 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChoosing Transfer Languages for Cross-Lingual Learning
Jun 07, 2019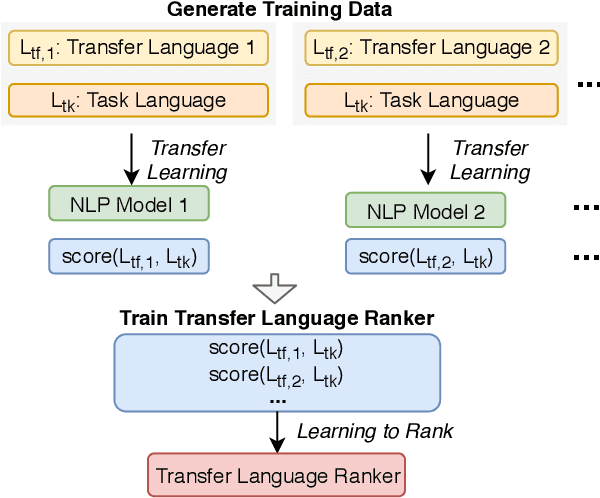
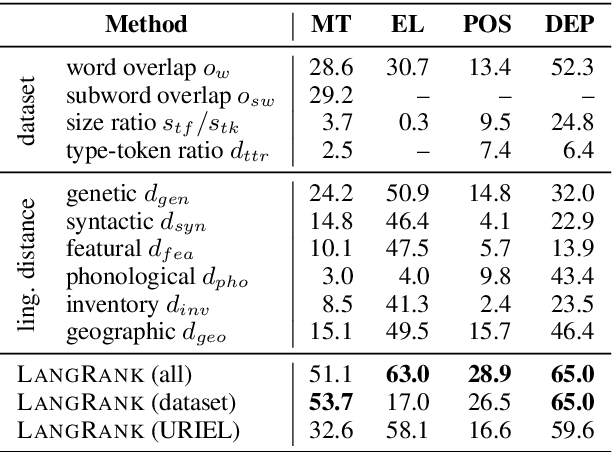
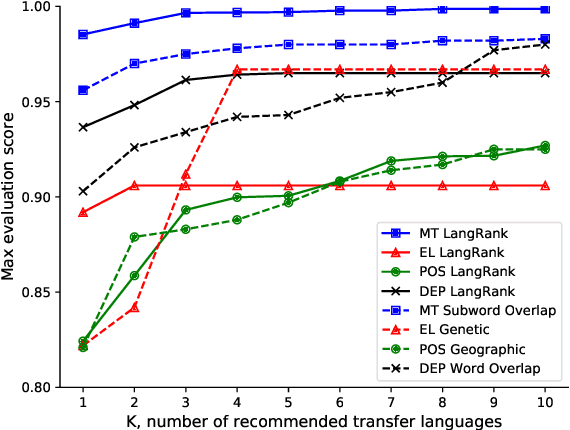
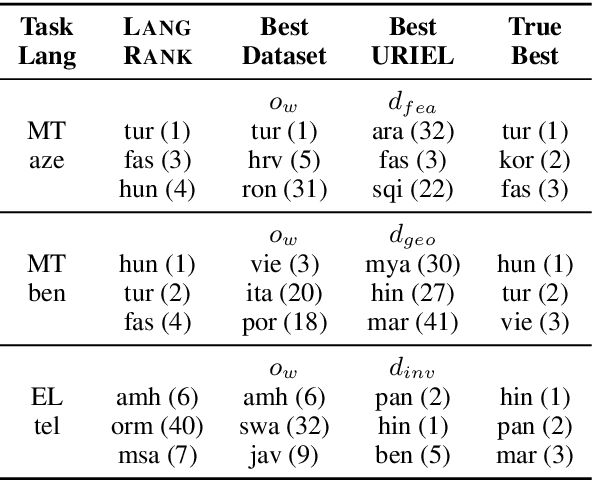
Cross-lingual transfer, where a high-resource transfer language is used to improve the accuracy of a low-resource task language, is now an invaluable tool for improving performance of natural language processing (NLP) on low-resource languages. However, given a particular task language, it is not clear which language to transfer from, and the standard strategy is to select languages based on ad hoc criteria, usually the intuition of the experimenter. Since a large number of features contribute to the success of cross-lingual transfer (including phylogenetic similarity, typological properties, lexical overlap, or size of available data), even the most enlightened experimenter rarely considers all these factors for the particular task at hand. In this paper, we consider this task of automatically selecting optimal transfer languages as a ranking problem, and build models that consider the aforementioned features to perform this prediction. In experiments on representative NLP tasks, we demonstrate that our model predicts good transfer languages much better than ad hoc baselines considering single features in isolation, and glean insights on what features are most informative for each different NLP tasks, which may inform future ad hoc selection even without use of our method. Code, data, and pre-trained models are available at https://github.com/neulab/langrank
Towards a General-Purpose Linguistic Annotation Backend
Dec 13, 2018



Language documentation is inherently a time-intensive process; transcription, glossing, and corpus management consume a significant portion of documentary linguists' work. Advances in natural language processing can help to accelerate this work, using the linguists' past decisions as training material, but questions remain about how to prioritize human involvement. In this extended abstract, we describe the beginnings of a new project that will attempt to ease this language documentation process through the use of natural language processing (NLP) technology. It is based on (1) methods to adapt NLP tools to new languages, based on recent advances in massively multilingual neural networks, and (2) backend APIs and interfaces that allow linguists to upload their data. We then describe our current progress on two fronts: automatic phoneme transcription, and glossing. Finally, we briefly describe our future directions.