Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNumber Entity Recognition
Paper and Code
May 07, 2022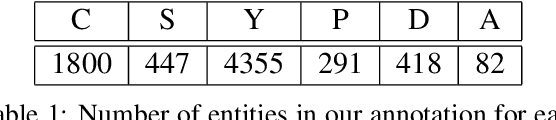
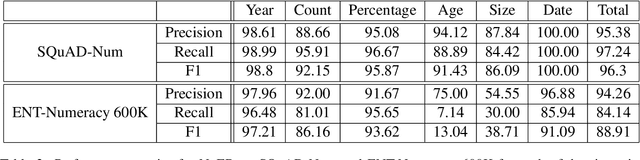

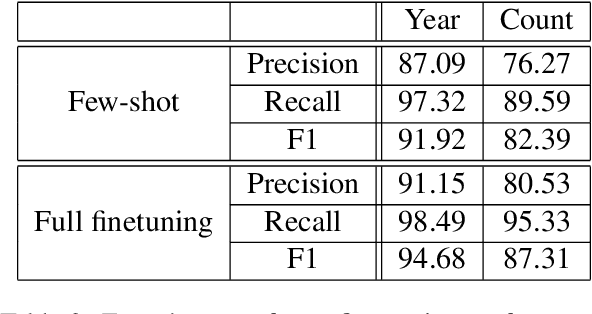
Numbers are essential components of text, like any other word tokens, from which natural language processing (NLP) models are built and deployed. Though numbers are typically not accounted for distinctly in most NLP tasks, there is still an underlying amount of numeracy already exhibited by NLP models. In this work, we attempt to tap this potential of state-of-the-art NLP models and transfer their ability to boost performance in related tasks. Our proposed classification of numbers into entities helps NLP models perform well on several tasks, including a handcrafted Fill-In-The-Blank (FITB) task and on question answering using joint embeddings, outperforming the BERT and RoBERTa baseline classification.
View paper on