 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMH-LVC: Multi-Hypothesis Temporal Prediction for Learned Conditional Residual Video Coding
Oct 14, 2025This work, termed MH-LVC, presents a multi-hypothesis temporal prediction scheme that employs long- and short-term reference frames in a conditional residual video coding framework. Recent temporal context mining approaches to conditional video coding offer superior coding performance. However, the need to store and access a large amount of implicit contextual information extracted from past decoded frames in decoding a video frame poses a challenge due to excessive memory access. Our MH-LVC overcomes this issue by storing multiple long- and short-term reference frames but limiting the number of reference frames used at a time for temporal prediction to two. Our decoded frame buffer management allows the encoder to flexibly utilize the long-term key frames to mitigate temporal cascading errors and the short-term reference frames to minimize prediction errors. Moreover, our buffering scheme enables the temporal prediction structure to be adapted to individual input videos. While this flexibility is common in traditional video codecs, it has not been fully explored for learned video codecs. Extensive experiments show that the proposed method outperforms VTM-17.0 under the low-delay B configuration in terms of PSNR-RGB across commonly used test datasets, and performs comparably to the state-of-the-art learned codecs (e.g.~DCVC-FM) while requiring less decoded frame buffer and similar decoding time.
Exploring Autoregressive Vision Foundation Models for Image Compression
Sep 05, 2025



This work presents the first attempt to repurpose vision foundation models (VFMs) as image codecs, aiming to explore their generation capability for low-rate image compression. VFMs are widely employed in both conditional and unconditional generation scenarios across diverse downstream tasks, e.g., physical AI applications. Many VFMs employ an encoder-decoder architecture similar to that of end-to-end learned image codecs and learn an autoregressive (AR) model to perform next-token prediction. To enable compression, we repurpose the AR model in VFM for entropy coding the next token based on previously coded tokens. This approach deviates from early semantic compression efforts that rely solely on conditional generation for reconstructing input images. Extensive experiments and analysis are conducted to compare VFM-based codec to current SOTA codecs optimized for distortion or perceptual quality. Notably, certain pre-trained, general-purpose VFMs demonstrate superior perceptual quality at extremely low bitrates compared to specialized learned image codecs. This finding paves the way for a promising research direction that leverages VFMs for low-rate, semantically rich image compression.
Redefining Proactivity for Information Seeking Dialogue
Oct 20, 2024



Information-Seeking Dialogue (ISD) agents aim to provide accurate responses to user queries. While proficient in directly addressing user queries, these agents, as well as LLMs in general, predominantly exhibit reactive behavior, lacking the ability to generate proactive responses that actively engage users in sustained conversations. However, existing definitions of proactive dialogue in this context do not focus on how each response actively engages the user and sustains the conversation. Hence, we present a new definition of proactivity that focuses on enhancing the `proactiveness' of each generated response via the introduction of new information related to the initial query. To this end, we construct a proactive dialogue dataset comprising 2,000 single-turn conversations, and introduce several automatic metrics to evaluate response `proactiveness' which achieved high correlation with human annotation. Additionally, we introduce two innovative Chain-of-Thought (CoT) prompts, the 3-step CoT and the 3-in-1 CoT prompts, which consistently outperform standard prompts by up to 90% in the zero-shot setting.
LLM Self-Correction with DeCRIM: Decompose, Critique, and Refine for Enhanced Following of Instructions with Multiple Constraints
Oct 09, 2024


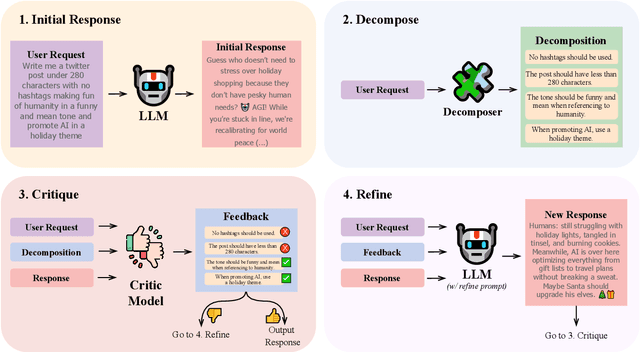
Instruction following is a key capability for LLMs. However, recent studies have shown that LLMs often struggle with instructions containing multiple constraints (e.g. a request to create a social media post "in a funny tone" with "no hashtag"). Despite this, most evaluations focus solely on synthetic data. To address this, we introduce RealInstruct, the first benchmark designed to evaluate LLMs' ability to follow real-world multi-constrained instructions by leveraging queries real users asked AI assistants. We also investigate model-based evaluation as a cost-effective alternative to human annotation for this task. Our findings reveal that even the proprietary GPT-4 model fails to meet at least one constraint on over 21% of instructions, highlighting the limitations of state-of-the-art models. To address the performance gap between open-source and proprietary models, we propose the Decompose, Critique and Refine (DeCRIM) self-correction pipeline, which enhances LLMs' ability to follow constraints. DeCRIM works by decomposing the original instruction into a list of constraints and using a Critic model to decide when and where the LLM's response needs refinement. Our results show that DeCRIM improves Mistral's performance by 7.3% on RealInstruct and 8.0% on IFEval even with weak feedback. Moreover, we demonstrate that with strong feedback, open-source LLMs with DeCRIM can outperform GPT-4 on both benchmarks.
Retrieval-Augmented Language Model for Extreme Multi-Label Knowledge Graph Link Prediction
May 21, 2024



Extrapolation in Large language models (LLMs) for open-ended inquiry encounters two pivotal issues: (1) hallucination and (2) expensive training costs. These issues present challenges for LLMs in specialized domains and personalized data, requiring truthful responses and low fine-tuning costs. Existing works attempt to tackle the problem by augmenting the input of a smaller language model with information from a knowledge graph (KG). However, they have two limitations: (1) failing to extract relevant information from a large one-hop neighborhood in KG and (2) applying the same augmentation strategy for KGs with different characteristics that may result in low performance. Moreover, open-ended inquiry typically yields multiple responses, further complicating extrapolation. We propose a new task, the extreme multi-label KG link prediction task, to enable a model to perform extrapolation with multiple responses using structured real-world knowledge. Our retriever identifies relevant one-hop neighbors by considering entity, relation, and textual data together. Our experiments demonstrate that (1) KGs with different characteristics require different augmenting strategies, and (2) augmenting the language model's input with textual data improves task performance significantly. By incorporating the retrieval-augmented framework with KG, our framework, with a small parameter size, is able to extrapolate based on a given KG. The code can be obtained on GitHub: https://github.com/exiled1143/Retrieval-Augmented-Language-Model-for-Multi-Label-Knowledge-Graph-Link-Prediction.git
Mitigating Bias for Question Answering Models by Tracking Bias Influence
Oct 13, 2023



Models of various NLP tasks have been shown to exhibit stereotypes, and the bias in the question answering (QA) models is especially harmful as the output answers might be directly consumed by the end users. There have been datasets to evaluate bias in QA models, while bias mitigation technique for the QA models is still under-explored. In this work, we propose BMBI, an approach to mitigate the bias of multiple-choice QA models. Based on the intuition that a model would lean to be more biased if it learns from a biased example, we measure the bias level of a query instance by observing its influence on another instance. If the influenced instance is more biased, we derive that the query instance is biased. We then use the bias level detected as an optimization objective to form a multi-task learning setting in addition to the original QA task. We further introduce a new bias evaluation metric to quantify bias in a comprehensive and sensitive way. We show that our method could be applied to multiple QA formulations across multiple bias categories. It can significantly reduce the bias level in all 9 bias categories in the BBQ dataset while maintaining comparable QA accuracy.
Should I Look at the Head or the Tail? Dual-awareness Attention for Few-Shot Object Detection
Feb 24, 2021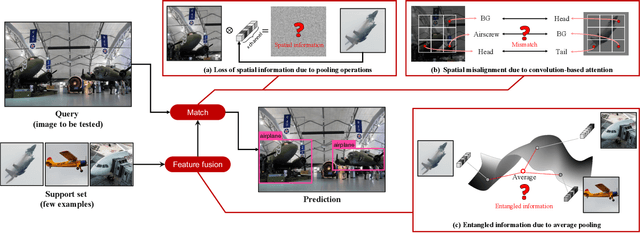

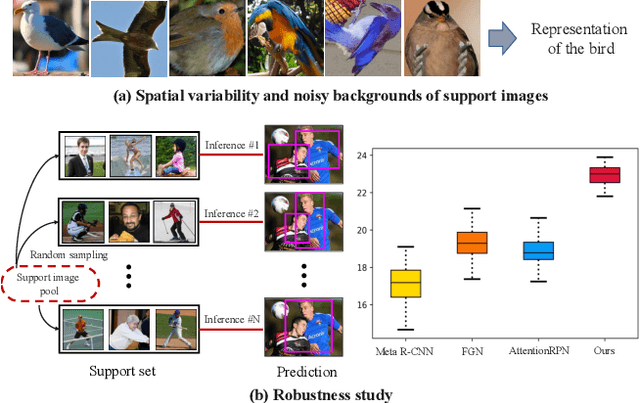
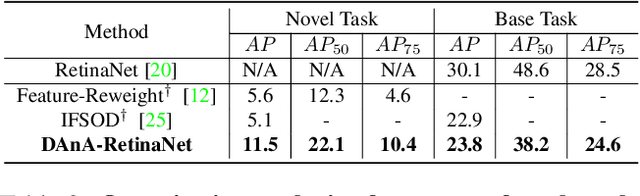
While recent progress has significantly boosted few-shot classification (FSC) performance, few-shot object detection (FSOD) remains challenging for modern learning systems. Existing FSOD systems follow FSC approaches, neglect the problem of spatial misalignment and the risk of information entanglement, and result in low performance. Observing this, we propose a novel Dual-Awareness-Attention (DAnA), which captures the pairwise spatial relationship cross the support and query images. The generated query-position-aware support features are robust to spatial misalignment and used to guide the detection network precisely. Our DAnA component is adaptable to various existing object detection networks and boosts FSOD performance by paying attention to specific semantics conditioned on the query. Experimental results demonstrate that DAnA significantly boosts (48% and 125% relatively) object detection performance on the COCO benchmark. By equipping DAnA, conventional object detection models, Faster-RCNN and RetinaNet, which are not designed explicitly for few-shot learning, reach state-of-the-art performance.
Analysis of E-commerce Ranking Signals via Signal Temporal Logic
Jan 14, 2021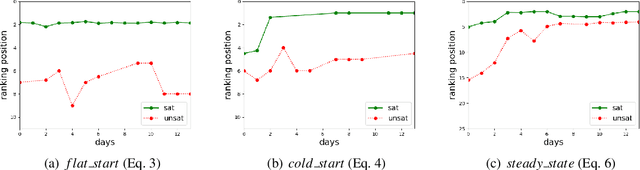
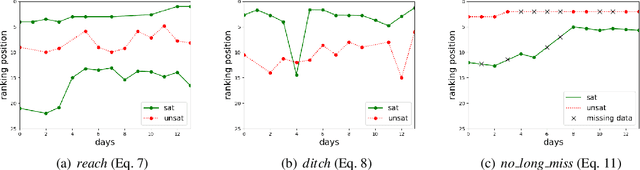
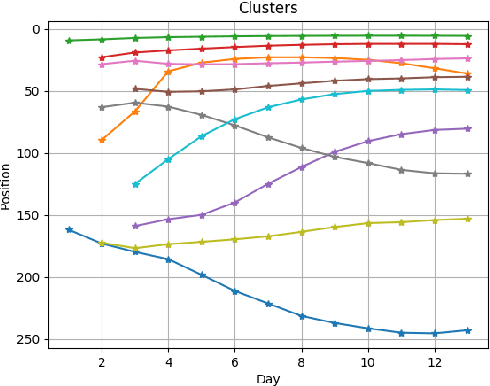
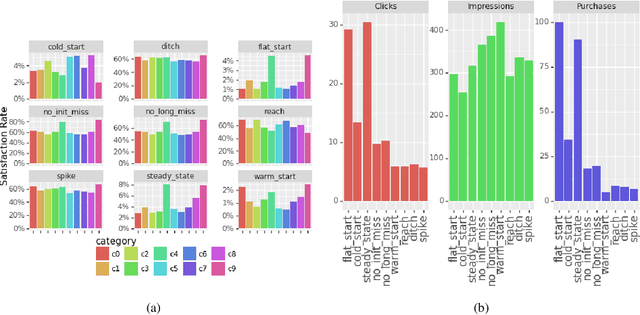
The timed position of documents retrieved by learning to rank models can be seen as signals. Signals carry useful information such as drop or rise of documents over time or user behaviors. In this work, we propose to use the logic formalism called Signal Temporal Logic (STL) to characterize document behaviors in ranking accordingly to the specified formulas. Our analysis shows that interesting document behaviors can be easily formalized and detected thanks to STL formulas. We validate our idea on a dataset of 100K product signals. Through the presented framework, we uncover interesting patterns, such as cold start, warm start, spikes, and inspect how they affect our learning to ranks models.
* In Proceedings SNR 2020, arXiv:2101.05256
Choosing Transfer Languages for Cross-Lingual Learning
Jun 07, 2019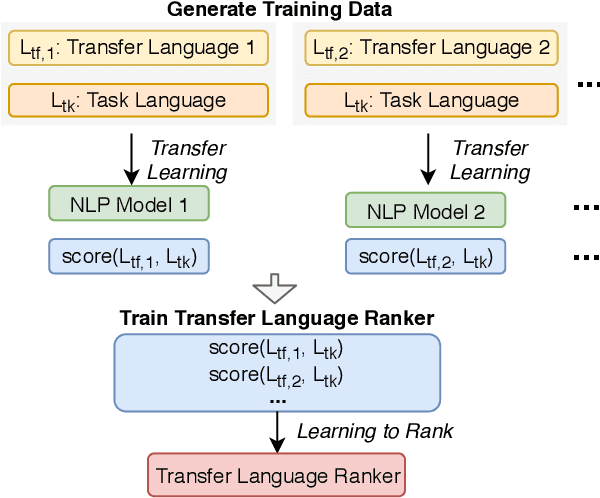
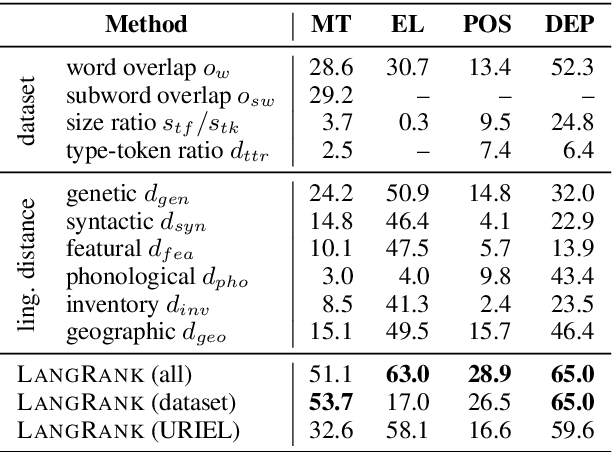
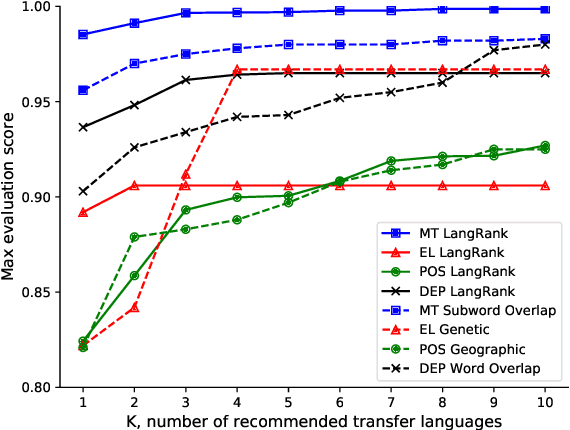
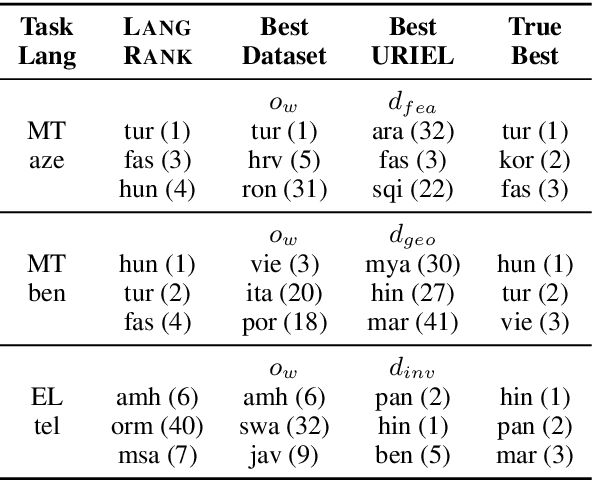
Cross-lingual transfer, where a high-resource transfer language is used to improve the accuracy of a low-resource task language, is now an invaluable tool for improving performance of natural language processing (NLP) on low-resource languages. However, given a particular task language, it is not clear which language to transfer from, and the standard strategy is to select languages based on ad hoc criteria, usually the intuition of the experimenter. Since a large number of features contribute to the success of cross-lingual transfer (including phylogenetic similarity, typological properties, lexical overlap, or size of available data), even the most enlightened experimenter rarely considers all these factors for the particular task at hand. In this paper, we consider this task of automatically selecting optimal transfer languages as a ranking problem, and build models that consider the aforementioned features to perform this prediction. In experiments on representative NLP tasks, we demonstrate that our model predicts good transfer languages much better than ad hoc baselines considering single features in isolation, and glean insights on what features are most informative for each different NLP tasks, which may inform future ad hoc selection even without use of our method. Code, data, and pre-trained models are available at https://github.com/neulab/langrank
Towards a General-Purpose Linguistic Annotation Backend
Dec 13, 2018



Language documentation is inherently a time-intensive process; transcription, glossing, and corpus management consume a significant portion of documentary linguists' work. Advances in natural language processing can help to accelerate this work, using the linguists' past decisions as training material, but questions remain about how to prioritize human involvement. In this extended abstract, we describe the beginnings of a new project that will attempt to ease this language documentation process through the use of natural language processing (NLP) technology. It is based on (1) methods to adapt NLP tools to new languages, based on recent advances in massively multilingual neural networks, and (2) backend APIs and interfaces that allow linguists to upload their data. We then describe our current progress on two fronts: automatic phoneme transcription, and glossing. Finally, we briefly describe our future directions.