 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning based Visually Rich Document Content Understanding: A Survey
Aug 02, 2024
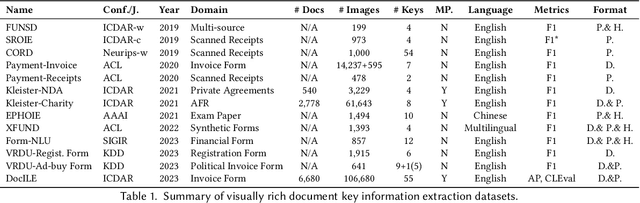
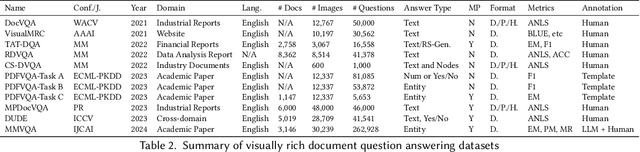
Visually Rich Documents (VRDs) are essential in academia, finance, medical fields, and marketing due to their multimodal information content. Traditional methods for extracting information from VRDs depend on expert knowledge and manual labor, making them costly and inefficient. The advent of deep learning has revolutionized this process, introducing models that leverage multimodal information vision, text, and layout along with pretraining tasks to develop comprehensive document representations. These models have achieved state-of-the-art performance across various downstream tasks, significantly enhancing the efficiency and accuracy of information extraction from VRDs. In response to the growing demands and rapid developments in Visually Rich Document Understanding (VRDU), this paper provides a comprehensive review of deep learning-based VRDU frameworks. We systematically survey and analyze existing methods and benchmark datasets, categorizing them based on adopted strategies and downstream tasks. Furthermore, we compare different techniques used in VRDU models, focusing on feature representation and fusion, model architecture, and pretraining methods, while highlighting their strengths, limitations, and appropriate scenarios. Finally, we identify emerging trends and challenges in VRDU, offering insights into future research directions and practical applications. This survey aims to provide a thorough understanding of VRDU advancements, benefiting both academic and industrial sectors.
M3-VRD: Multimodal Multi-task Multi-teacher Visually-Rich Form Document Understanding
Feb 28, 2024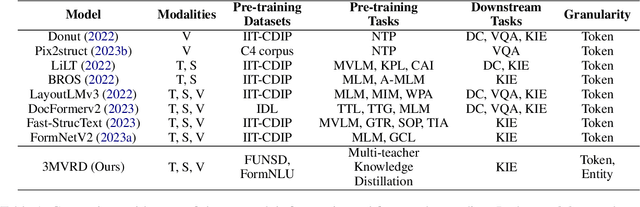
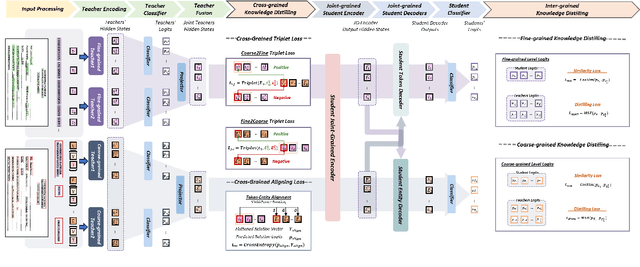
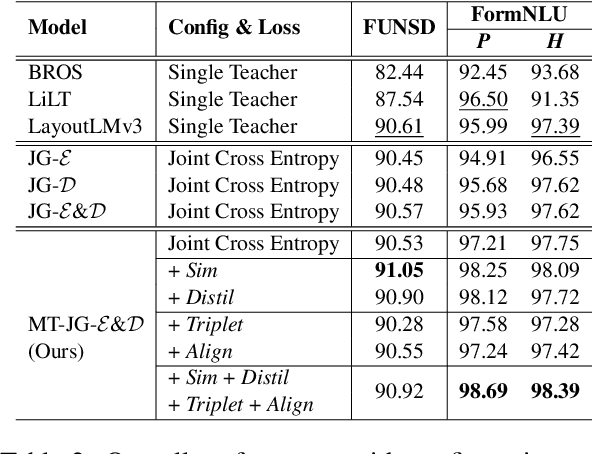
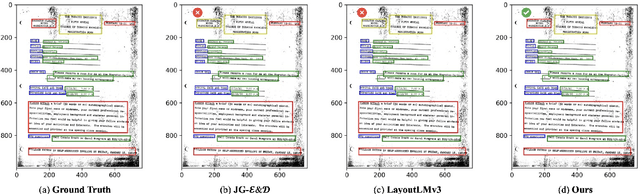
This paper presents a groundbreaking multimodal, multi-task, multi-teacher joint-grained knowledge distillation model for visually-rich form document understanding. The model is designed to leverage insights from both fine-grained and coarse-grained levels by facilitating a nuanced correlation between token and entity representations, addressing the complexities inherent in form documents. Additionally, we introduce new inter-grained and cross-grained loss functions to further refine diverse multi-teacher knowledge distillation transfer process, presenting distribution gaps and a harmonised understanding of form documents. Through a comprehensive evaluation across publicly available form document understanding datasets, our proposed model consistently outperforms existing baselines, showcasing its efficacy in handling the intricate structures and content of visually complex form documents.
A Survey of Large Language Models in Finance
Feb 04, 2024Large Language Models (LLMs) have shown remarkable capabilities across a wide variety of Natural Language Processing (NLP) tasks and have attracted attention from multiple domains, including financial services. Despite the extensive research into general-domain LLMs, and their immense potential in finance, Financial LLM (FinLLM) research remains limited. This survey provides a comprehensive overview of FinLLMs, including their history, techniques, performance, and opportunities and challenges. Firstly, we present a chronological overview of general-domain Pre-trained Language Models (PLMs) through to current FinLLMs, including the GPT-series, selected open-source LLMs, and financial LMs. Secondly, we compare five techniques used across financial PLMs and FinLLMs, including training methods, training data, and fine-tuning methods. Thirdly, we summarize the performance evaluations of six benchmark tasks and datasets. In addition, we provide eight advanced financial NLP tasks and datasets for developing more sophisticated FinLLMs. Finally, we discuss the opportunities and the challenges facing FinLLMs, such as hallucination, privacy, and efficiency. To support AI research in finance, we compile a collection of accessible datasets and evaluation benchmarks on GitHub.
StockEmotions: Discover Investor Emotions for Financial Sentiment Analysis and Multivariate Time Series
Jan 23, 2023



There has been growing interest in applying NLP techniques in the financial domain, however, resources are extremely limited. This paper introduces StockEmotions, a new dataset for detecting emotions in the stock market that consists of 10,000 English comments collected from StockTwits, a financial social media platform. Inspired by behavioral finance, it proposes 12 fine-grained emotion classes that span the roller coaster of investor emotion. Unlike existing financial sentiment datasets, StockEmotions presents granular features such as investor sentiment classes, fine-grained emotions, emojis, and time series data. To demonstrate the usability of the dataset, we perform a dataset analysis and conduct experimental downstream tasks. For financial sentiment/emotion classification tasks, DistilBERT outperforms other baselines, and for multivariate time series forecasting, a Temporal Attention LSTM model combining price index, text, and emotion features achieves the best performance than using a single feature.
K-MHaS: A Multi-label Hate Speech Detection Dataset in Korean Online News Comment
Aug 28, 2022


Online Hate speech detection has become important with the growth of digital devices, but resources in languages other than English are extremely limited. We introduce K-MHaS, a new multi-label dataset for hate speech detection that effectively handles Korean language patterns. The dataset consists of 109k utterances from news comments and provides multi-label classification from 1 to 4 labels, and handling subjectivity and intersectionality. We evaluate strong baselines on K-MHaS. KR-BERT with sub-character tokenizer outperforms, recognising decomposed characters in each hate speech class.
FedNLP: An interpretable NLP System to Decode Federal Reserve Communications
Jun 11, 2021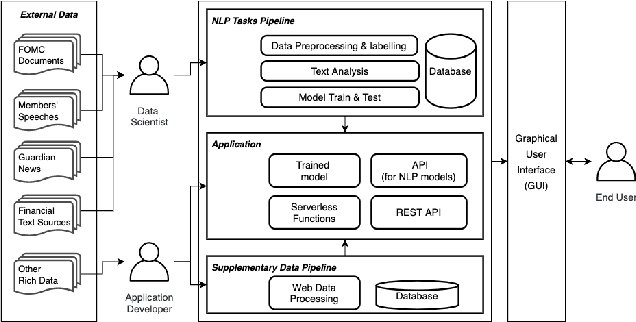

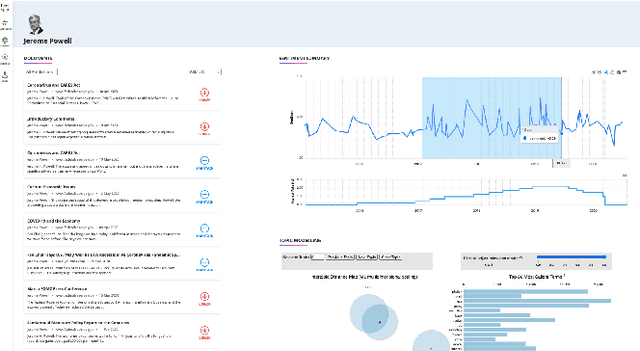

The Federal Reserve System (the Fed) plays a significant role in affecting monetary policy and financial conditions worldwide. Although it is important to analyse the Fed's communications to extract useful information, it is generally long-form and complex due to the ambiguous and esoteric nature of content. In this paper, we present FedNLP, an interpretable multi-component Natural Language Processing system to decode Federal Reserve communications. This system is designed for end-users to explore how NLP techniques can assist their holistic understanding of the Fed's communications with NO coding. Behind the scenes, FedNLP uses multiple NLP models from traditional machine learning algorithms to deep neural network architectures in each downstream task. The demonstration shows multiple results at once including sentiment analysis, summary of the document, prediction of the Federal Funds Rate movement and visualization for interpreting the prediction model's result.
CONDA: a CONtextual Dual-Annotated dataset for in-game toxicity understanding and detection
Jun 11, 2021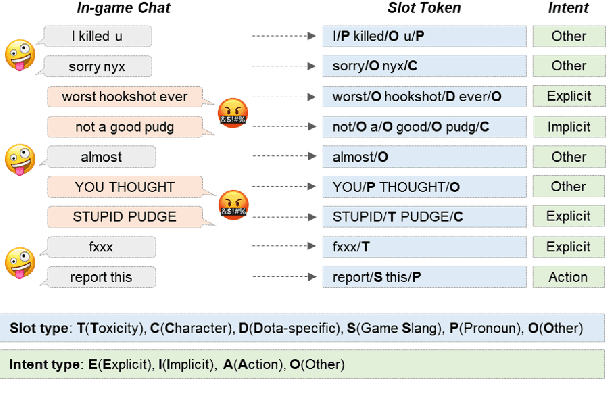
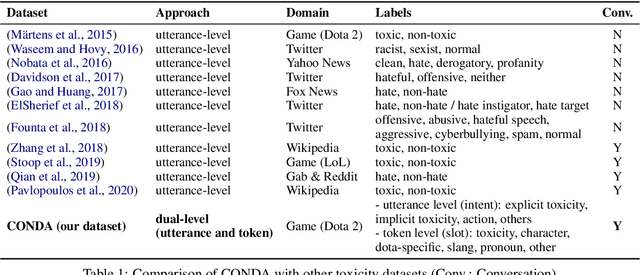

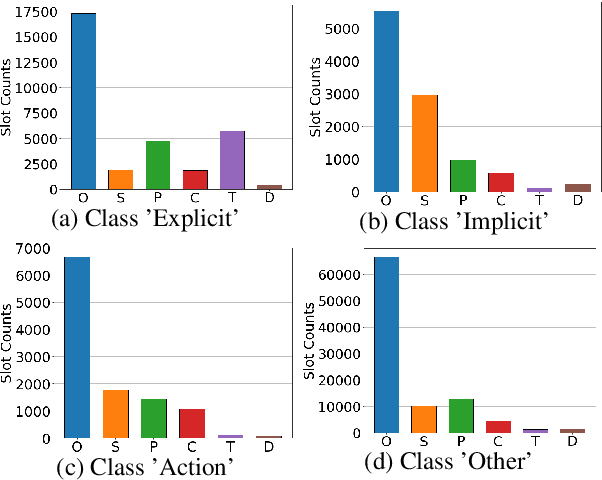
Traditional toxicity detection models have focused on the single utterance level without deeper understanding of context. We introduce CONDA, a new dataset for in-game toxic language detection enabling joint intent classification and slot filling analysis, which is the core task of Natural Language Understanding (NLU). The dataset consists of 45K utterances from 12K conversations from the chat logs of 1.9K completed Dota 2 matches. We propose a robust dual semantic-level toxicity framework, which handles utterance and token-level patterns, and rich contextual chatting history. Accompanying the dataset is a thorough in-game toxicity analysis, which provides comprehensive understanding of context at utterance, token, and dual levels. Inspired by NLU, we also apply its metrics to the toxicity detection tasks for assessing toxicity and game-specific aspects. We evaluate strong NLU models on CONDA, providing fine-grained results for different intent classes and slot classes. Furthermore, we examine the coverage of toxicity nature in our dataset by comparing it with other toxicity datasets.
Choosing Transfer Languages for Cross-Lingual Learning
Jun 07, 2019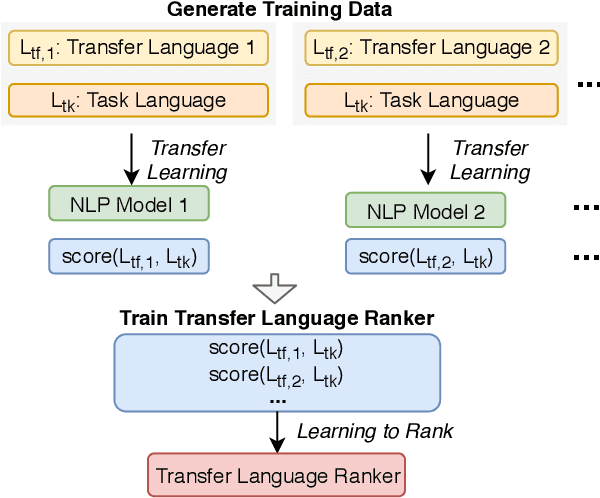
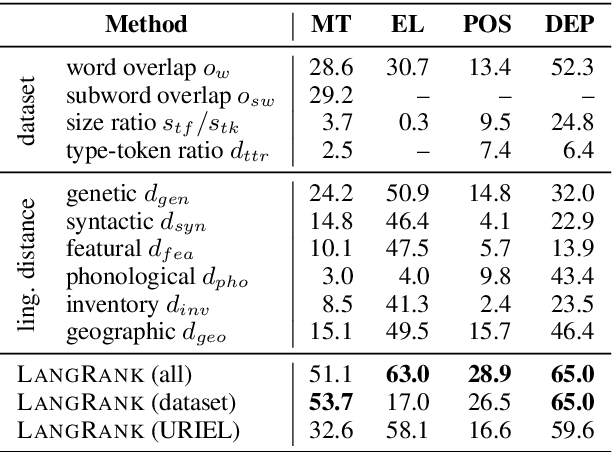
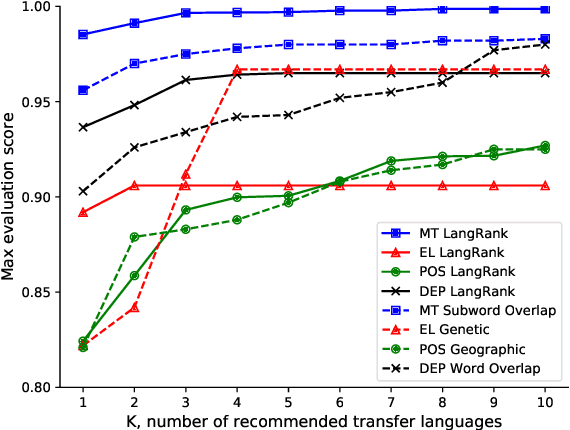
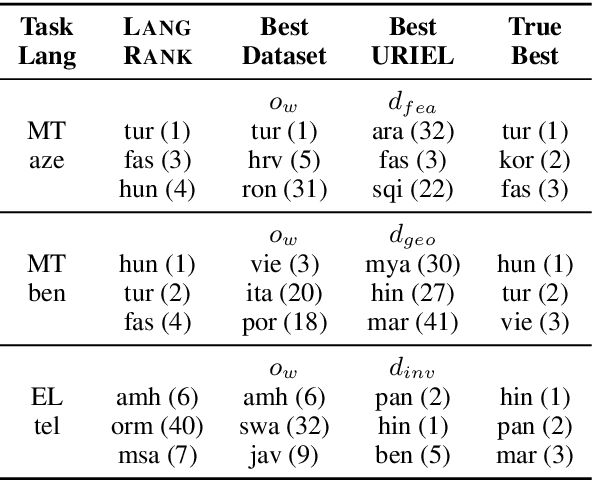
Cross-lingual transfer, where a high-resource transfer language is used to improve the accuracy of a low-resource task language, is now an invaluable tool for improving performance of natural language processing (NLP) on low-resource languages. However, given a particular task language, it is not clear which language to transfer from, and the standard strategy is to select languages based on ad hoc criteria, usually the intuition of the experimenter. Since a large number of features contribute to the success of cross-lingual transfer (including phylogenetic similarity, typological properties, lexical overlap, or size of available data), even the most enlightened experimenter rarely considers all these factors for the particular task at hand. In this paper, we consider this task of automatically selecting optimal transfer languages as a ranking problem, and build models that consider the aforementioned features to perform this prediction. In experiments on representative NLP tasks, we demonstrate that our model predicts good transfer languages much better than ad hoc baselines considering single features in isolation, and glean insights on what features are most informative for each different NLP tasks, which may inform future ad hoc selection even without use of our method. Code, data, and pre-trained models are available at https://github.com/neulab/langrank
Towards a General-Purpose Linguistic Annotation Backend
Dec 13, 2018



Language documentation is inherently a time-intensive process; transcription, glossing, and corpus management consume a significant portion of documentary linguists' work. Advances in natural language processing can help to accelerate this work, using the linguists' past decisions as training material, but questions remain about how to prioritize human involvement. In this extended abstract, we describe the beginnings of a new project that will attempt to ease this language documentation process through the use of natural language processing (NLP) technology. It is based on (1) methods to adapt NLP tools to new languages, based on recent advances in massively multilingual neural networks, and (2) backend APIs and interfaces that allow linguists to upload their data. We then describe our current progress on two fronts: automatic phoneme transcription, and glossing. Finally, we briefly describe our future directions.