 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiddenCut: Simple Data Augmentation for Natural Language Understanding with Better Generalization
May 31, 2021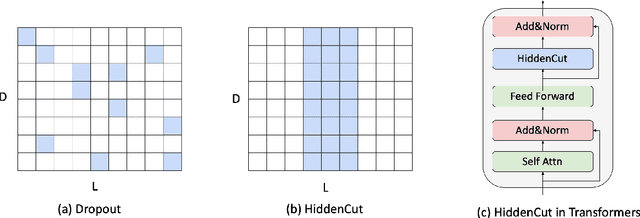
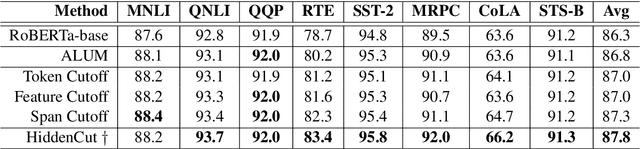

Fine-tuning large pre-trained models with task-specific data has achieved great success in NLP. However, it has been demonstrated that the majority of information within the self-attention networks is redundant and not utilized effectively during the fine-tuning stage. This leads to inferior results when generalizing the obtained models to out-of-domain distributions. To this end, we propose a simple yet effective data augmentation technique, HiddenCut, to better regularize the model and encourage it to learn more generalizable features. Specifically, contiguous spans within the hidden space are dynamically and strategically dropped during training. Experiments show that our HiddenCut method outperforms the state-of-the-art augmentation methods on the GLUE benchmark, and consistently exhibits superior generalization performances on out-of-distribution and challenging counterexamples. We have publicly released our code at https://github.com/GT-SALT/HiddenCut.
What Makes Good In-Context Examples for GPT-$3$?
Jan 17, 2021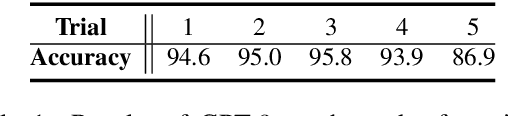
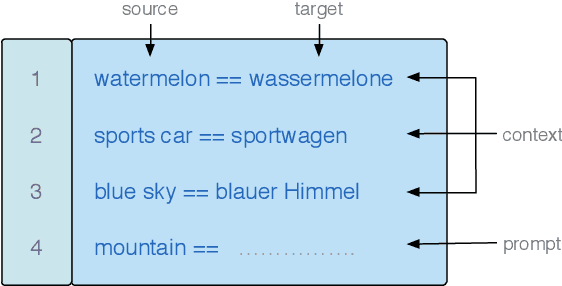
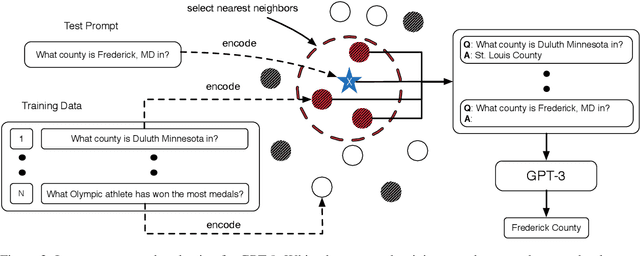
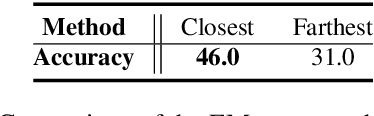
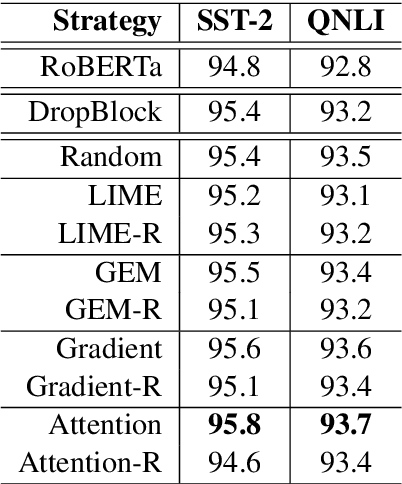
GPT-$3$ has attracted lots of attention due to its superior performance across a wide range of NLP tasks, especially with its powerful and versatile in-context few-shot learning ability. Despite its success, we found that the empirical results of GPT-$3$ depend heavily on the choice of in-context examples. In this work, we investigate whether there are more effective strategies for judiciously selecting in-context examples (relative to random sampling) that better leverage GPT-$3$'s few-shot capabilities. Inspired by the recent success of leveraging a retrieval module to augment large-scale neural network models, we propose to retrieve examples that are semantically-similar to a test sample to formulate its corresponding prompt. Intuitively, the in-context examples selected with such a strategy may serve as more informative inputs to unleash GPT-$3$'s extensive knowledge. We evaluate the proposed approach on several natural language understanding and generation benchmarks, where the retrieval-based prompt selection approach consistently outperforms the random baseline. Moreover, it is observed that the sentence encoders fine-tuned on task-related datasets yield even more helpful retrieval results. Notably, significant gains are observed on tasks such as table-to-text generation (41.9% on the ToTTo dataset) and open-domain question answering (45.5% on the NQ dataset). We hope our investigation could help understand the behaviors of GPT-$3$ and large-scale pre-trained LMs in general and enhance their few-shot capabilities.
MixKD: Towards Efficient Distillation of Large-scale Language Models
Nov 01, 2020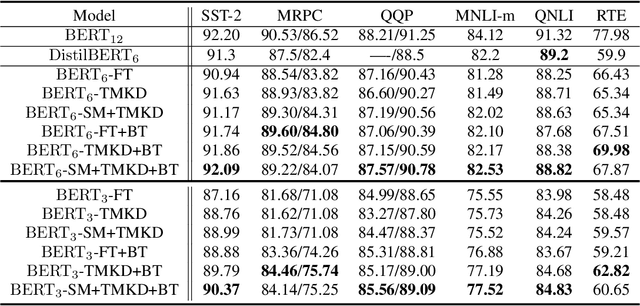
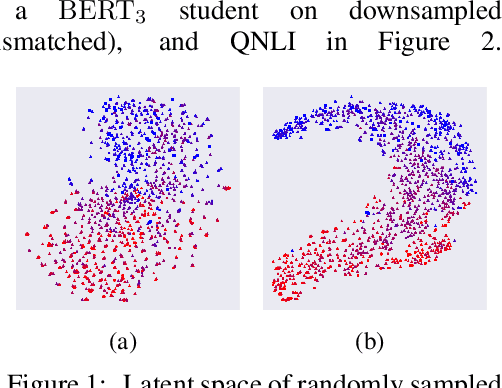
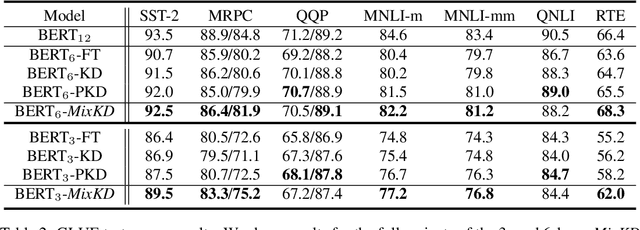
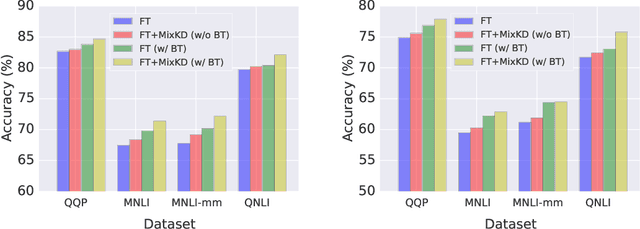
Large-scale language models have recently demonstrated impressive empirical performance. Nevertheless, the improved results are attained at the price of bigger models, more power consumption, and slower inference, which hinder their applicability to low-resource (memory and computation) platforms. Knowledge distillation (KD) has been demonstrated as an effective framework for compressing such big models. However, large-scale neural network systems are prone to memorize training instances, and thus tend to make inconsistent predictions when the data distribution is altered slightly. Moreover, the student model has few opportunities to request useful information from the teacher model when there is limited task-specific data available. To address these issues, we propose MixKD, a data-agnostic distillation framework that leverages mixup, a simple yet efficient data augmentation approach, to endow the resulting model with stronger generalization ability. Concretely, in addition to the original training examples, the student model is encouraged to mimic the teacher's behavior on the linear interpolation of example pairs as well. We prove, from a theoretical perspective, that under reasonable conditions MixKD gives rise to a smaller gap between the generalization error and the empirical error. To verify its effectiveness, we conduct experiments on the GLUE benchmark, where MixKD consistently leads to significant gains over the standard KD training, and outperforms several competitive baselines. Experiments under a limited-data setting and ablation studies further demonstrate the advantages of the proposed approach.
A Simple but Tough-to-Beat Data Augmentation Approach for Natural Language Understanding and Generation
Oct 23, 2020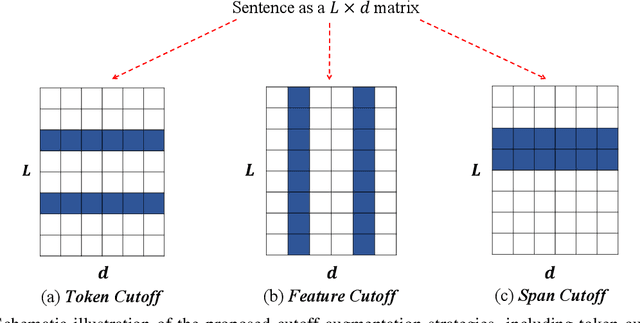
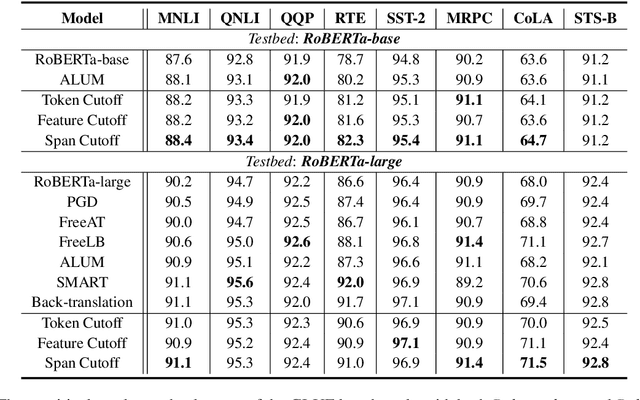

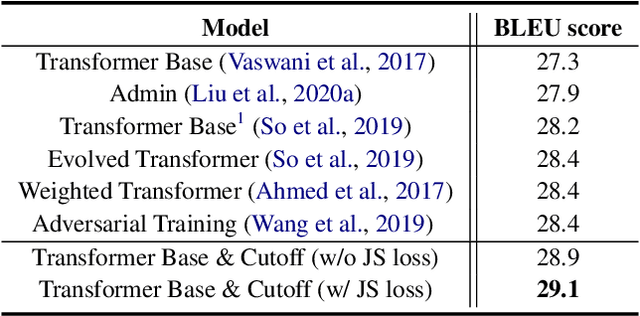
Adversarial training has been shown effective at endowing the learned representations with stronger generalization ability. However, it typically requires expensive computation to determine the direction of the injected perturbations. In this paper, we introduce a set of simple yet effective data augmentation strategies dubbed cutoff, where part of the information within an input sentence is erased to yield its restricted views (during the fine-tuning stage). Notably, this process relies merely on stochastic sampling and thus adds little computational overhead. A Jensen-Shannon Divergence consistency loss is further utilized to incorporate these augmented samples into the training objective in a principled manner. To verify the effectiveness of the proposed strategies, we apply cutoff to both natural language understanding and generation problems. On the GLUE benchmark, it is demonstrated that cutoff, in spite of its simplicity, performs on par or better than several competitive adversarial-based approaches. We further extend cutoff to machine translation and observe significant gains in BLEU scores (based upon the Transformer Base model). Moreover, cutoff consistently outperforms adversarial training and achieves state-of-the-art results on the IWSLT2014 German-English dataset.
CoDA: Contrast-enhanced and Diversity-promoting Data Augmentation for Natural Language Understanding
Oct 16, 2020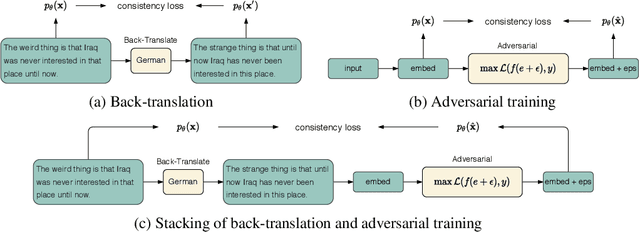
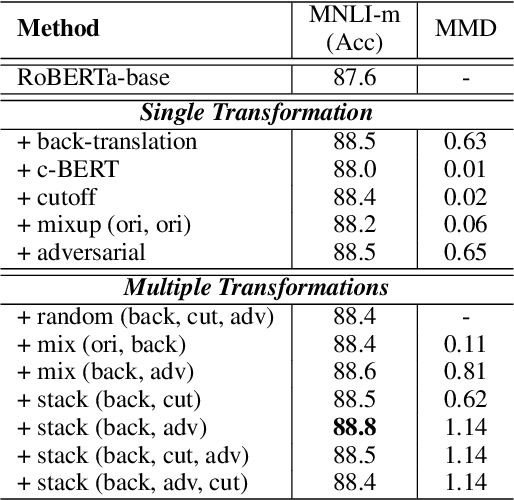

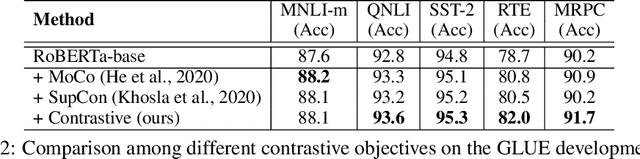
Data augmentation has been demonstrated as an effective strategy for improving model generalization and data efficiency. However, due to the discrete nature of natural language, designing label-preserving transformations for text data tends to be more challenging. In this paper, we propose a novel data augmentation framework dubbed CoDA, which synthesizes diverse and informative augmented examples by integrating multiple transformations organically. Moreover, a contrastive regularization objective is introduced to capture the global relationship among all the data samples. A momentum encoder along with a memory bank is further leveraged to better estimate the contrastive loss. To verify the effectiveness of the proposed framework, we apply CoDA to Transformer-based models on a wide range of natural language understanding tasks. On the GLUE benchmark, CoDA gives rise to an average improvement of 2.2% while applied to the RoBERTa-large model. More importantly, it consistently exhibits stronger results relative to several competitive data augmentation and adversarial training base-lines (including the low-resource settings). Extensive experiments show that the proposed contrastive objective can be flexibly combined with various data augmentation approaches to further boost their performance, highlighting the wide applicability of the CoDA framework.
Improving Self-supervised Pre-training via a Fully-Explored Masked Language Model
Oct 14, 2020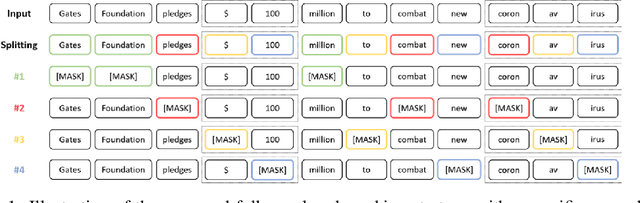
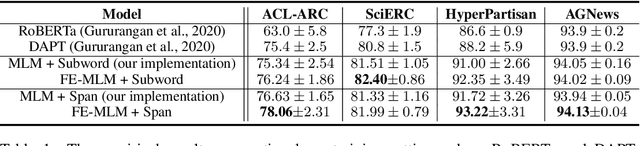
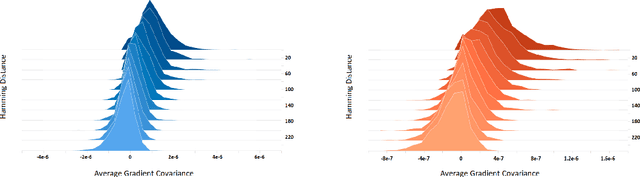

Masked Language Model (MLM) framework has been widely adopted for self-supervised language pre-training. In this paper, we argue that randomly sampled masks in MLM would lead to undesirably large gradient variance. Thus, we theoretically quantify the gradient variance via correlating the gradient covariance with the Hamming distance between two different masks (given a certain text sequence). To reduce the variance due to the sampling of masks, we propose a fully-explored masking strategy, where a text sequence is divided into a certain number of non-overlapping segments. Thereafter, the tokens within one segment are masked for training. We prove, from a theoretical perspective, that the gradients derived from this new masking schema have a smaller variance and can lead to more efficient self-supervised training. We conduct extensive experiments on both continual pre-training and general pre-training from scratch. Empirical results confirm that this new masking strategy can consistently outperform standard random masking. Detailed efficiency analysis and ablation studies further validate the advantages of our fully-explored masking strategy under the MLM framework.
Improving Text Generation with Student-Forcing Optimal Transport
Oct 12, 2020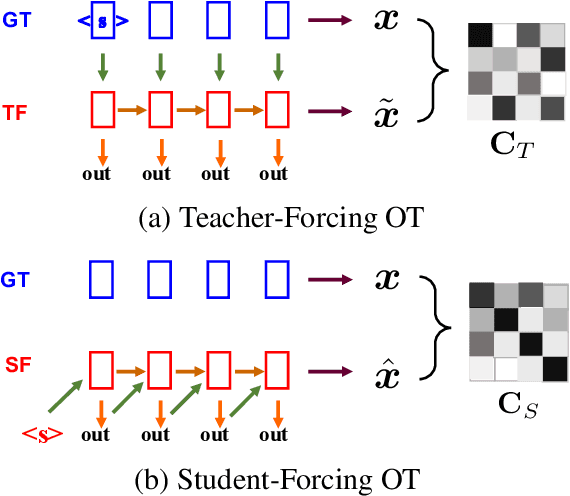
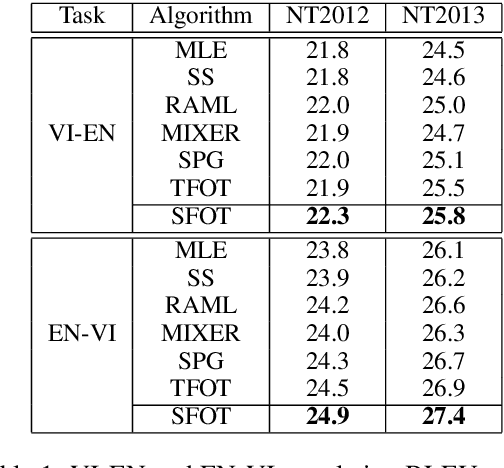
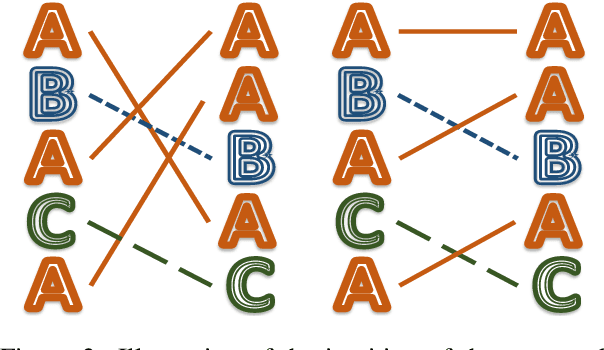
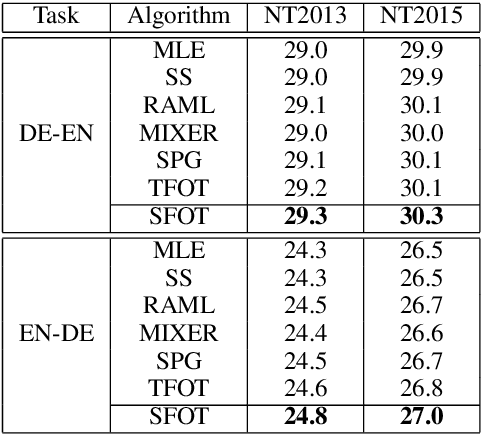
Neural language models are often trained with maximum likelihood estimation (MLE), where the next word is generated conditioned on the ground-truth word tokens. During testing, however, the model is instead conditioned on previously generated tokens, resulting in what is termed exposure bias. To reduce this gap between training and testing, we propose using optimal transport (OT) to match the sequences generated in these two modes. An extension is further proposed to improve the OT learning, based on the structural and contextual information of the text sequences. The effectiveness of the proposed method is validated on machine translation, text summarization, and text generation tasks.
Generative Semantic Hashing Enhanced via Boltzmann Machines
Jun 16, 2020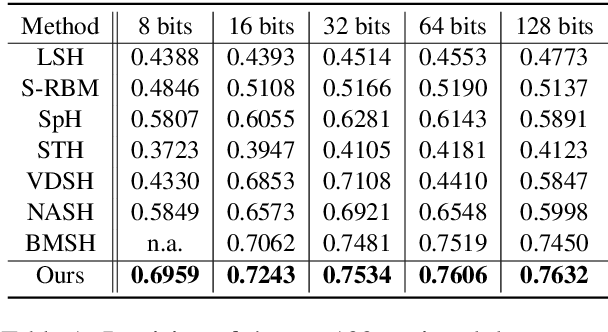
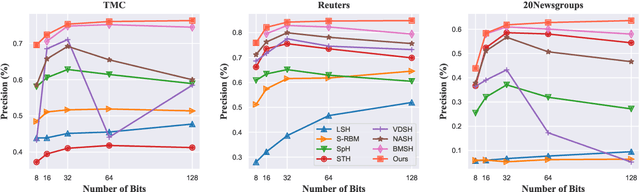
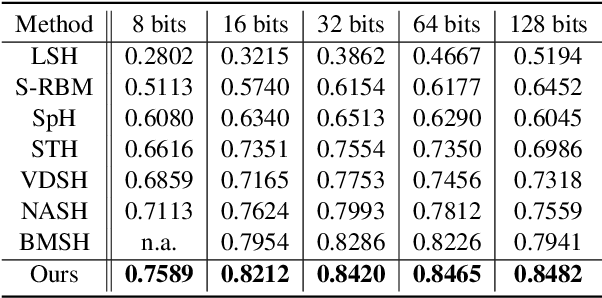

Generative semantic hashing is a promising technique for large-scale information retrieval thanks to its fast retrieval speed and small memory footprint. For the tractability of training, existing generative-hashing methods mostly assume a factorized form for the posterior distribution, enforcing independence among the bits of hash codes. From the perspectives of both model representation and code space size, independence is always not the best assumption. In this paper, to introduce correlations among the bits of hash codes, we propose to employ the distribution of Boltzmann machine as the variational posterior. To address the intractability issue of training, we first develop an approximate method to reparameterize the distribution of a Boltzmann machine by augmenting it as a hierarchical concatenation of a Gaussian-like distribution and a Bernoulli distribution. Based on that, an asymptotically-exact lower bound is further derived for the evidence lower bound (ELBO). With these novel techniques, the entire model can be optimized efficiently. Extensive experimental results demonstrate that by effectively modeling correlations among different bits within a hash code, our model can achieve significant performance gains.
Improving Disentangled Text Representation Learning with Information-Theoretic Guidance
Jun 06, 2020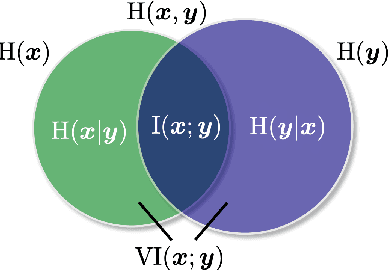
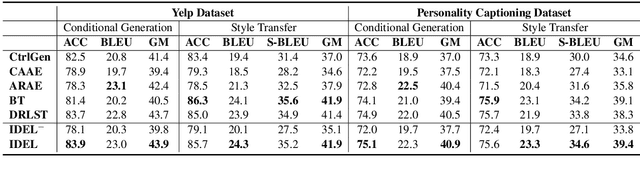
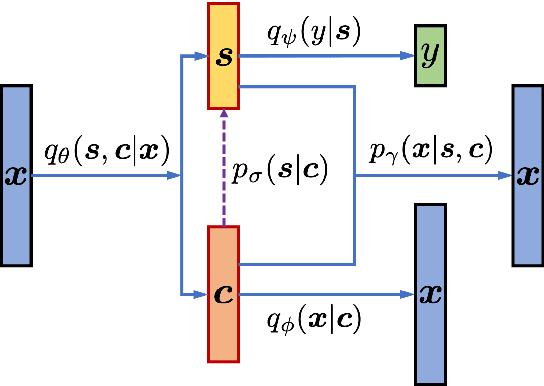
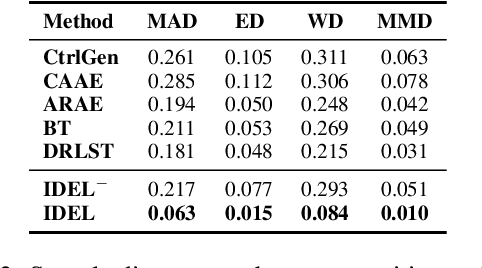
Learning disentangled representations of natural language is essential for many NLP tasks, e.g., conditional text generation, style transfer, personalized dialogue systems, etc. Similar problems have been studied extensively for other forms of data, such as images and videos. However, the discrete nature of natural language makes the disentangling of textual representations more challenging (e.g., the manipulation over the data space cannot be easily achieved). Inspired by information theory, we propose a novel method that effectively manifests disentangled representations of text, without any supervision on semantics. A new mutual information upper bound is derived and leveraged to measure dependence between style and content. By minimizing this upper bound, the proposed method induces style and content embeddings into two independent low-dimensional spaces. Experiments on both conditional text generation and text-style transfer demonstrate the high quality of our disentangled representation in terms of content and style preservation.
Improving Adversarial Text Generation by Modeling the Distant Future
May 04, 2020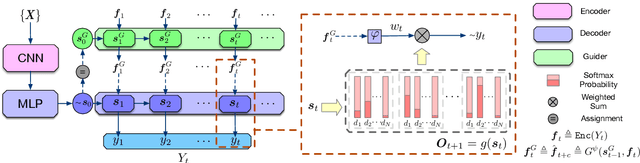

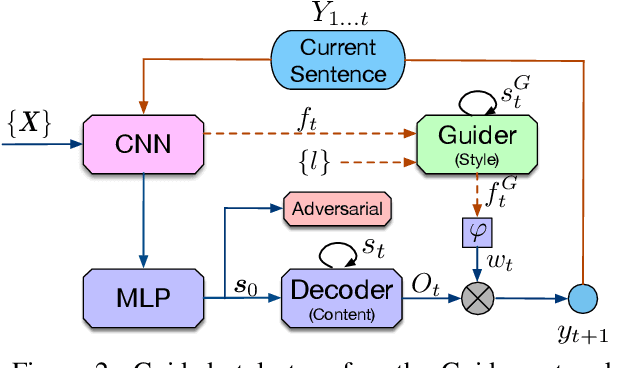
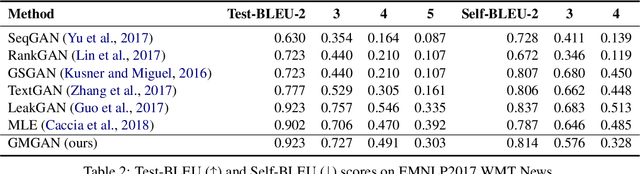
Auto-regressive text generation models usually focus on local fluency, and may cause inconsistent semantic meaning in long text generation. Further, automatically generating words with similar semantics is challenging, and hand-crafted linguistic rules are difficult to apply. We consider a text planning scheme and present a model-based imitation-learning approach to alleviate the aforementioned issues. Specifically, we propose a novel guider network to focus on the generative process over a longer horizon, which can assist next-word prediction and provide intermediate rewards for generator optimization. Extensive experiments demonstrate that the proposed method leads to improved performance.