 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Text Generation with Student-Forcing Optimal Transport
Oct 12, 2020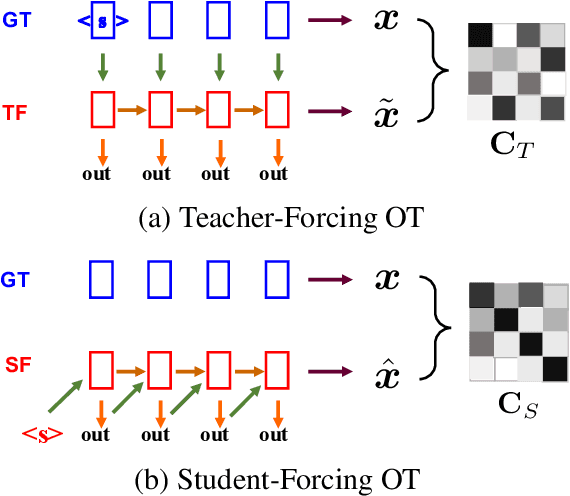
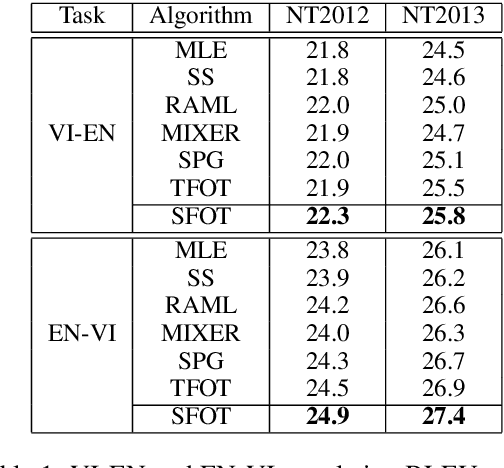
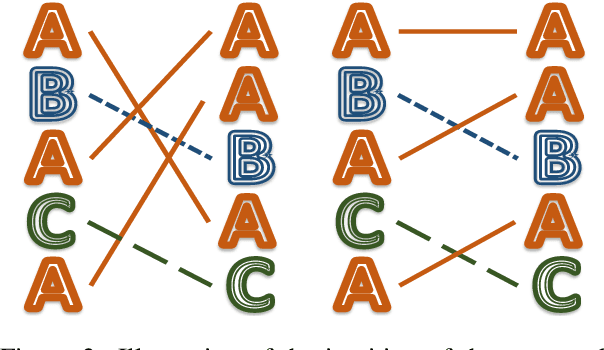
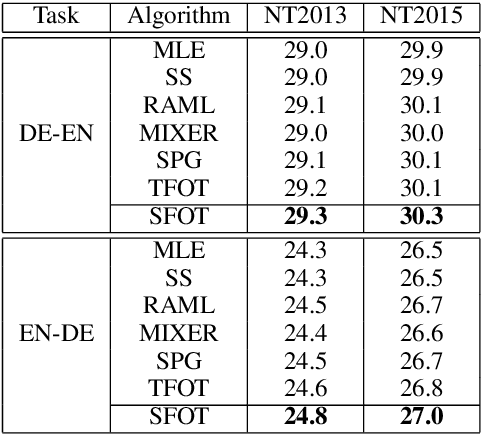
Neural language models are often trained with maximum likelihood estimation (MLE), where the next word is generated conditioned on the ground-truth word tokens. During testing, however, the model is instead conditioned on previously generated tokens, resulting in what is termed exposure bias. To reduce this gap between training and testing, we propose using optimal transport (OT) to match the sequences generated in these two modes. An extension is further proposed to improve the OT learning, based on the structural and contextual information of the text sequences. The effectiveness of the proposed method is validated on machine translation, text summarization, and text generation tasks.
GO Hessian for Expectation-Based Objectives
Jun 16, 2020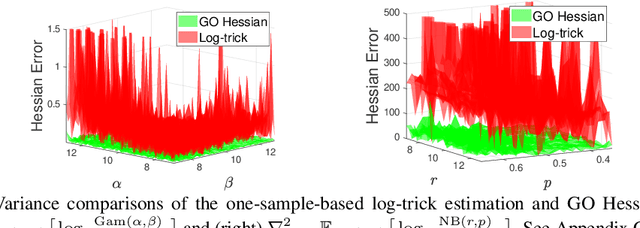

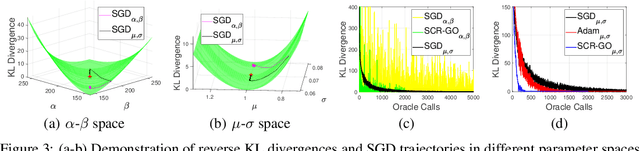
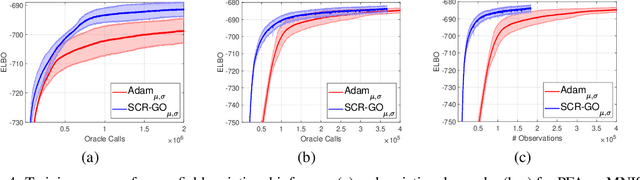
An unbiased low-variance gradient estimator, termed GO gradient, was proposed recently for expectation-based objectives $\mathbb{E}_{q_{\boldsymbol{\gamma}}(\boldsymbol{y})} [f(\boldsymbol{y})]$, where the random variable (RV) $\boldsymbol{y}$ may be drawn from a stochastic computation graph with continuous (non-reparameterizable) internal nodes and continuous/discrete leaves. Upgrading the GO gradient, we present for $\mathbb{E}_{q_{\boldsymbol{\boldsymbol{\gamma}}}(\boldsymbol{y})} [f(\boldsymbol{y})]$ an unbiased low-variance Hessian estimator, named GO Hessian. Considering practical implementation, we reveal that GO Hessian is easy-to-use with auto-differentiation and Hessian-vector products, enabling efficient cheap exploitation of curvature information over stochastic computation graphs. As representative examples, we present the GO Hessian for non-reparameterizable gamma and negative binomial RVs/nodes. Based on the GO Hessian, we design a new second-order method for $\mathbb{E}_{q_{\boldsymbol{\boldsymbol{\gamma}}}(\boldsymbol{y})} [f(\boldsymbol{y})]$, with rigorous experiments conducted to verify its effectiveness and efficiency.
GAN Memory with No Forgetting
Jun 13, 2020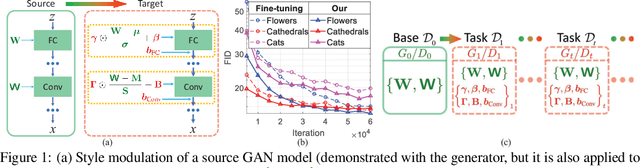



Seeking to address the fundamental issue of memory in lifelong learning, we propose a GAN memory that is capable of realistically remembering a stream of generative processes with \emph{no} forgetting. Our GAN memory is based on recognizing that one can modulate the ``style'' of a GAN model to form perceptually-distant targeted generation. Accordingly, we propose to do sequential style modulations atop a well-behaved base GAN model, to form sequential targeted generative models, while simultaneously benefiting from the transferred base knowledge. Experiments demonstrate the superiority of our method over existing approaches and its effectiveness in alleviating catastrophic forgetting for lifelong classification problems.
Adversarial Learning of a Sampler Based on an Unnormalized Distribution
Jan 03, 2019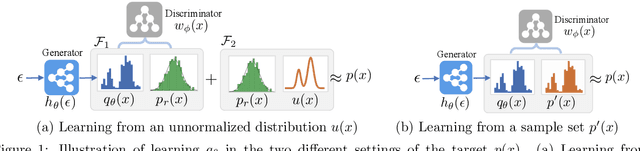
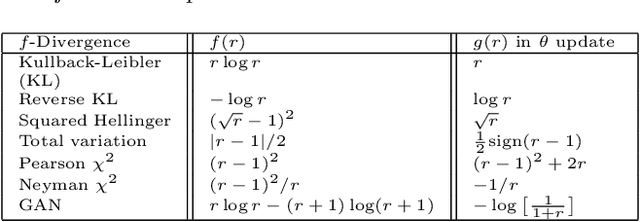
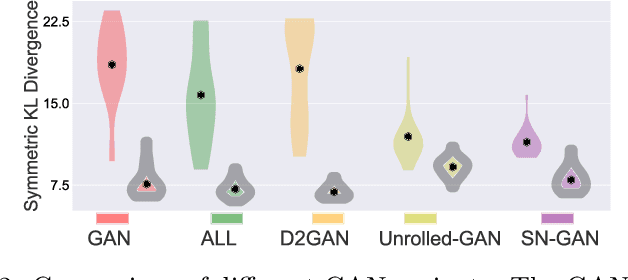
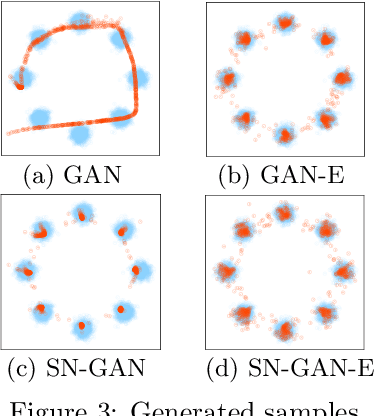
We investigate adversarial learning in the case when only an unnormalized form of the density can be accessed, rather than samples. With insights so garnered, adversarial learning is extended to the case for which one has access to an unnormalized form u(x) of the target density function, but no samples. Further, new concepts in GAN regularization are developed, based on learning from samples or from u(x). The proposed method is compared to alternative approaches, with encouraging results demonstrated across a range of applications, including deep soft Q-learning.