 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIf You Want Coherence, Orchestrate a Team of Rivals: Multi-Agent Models of Organizational Intelligence
Jan 20, 2026AI Agents can perform complex operations at great speed, but just like all the humans we have ever hired, their intelligence remains fallible. Miscommunications aren't noticed, systemic biases have no counter-action, and inner monologues are rarely written down. We did not come to fire them for their mistakes, but to hire them and provide a safe productive working environment. We posit that we can reuse a common corporate organizational structure: teams of independent AI agents with strict role boundaries can work with common goals, but opposing incentives. Multiple models serving as a team of rivals can catch and minimize errors within the final product at a small cost to the velocity of actions. In this paper we demonstrate that we can achieve reliability without acquiring perfect components, but through careful orchestration of imperfect ones. This paper describes the architecture of such a system in practice: specialized agent teams (planners, executors, critics, experts), organized into an organization with clear goals, coordinated through a remote code executor that keeps data transformations and tool invocations separate from reasoning models. Rather than agents directly calling tools and ingesting full responses, they write code that executes remotely; only relevant summaries return to agent context. By preventing raw data and tool outputs from contaminating context windows, the system maintains clean separation between perception (brains that plan and reason) and execution (hands that perform heavy data transformations and API calls). We demonstrate the approach achieves over 90% internal error interception prior to user exposure while maintaining acceptable latency tradeoffs. A survey from our traces shows that we only trade off cost and latency to achieve correctness and incrementally expand capabilities without impacting existing ones.
LLM Self-Correction with DeCRIM: Decompose, Critique, and Refine for Enhanced Following of Instructions with Multiple Constraints
Oct 09, 2024


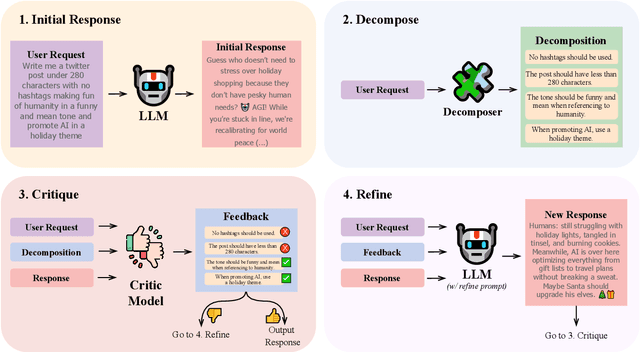
Instruction following is a key capability for LLMs. However, recent studies have shown that LLMs often struggle with instructions containing multiple constraints (e.g. a request to create a social media post "in a funny tone" with "no hashtag"). Despite this, most evaluations focus solely on synthetic data. To address this, we introduce RealInstruct, the first benchmark designed to evaluate LLMs' ability to follow real-world multi-constrained instructions by leveraging queries real users asked AI assistants. We also investigate model-based evaluation as a cost-effective alternative to human annotation for this task. Our findings reveal that even the proprietary GPT-4 model fails to meet at least one constraint on over 21% of instructions, highlighting the limitations of state-of-the-art models. To address the performance gap between open-source and proprietary models, we propose the Decompose, Critique and Refine (DeCRIM) self-correction pipeline, which enhances LLMs' ability to follow constraints. DeCRIM works by decomposing the original instruction into a list of constraints and using a Critic model to decide when and where the LLM's response needs refinement. Our results show that DeCRIM improves Mistral's performance by 7.3% on RealInstruct and 8.0% on IFEval even with weak feedback. Moreover, we demonstrate that with strong feedback, open-source LLMs with DeCRIM can outperform GPT-4 on both benchmarks.
Exploring Gender Bias in Retrieval Models
Aug 06, 2022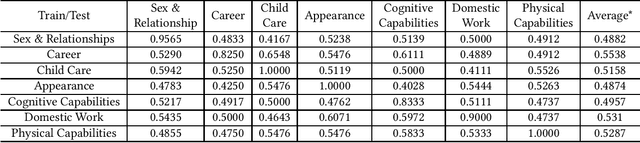
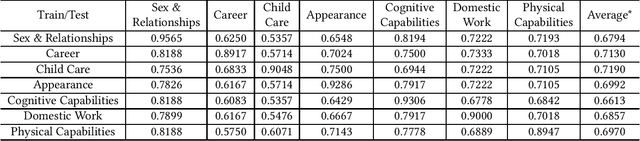

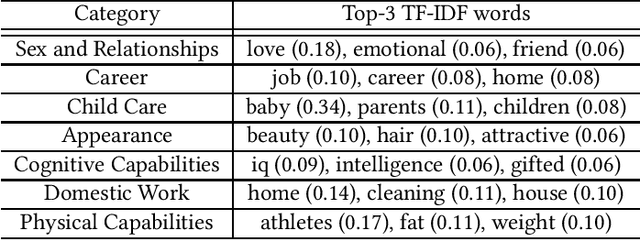
Biases in culture, gender, ethnicity, etc. have existed for decades and have affected many areas of human social interaction. These biases have been shown to impact machine learning (ML) models, and for natural language processing (NLP), this can have severe consequences for downstream tasks. Mitigating gender bias in information retrieval (IR) is important to avoid propagating stereotypes. In this work, we employ a dataset consisting of two components: (1) relevance of a document to a query and (2) "gender" of a document, in which pronouns are replaced by male, female, and neutral conjugations. We definitively show that pre-trained models for IR do not perform well in zero-shot retrieval tasks when full fine-tuning of a large pre-trained BERT encoder is performed and that lightweight fine-tuning performed with adapter networks improves zero-shot retrieval performance almost by 20% over baseline. We also illustrate that pre-trained models have gender biases that result in retrieved articles tending to be more often male than female. We overcome this by introducing a debiasing technique that penalizes the model when it prefers males over females, resulting in an effective model that retrieves articles in a balanced fashion across genders.
Number Entity Recognition
May 07, 2022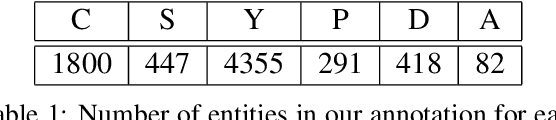
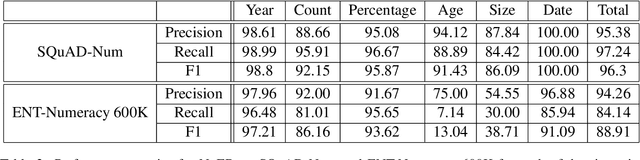

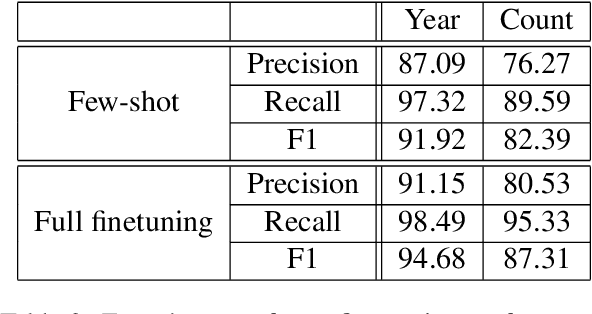
Numbers are essential components of text, like any other word tokens, from which natural language processing (NLP) models are built and deployed. Though numbers are typically not accounted for distinctly in most NLP tasks, there is still an underlying amount of numeracy already exhibited by NLP models. In this work, we attempt to tap this potential of state-of-the-art NLP models and transfer their ability to boost performance in related tasks. Our proposed classification of numbers into entities helps NLP models perform well on several tasks, including a handcrafted Fill-In-The-Blank (FITB) task and on question answering using joint embeddings, outperforming the BERT and RoBERTa baseline classification.
How do lexical semantics affect translation? An empirical study
Dec 31, 2021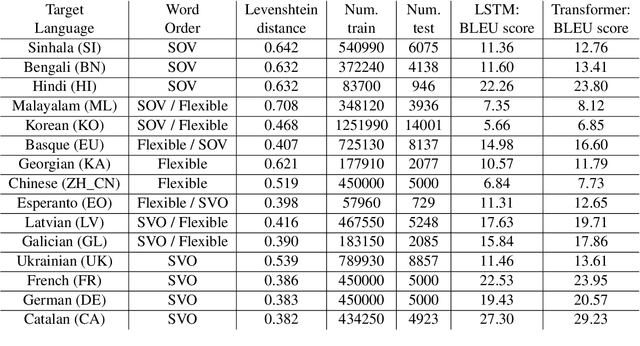
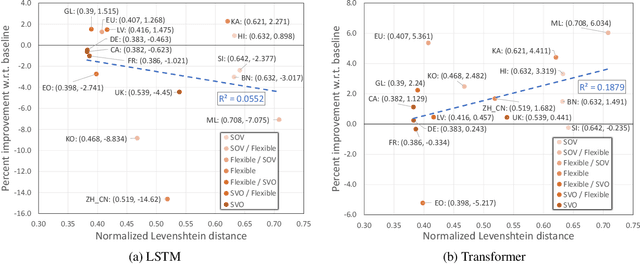
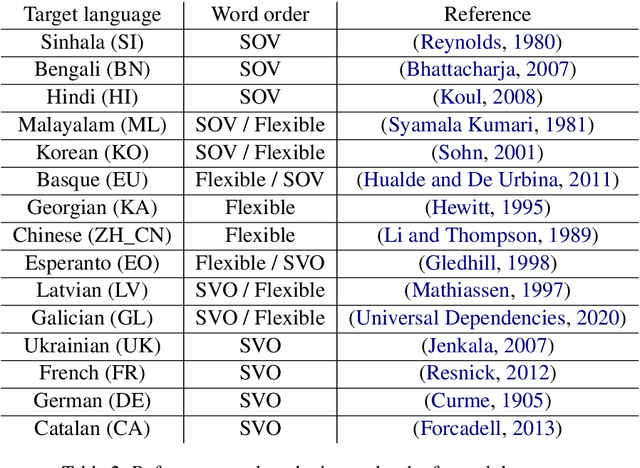
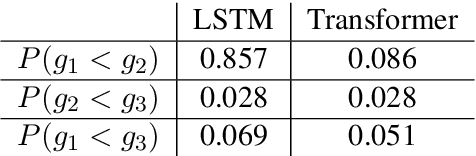
Neural machine translation (NMT) systems aim to map text from one language into another. While there are a wide variety of applications of NMT, one of the most important is translation of natural language. A distinguishing factor of natural language is that words are typically ordered according to the rules of the grammar of a given language. Although many advances have been made in developing NMT systems for translating natural language, little research has been done on understanding how the word ordering of and lexical similarity between the source and target language affect translation performance. Here, we investigate these relationships on a variety of low-resource language pairs from the OpenSubtitles2016 database, where the source language is English, and find that the more similar the target language is to English, the greater the translation performance. In addition, we study the impact of providing NMT models with part of speech of words (POS) in the English sequence and find that, for Transformer-based models, the more dissimilar the target language is from English, the greater the benefit provided by POS.
Graph Convolutional Networks Reveal Neural Connections Encoding Prosthetic Sensation
Aug 23, 2020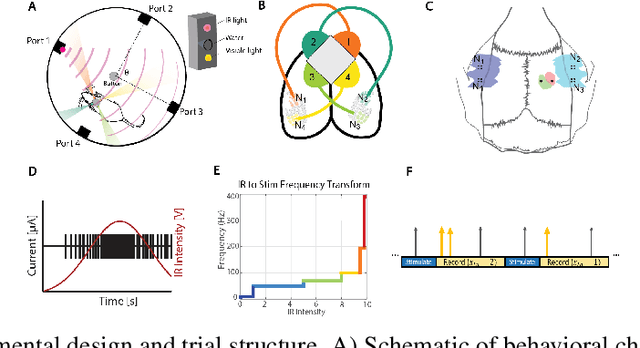
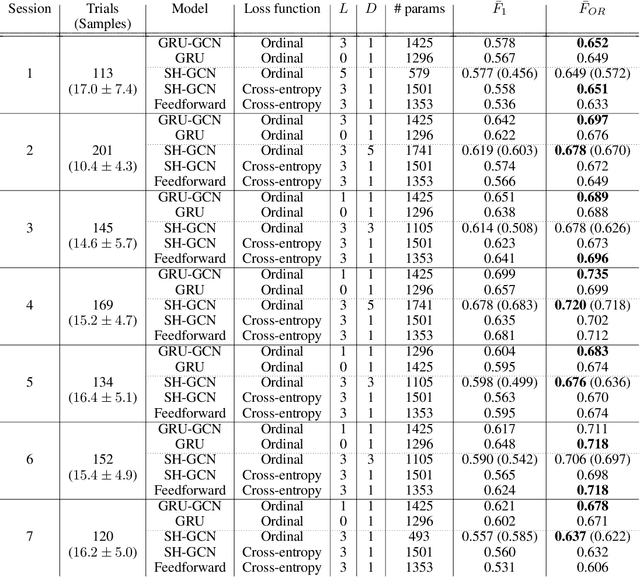
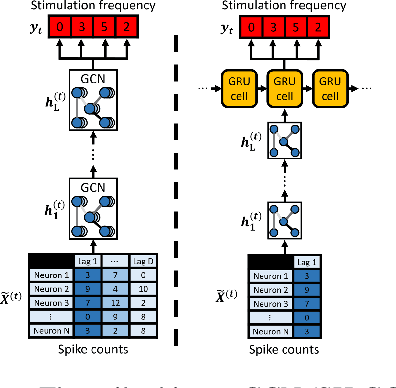
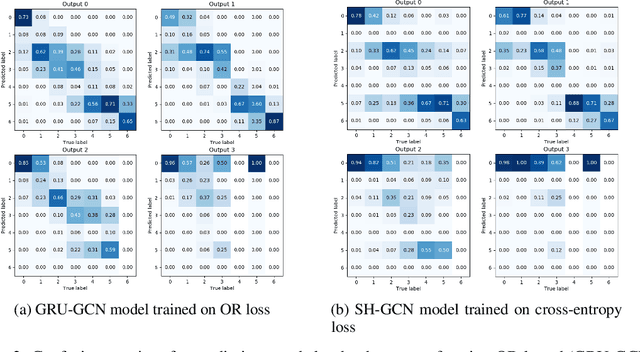
Extracting stimulus features from neuronal ensembles is of great interest to the development of neuroprosthetics that project sensory information directly to the brain via electrical stimulation. Machine learning strategies that optimize stimulation parameters as the subject learns to interpret the artificial input could improve device efficacy, increase prosthetic performance, ensure stability of evoked sensations, and improve power consumption by eliminating extraneous input. Recent advances extending deep learning techniques to non-Euclidean graph data provide a novel approach to interpreting neuronal spiking activity. For this study, we apply graph convolutional networks (GCNs) to infer the underlying functional relationship between neurons that are involved in the processing of artificial sensory information. Data was collected from a freely behaving rat using a four infrared (IR) sensor, ICMS-based neuroprosthesis to localize IR light sources. We use GCNs to predict the stimulation frequency across four stimulating channels in the prosthesis, which encode relative distance and directional information to an IR-emitting reward port. Our GCN model is able to achieve a peak performance of 73.5% on a modified ordinal regression performance metric in a multiclass classification problem consisting of 7 classes, where chance is 14.3%. Additionally, the inferred adjacency matrix provides a adequate representation of the underlying neural circuitry encoding the artificial sensation.
Syntax-Infused Transformer and BERT models for Machine Translation and Natural Language Understanding
Nov 10, 2019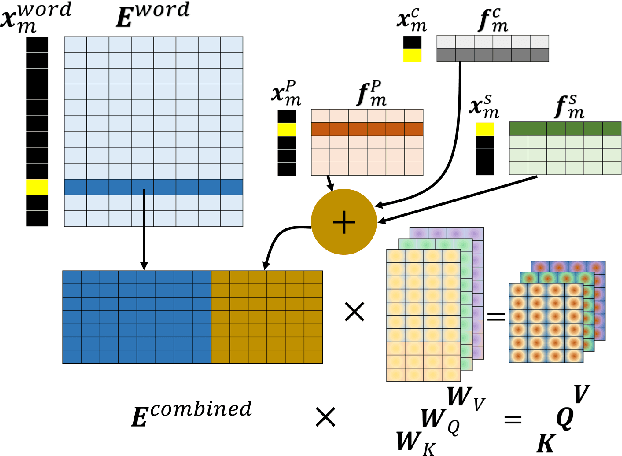
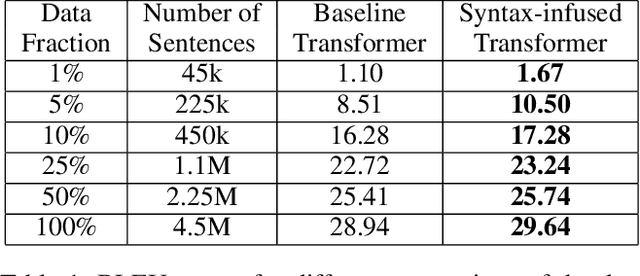
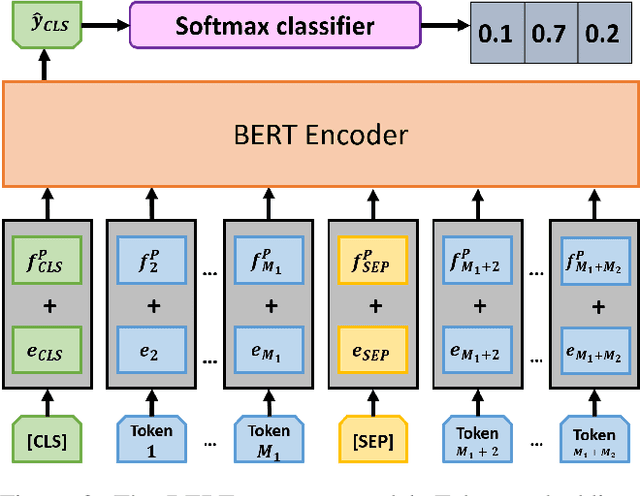

Attention-based models have shown significant improvement over traditional algorithms in several NLP tasks. The Transformer, for instance, is an illustrative example that generates abstract representations of tokens inputted to an encoder based on their relationships to all tokens in a sequence. Recent studies have shown that although such models are capable of learning syntactic features purely by seeing examples, explicitly feeding this information to deep learning models can significantly enhance their performance. Leveraging syntactic information like part of speech (POS) may be particularly beneficial in limited training data settings for complex models such as the Transformer. We show that the syntax-infused Transformer with multiple features achieves an improvement of 0.7 BLEU when trained on the full WMT 14 English to German translation dataset and a maximum improvement of 1.99 BLEU points when trained on a fraction of the dataset. In addition, we find that the incorporation of syntax into BERT fine-tuning outperforms baseline on a number of downstream tasks from the GLUE benchmark.