PRM (\GenORM, \GenPRM), across 14 diverse domains. Contrary to conventional wisdom, we find that (i) \DisORM performs on par with \DisPRM, (ii) \GenPRM is not competitive, and (iii) overall, \GenORM is the most robust, yielding significant and consistent gains across every tested domain. We attribute this to PRM-style stepwise scoring, which inherits label noise from LLM auto-labeling and has difficulty evaluating long reasoning trajectories, including those involving self-correcting reasoning. Our theoretical analysis shows that step-wise aggregation compounds errors as reasoning length grows, and our empirical observations confirm this effect. These findings challenge the prevailing assumption that fine-grained supervision is always better and support generative outcome verification for multi-domain deployment. We publicly release our code, datasets, and checkpoints at \href{https://github.com/db-Lee/Multi-RM}{\underline{\small\texttt{https://github.com/db-Lee/Multi-RM}}} to facilitate future research in multi-domain settings.
Delta Attention: Fast and Accurate Sparse Attention Inference by Delta Correction
May 16, 2025The attention mechanism of a transformer has a quadratic complexity, leading to high inference costs and latency for long sequences. However, attention matrices are mostly sparse, which implies that many entries may be omitted from computation for efficient inference. Sparse attention inference methods aim to reduce this computational burden; however, they also come with a troublesome performance degradation. We discover that one reason for this degradation is that the sparse calculation induces a distributional shift in the attention outputs. The distributional shift causes decoding-time queries to fail to align well with the appropriate keys from the prefill stage, leading to a drop in performance. We propose a simple, novel, and effective procedure for correcting this distributional shift, bringing the distribution of sparse attention outputs closer to that of quadratic attention. Our method can be applied on top of any sparse attention method, and results in an average 36%pt performance increase, recovering 88% of quadratic attention accuracy on the 131K RULER benchmark when applied on top of sliding window attention with sink tokens while only adding a small overhead. Our method can maintain approximately 98.5% sparsity over full quadratic attention, making our model 32 times faster than Flash Attention 2 when processing 1M token prefills.
InfiniteHiP: Extending Language Model Context Up to 3 Million Tokens on a Single GPU
Feb 13, 2025In modern large language models (LLMs), handling very long context lengths presents significant challenges as it causes slower inference speeds and increased memory costs. Additionally, most existing pre-trained LLMs fail to generalize beyond their original training sequence lengths. To enable efficient and practical long-context utilization, we introduce InfiniteHiP, a novel, and practical LLM inference framework that accelerates processing by dynamically eliminating irrelevant context tokens through a modular hierarchical token pruning algorithm. Our method also allows generalization to longer sequences by selectively applying various RoPE adjustment methods according to the internal attention patterns within LLMs. Furthermore, we offload the key-value cache to host memory during inference, significantly reducing GPU memory pressure. As a result, InfiniteHiP enables the processing of up to 3 million tokens on a single L40s 48GB GPU -- 3x larger -- without any permanent loss of context information. Our framework achieves an 18.95x speedup in attention decoding for a 1 million token context without requiring additional training. We implement our method in the SGLang framework and demonstrate its effectiveness and practicality through extensive evaluations.
Training-Free Exponential Extension of Sliding Window Context with Cascading KV Cache
Jun 24, 2024
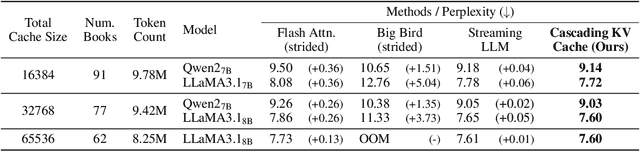


The context window within a transformer provides a form of active memory for the current task, which can be useful for few-shot learning and conditional generation, both which depend heavily on previous context tokens. However, as the context length grows, the computational cost increases quadratically. Recent works have shown that saving a few initial tokens along with a fixed-sized sliding window leads to stable streaming generation with linear complexity in transformer-based Large Language Models (LLMs). However, they make suboptimal use of the fixed window by naively evicting all tokens unconditionally from the key-value (KV) cache once they reach the end of the window, resulting in tokens being forgotten and no longer able to affect subsequent predictions. To overcome this limitation, we propose a novel mechanism for storing longer sliding window contexts with the same total cache size by keeping separate cascading sub-cache buffers whereby each subsequent buffer conditionally accepts a fraction of the relatively more important tokens evicted from the previous buffer. Our method results in a dynamic KV cache that can store tokens from the more distant past than a fixed, static sliding window approach. Our experiments show improvements of 5.6% on long context generation (LongBench), 1.2% in streaming perplexity (PG19), and 0.6% in language understanding (MMLU STEM) using LLMs given the same fixed cache size. Additionally, we provide an efficient implementation that improves the KV cache latency from 1.33ms per caching operation to 0.54ms, a 59% speedup over previous work.
HiP Attention: Sparse Sub-Quadratic Attention with Hierarchical Attention Pruning
Jun 14, 2024In modern large language models (LLMs), increasing sequence lengths is a crucial challenge for enhancing their comprehension and coherence in handling complex tasks such as multi-modal question answering. However, handling long context sequences with LLMs is prohibitively costly due to the conventional attention mechanism's quadratic time and space complexity, and the context window size is limited by the GPU memory. Although recent works have proposed linear and sparse attention mechanisms to address this issue, their real-world applicability is often limited by the need to re-train pre-trained models. In response, we propose a novel approach, Hierarchically Pruned Attention (HiP), which simultaneously reduces the training and inference time complexity from $O(T^2)$ to $O(T \log T)$ and the space complexity from $O(T^2)$ to $O(T)$. To this end, we devise a dynamic sparse attention mechanism that generates an attention mask through a novel tree-search-like algorithm for a given query on the fly. HiP is training-free as it only utilizes the pre-trained attention scores to spot the positions of the top-$k$ most significant elements for each query. Moreover, it ensures that no token is overlooked, unlike the sliding window-based sub-quadratic attention methods, such as StreamingLLM. Extensive experiments on diverse real-world benchmarks demonstrate that HiP significantly reduces prompt (i.e., prefill) and decoding latency and memory usage while maintaining high generation performance with little or no degradation. As HiP allows pretrained LLMs to scale to millions of tokens on commodity GPUs with no additional engineering due to its easy plug-and-play deployment, we believe that our work will have a large practical impact, opening up the possibility to many long-context LLM applications previously infeasible.
SEA: Sparse Linear Attention with Estimated Attention Mask
Oct 03, 2023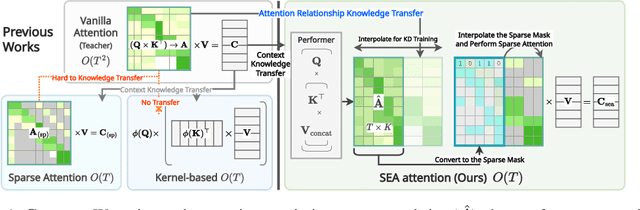
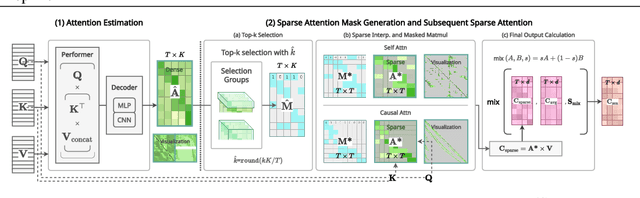
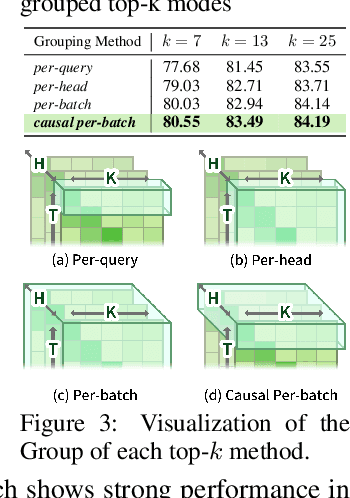
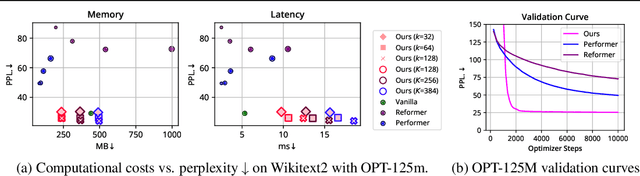
The transformer architecture has made breakthroughs in recent years on tasks which require modeling pairwise relationships between sequential elements, as is the case in natural language understanding. However, transformers struggle with long sequences due to the quadratic complexity of the attention operation, and previous research has aimed to lower the complexity by sparsifying or linearly approximating the attention matrix. Yet, these approaches cannot straightforwardly distill knowledge from a teacher's attention matrix, and often require complete retraining from scratch. Furthermore, previous sparse and linear approaches may also lose interpretability if they do not produce full quadratic attention matrices. To address these challenges, we propose SEA: Sparse linear attention with an Estimated Attention mask. SEA estimates the attention matrix with linear complexity via kernel-based linear attention, then creates a sparse approximation to the full attention matrix with a top-k selection to perform a sparse attention operation. For language modeling tasks (Wikitext2), previous linear and sparse attention methods show a roughly two-fold worse perplexity scores over the quadratic OPT-125M baseline, while SEA achieves an even better perplexity than OPT-125M, using roughly half as much memory as OPT-125M. Moreover, SEA maintains an interpretable attention matrix and can utilize knowledge distillation to lower the complexity of existing pretrained transformers. We believe that our work will have a large practical impact, as it opens the possibility of running large transformers on resource-limited devices with less memory.
K-MHaS: A Multi-label Hate Speech Detection Dataset in Korean Online News Comment
Aug 28, 2022

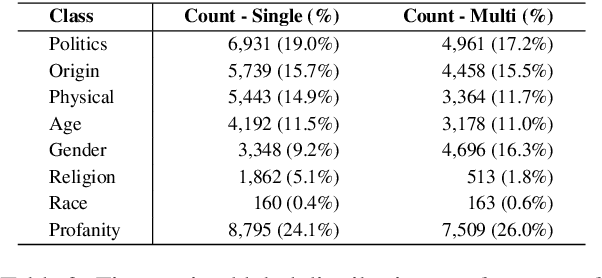

Online Hate speech detection has become important with the growth of digital devices, but resources in languages other than English are extremely limited. We introduce K-MHaS, a new multi-label dataset for hate speech detection that effectively handles Korean language patterns. The dataset consists of 109k utterances from news comments and provides multi-label classification from 1 to 4 labels, and handling subjectivity and intersectionality. We evaluate strong baselines on K-MHaS. KR-BERT with sub-character tokenizer outperforms, recognising decomposed characters in each hate speech class.