 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Hallucination in Large Vision-Language Models based on Context-Aware Object Similarities
Jan 25, 2025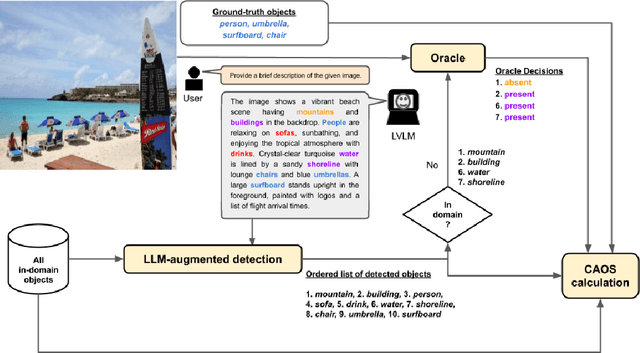
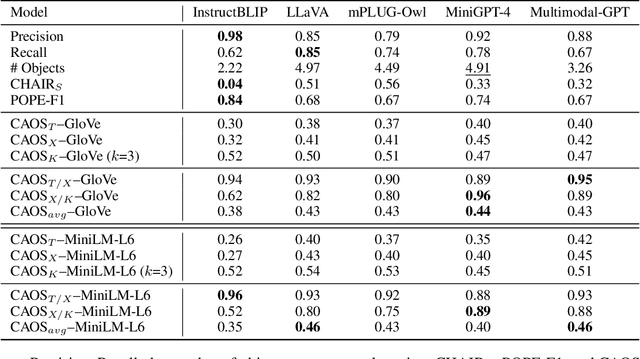
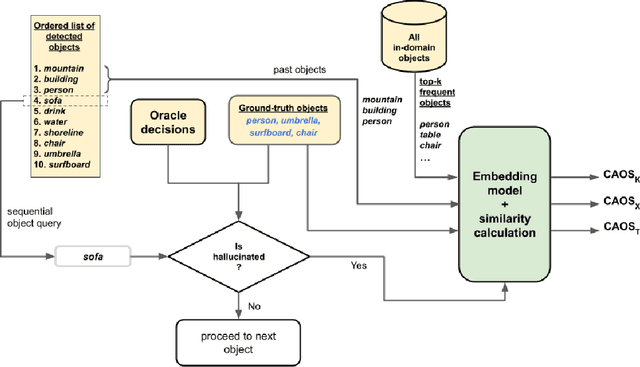
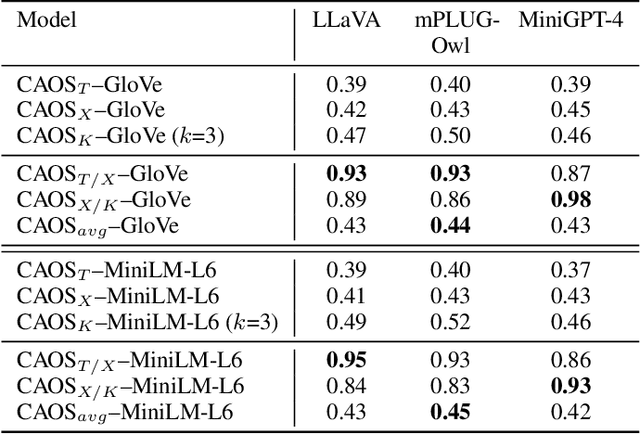
Despite their impressive performance on multi-modal tasks, large vision-language models (LVLMs) tend to suffer from hallucinations. An important type is object hallucination, where LVLMs generate objects that are inconsistent with the images shown to the model. Existing works typically attempt to quantify object hallucinations by detecting and measuring the fraction of hallucinated objects in generated captions. Additionally, more recent work also measures object hallucinations by directly querying the LVLM with binary questions about the presence of likely hallucinated objects based on object statistics like top-k frequent objects and top-k co-occurring objects. In this paper, we present Context-Aware Object Similarities (CAOS), a novel approach for evaluating object hallucination in LVLMs using object statistics as well as the generated captions. CAOS uniquely integrates object statistics with semantic relationships between objects in captions and ground-truth data. Moreover, existing approaches usually only detect and measure hallucinations belonging to a predetermined set of in-domain objects (typically the set of all ground-truth objects for the training dataset) and ignore generated objects that are not part of this set, leading to under-evaluation. To address this, we further employ language model--based object recognition to detect potentially out-of-domain hallucinated objects and use an ensemble of LVLMs for verifying the presence of such objects in the query image. CAOS also examines the sequential dynamics of object generation, shedding light on how the order of object appearance influences hallucinations, and employs word embedding models to analyze the semantic reasons behind hallucinations. CAOS aims to offer a nuanced understanding of the hallucination tendencies of LVLMs by providing a systematic framework to identify and interpret object hallucinations.
Pseudo-OOD training for robust language models
Oct 17, 2022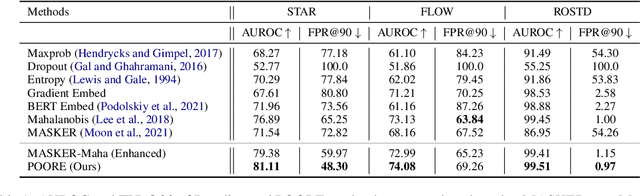

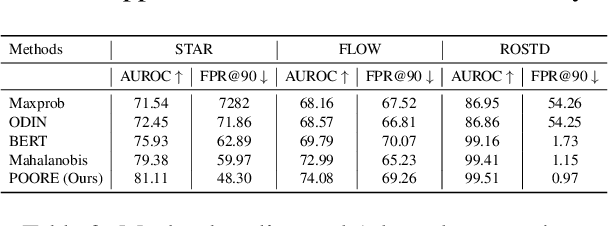

While pre-trained large-scale deep models have garnered attention as an important topic for many downstream natural language processing (NLP) tasks, such models often make unreliable predictions on out-of-distribution (OOD) inputs. As such, OOD detection is a key component of a reliable machine-learning model for any industry-scale application. Common approaches often assume access to additional OOD samples during the training stage, however, outlier distribution is often unknown in advance. Instead, we propose a post hoc framework called POORE - POsthoc pseudo-Ood REgularization, that generates pseudo-OOD samples using in-distribution (IND) data. The model is fine-tuned by introducing a new regularization loss that separates the embeddings of IND and OOD data, which leads to significant gains on the OOD prediction task during testing. We extensively evaluate our framework on three real-world dialogue systems, achieving new state-of-the-art in OOD detection.
Exploring Gender Bias in Retrieval Models
Aug 06, 2022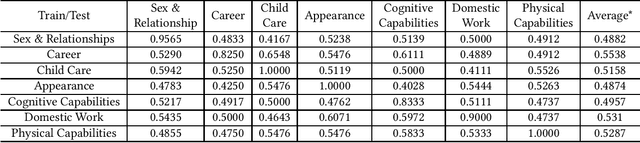
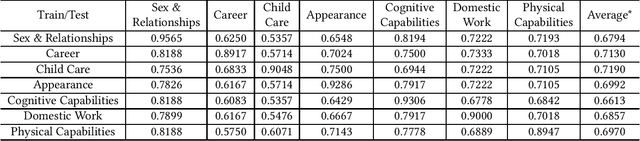

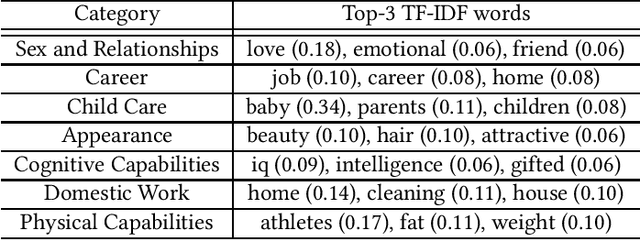
Biases in culture, gender, ethnicity, etc. have existed for decades and have affected many areas of human social interaction. These biases have been shown to impact machine learning (ML) models, and for natural language processing (NLP), this can have severe consequences for downstream tasks. Mitigating gender bias in information retrieval (IR) is important to avoid propagating stereotypes. In this work, we employ a dataset consisting of two components: (1) relevance of a document to a query and (2) "gender" of a document, in which pronouns are replaced by male, female, and neutral conjugations. We definitively show that pre-trained models for IR do not perform well in zero-shot retrieval tasks when full fine-tuning of a large pre-trained BERT encoder is performed and that lightweight fine-tuning performed with adapter networks improves zero-shot retrieval performance almost by 20% over baseline. We also illustrate that pre-trained models have gender biases that result in retrieved articles tending to be more often male than female. We overcome this by introducing a debiasing technique that penalizes the model when it prefers males over females, resulting in an effective model that retrieves articles in a balanced fashion across genders.
Number Entity Recognition
May 07, 2022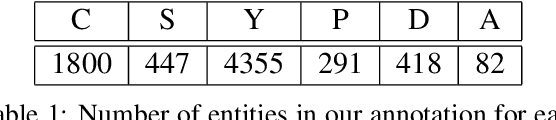
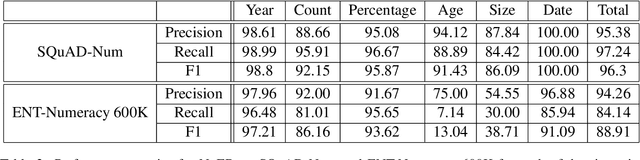

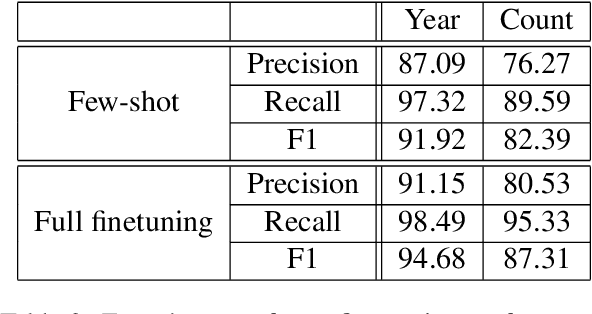
Numbers are essential components of text, like any other word tokens, from which natural language processing (NLP) models are built and deployed. Though numbers are typically not accounted for distinctly in most NLP tasks, there is still an underlying amount of numeracy already exhibited by NLP models. In this work, we attempt to tap this potential of state-of-the-art NLP models and transfer their ability to boost performance in related tasks. Our proposed classification of numbers into entities helps NLP models perform well on several tasks, including a handcrafted Fill-In-The-Blank (FITB) task and on question answering using joint embeddings, outperforming the BERT and RoBERTa baseline classification.
How do lexical semantics affect translation? An empirical study
Dec 31, 2021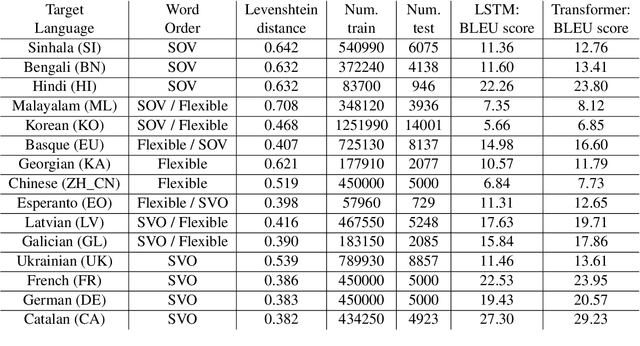
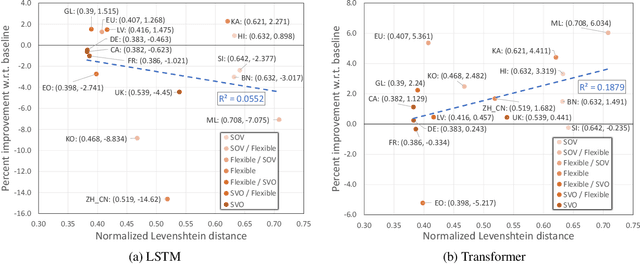
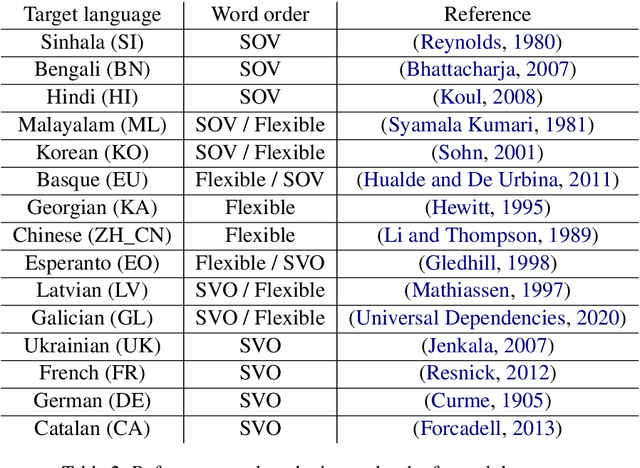
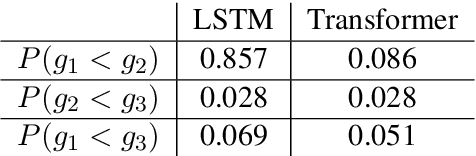
Neural machine translation (NMT) systems aim to map text from one language into another. While there are a wide variety of applications of NMT, one of the most important is translation of natural language. A distinguishing factor of natural language is that words are typically ordered according to the rules of the grammar of a given language. Although many advances have been made in developing NMT systems for translating natural language, little research has been done on understanding how the word ordering of and lexical similarity between the source and target language affect translation performance. Here, we investigate these relationships on a variety of low-resource language pairs from the OpenSubtitles2016 database, where the source language is English, and find that the more similar the target language is to English, the greater the translation performance. In addition, we study the impact of providing NMT models with part of speech of words (POS) in the English sequence and find that, for Transformer-based models, the more dissimilar the target language is from English, the greater the benefit provided by POS.
Syntax-Infused Transformer and BERT models for Machine Translation and Natural Language Understanding
Nov 10, 2019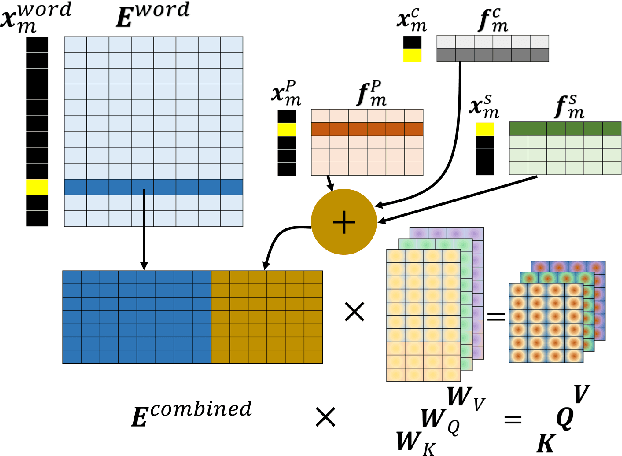
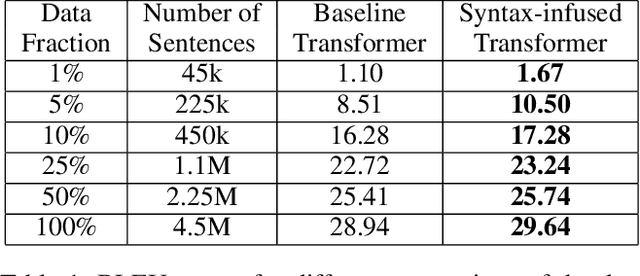
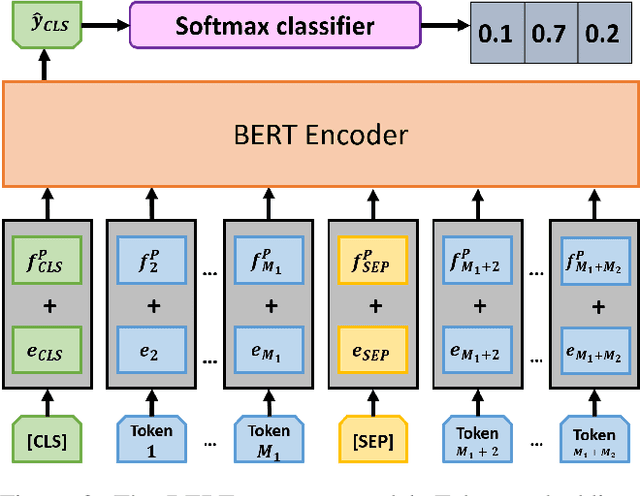

Attention-based models have shown significant improvement over traditional algorithms in several NLP tasks. The Transformer, for instance, is an illustrative example that generates abstract representations of tokens inputted to an encoder based on their relationships to all tokens in a sequence. Recent studies have shown that although such models are capable of learning syntactic features purely by seeing examples, explicitly feeding this information to deep learning models can significantly enhance their performance. Leveraging syntactic information like part of speech (POS) may be particularly beneficial in limited training data settings for complex models such as the Transformer. We show that the syntax-infused Transformer with multiple features achieves an improvement of 0.7 BLEU when trained on the full WMT 14 English to German translation dataset and a maximum improvement of 1.99 BLEU points when trained on a fraction of the dataset. In addition, we find that the incorporation of syntax into BERT fine-tuning outperforms baseline on a number of downstream tasks from the GLUE benchmark.
Learning Compressed Sentence Representations for On-Device Text Processing
Jun 19, 2019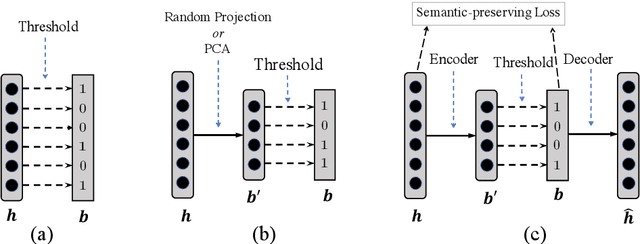
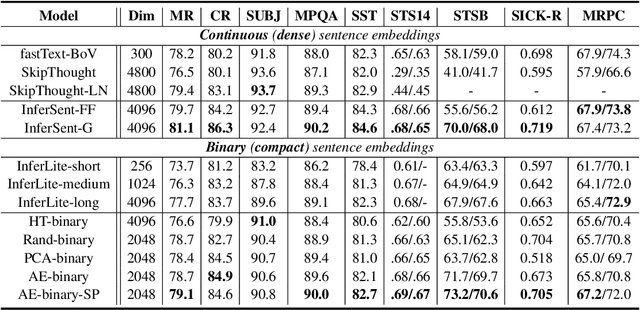

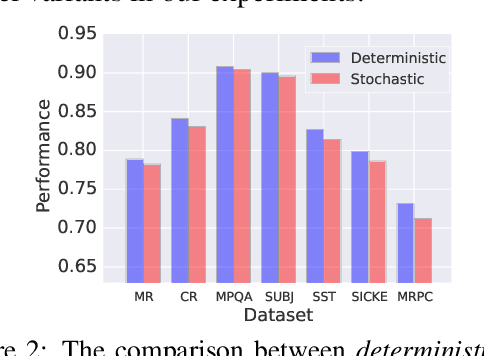
Vector representations of sentences, trained on massive text corpora, are widely used as generic sentence embeddings across a variety of NLP problems. The learned representations are generally assumed to be continuous and real-valued, giving rise to a large memory footprint and slow retrieval speed, which hinders their applicability to low-resource (memory and computation) platforms, such as mobile devices. In this paper, we propose four different strategies to transform continuous and generic sentence embeddings into a binarized form, while preserving their rich semantic information. The introduced methods are evaluated across a wide range of downstream tasks, where the binarized sentence embeddings are demonstrated to degrade performance by only about 2% relative to their continuous counterparts, while reducing the storage requirement by over 98%. Moreover, with the learned binary representations, the semantic relatedness of two sentences can be evaluated by simply calculating their Hamming distance, which is more computational efficient compared with the inner product operation between continuous embeddings. Detailed analysis and case study further validate the effectiveness of proposed methods.
How much is my car worth? A methodology for predicting used cars prices using Random Forest
Nov 19, 2017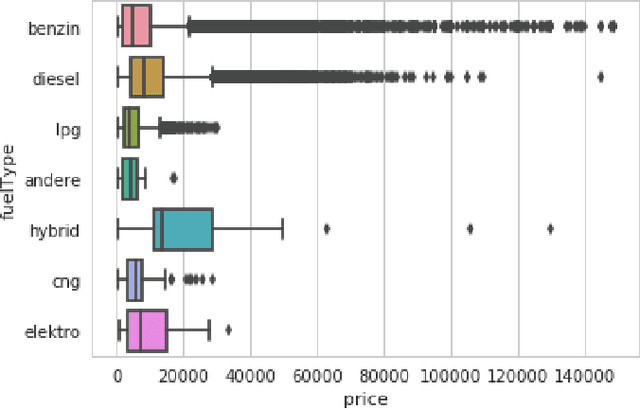
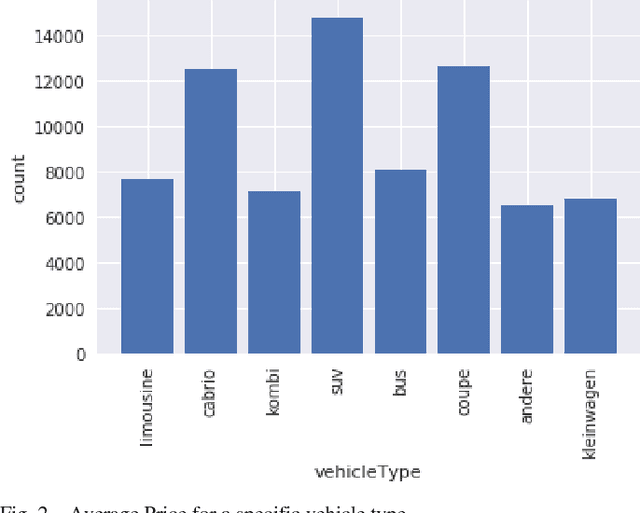
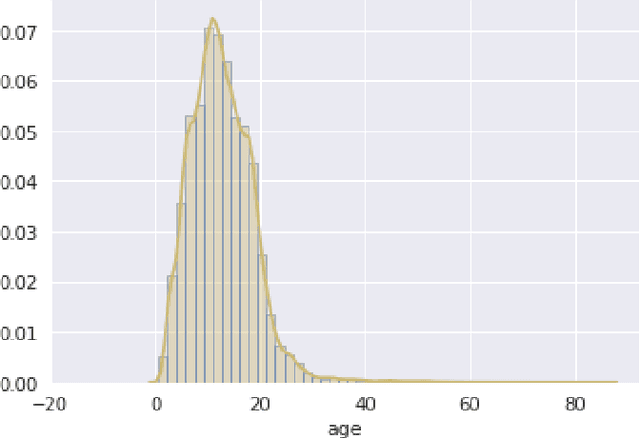
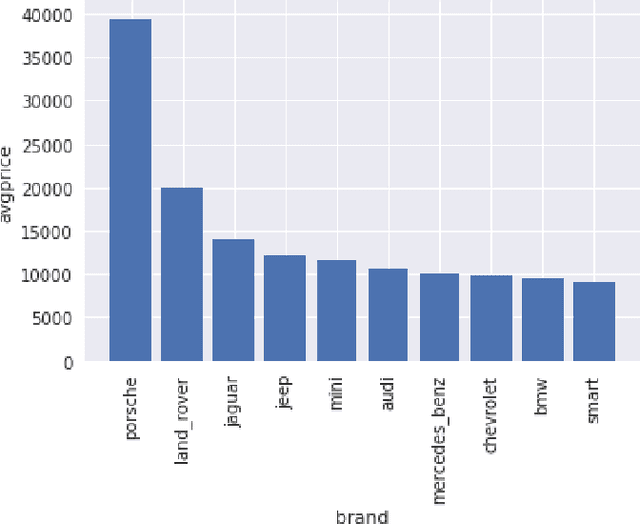
Cars are being sold more than ever. Developing countries adopt the lease culture instead of buying a new car due to affordability. Therefore, the rise of used cars sales is exponentially increasing. Car sellers sometimes take advantage of this scenario by listing unrealistic prices owing to the demand. Therefore, arises a need for a model that can assign a price for a vehicle by evaluating its features taking the prices of other cars into consideration. In this paper, we use supervised learning method namely Random Forest to predict the prices of used cars. The model has been chosen after careful exploratory data analysis to determine the impact of each feature on price. A Random Forest with 500 Decision Trees were created to train the data. From experimental results, the training accuracy was found out to be 95.82%, and the testing accuracy was 83.63%. The the model can predict the price of cars accurately by choosing the most correlated features.