 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTARQ: Tail-Aware Reconstruction Quantization for Rare-Word Robust Automatic Speech Recognition
May 27, 2026Data-aware post-training quantization (PTQ) minimizes a per-token reconstruction loss on a small calibration corpus, implicitly weighting positions by their empirical frequency. For \textbf{A}utomatic \textbf{S}peech \textbf{R}ecognition (ASR), this misaligns with tail-sensitive risk: names, numerals, and domain-specific words receive proportionally little calibration mass. We propose \textbf{Tail-Aware Reconstruction Quantization} (\TARQ), a label-free PTQ framework that shifts calibration toward the lexical tail via \textbf{\rareBAL}, a closed-form per-Linear-layer rule equalizing common/tail mass, paired with a metric-consistent residual correction. \TARQ\ requires no entity labels, no curated calibration set, no validation decoding, and no additional training. Across eight ASR backbones and six datasets at W4G128, \TARQ\ improves mean rare-\textbf{W}ord \textbf{E}rror \textbf{R}ate (rare-WER) without an aggregate-WER regression, achieves the lowest cross-corpus rare-WER swing among compared methods, and transfers to entity-rich benchmarks (ProfASR, ContextASR-Speech-En) without entity supervision.
Everyone Deserves A Reward: Learning Customized Human Preferences
Sep 15, 2023Reward models (RMs) are essential for aligning large language models (LLMs) with human preferences to improve interaction quality. However, the real world is pluralistic, which leads to diversified human preferences with respect to different religions, politics, cultures, etc. Moreover, each individual can have their unique preferences on various topics. Neglecting the diversity of human preferences, current human feedback aligning methods only consider a general reward model, which is below satisfaction for customized or personalized application scenarios. To explore customized preference learning, we collect a domain-specific preference (DSP) dataset, which includes preferred responses for each given query from four practical domains. Besides, from the perspective of data efficiency, we propose a three-stage customized RM learning scheme, then empirically verify its effectiveness on both general preference datasets and our DSP set. Furthermore, we test multiple training and data strategies on the three learning stages. We find several ways to better preserve the general preferring ability while training the customized RMs, especially general preference enrichment, and customized preference imitation learning. The DSP dataset and code are available at https://github.com/Linear95/DSP.
Open World Classification with Adaptive Negative Samples
Mar 09, 2023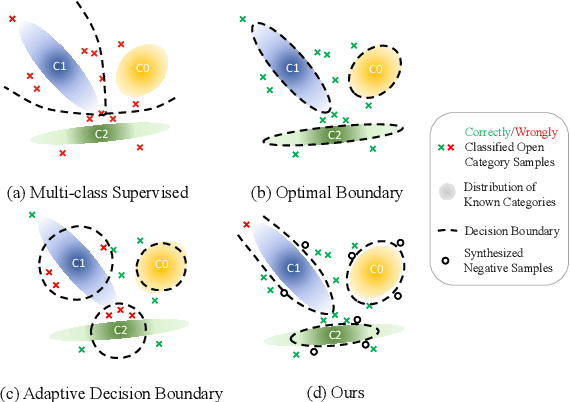
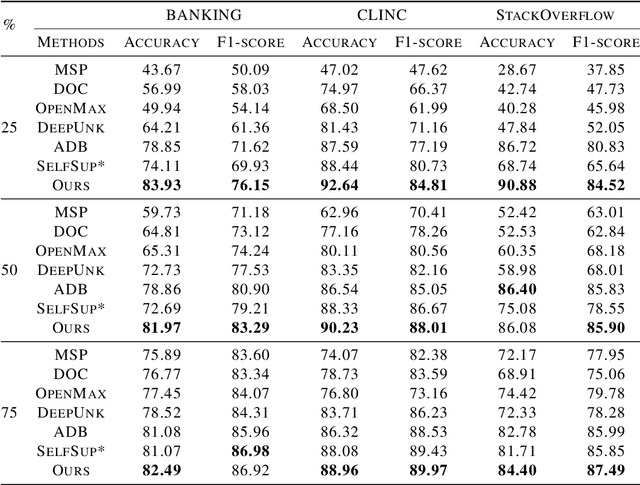
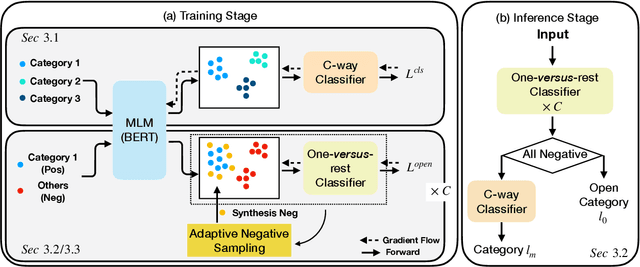
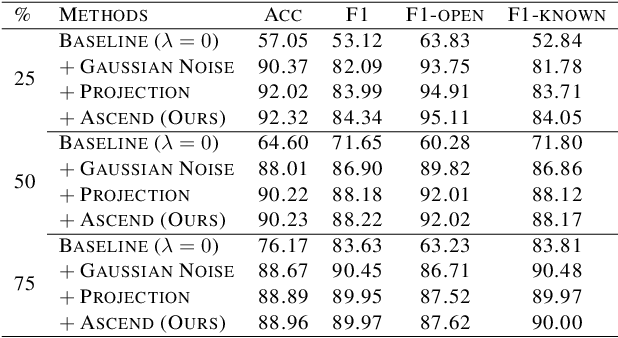
Open world classification is a task in natural language processing with key practical relevance and impact. Since the open or {\em unknown} category data only manifests in the inference phase, finding a model with a suitable decision boundary accommodating for the identification of known classes and discrimination of the open category is challenging. The performance of existing models is limited by the lack of effective open category data during the training stage or the lack of a good mechanism to learn appropriate decision boundaries. We propose an approach based on \underline{a}daptive \underline{n}egative \underline{s}amples (ANS) designed to generate effective synthetic open category samples in the training stage and without requiring any prior knowledge or external datasets. Empirically, we find a significant advantage in using auxiliary one-versus-rest binary classifiers, which effectively utilize the generated negative samples and avoid the complex threshold-seeking stage in previous works. Extensive experiments on three benchmark datasets show that ANS achieves significant improvements over state-of-the-art methods.
Collaborative Anomaly Detection
Sep 20, 2022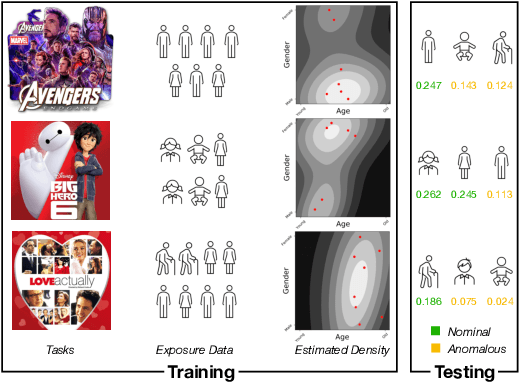
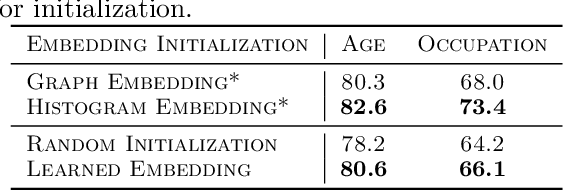

In recommendation systems, items are likely to be exposed to various users and we would like to learn about the familiarity of a new user with an existing item. This can be formulated as an anomaly detection (AD) problem distinguishing between "common users" (nominal) and "fresh users" (anomalous). Considering the sheer volume of items and the sparsity of user-item paired data, independently applying conventional single-task detection methods on each item quickly becomes difficult, while correlations between items are ignored. To address this multi-task anomaly detection problem, we propose collaborative anomaly detection (CAD) to jointly learn all tasks with an embedding encoding correlations among tasks. We explore CAD with conditional density estimation and conditional likelihood ratio estimation. We found that: $i$) estimating a likelihood ratio enjoys more efficient learning and yields better results than density estimation. $ii$) It is beneficial to select a small number of tasks in advance to learn a task embedding model, and then use it to warm-start all task embeddings. Consequently, these embeddings can capture correlations between tasks and generalize to new correlated tasks.
Variational Inference with Holder Bounds
Nov 13, 2021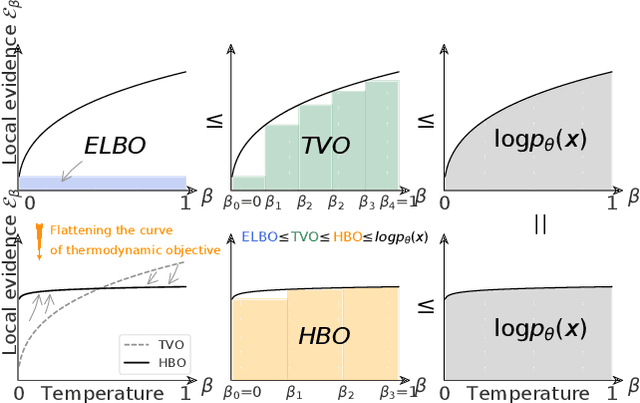
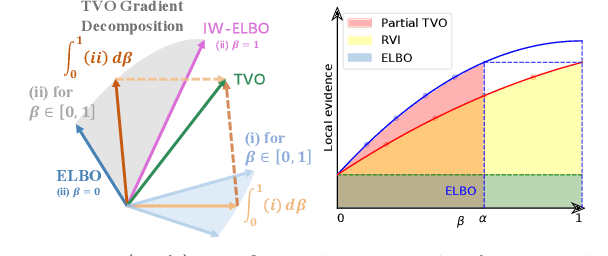
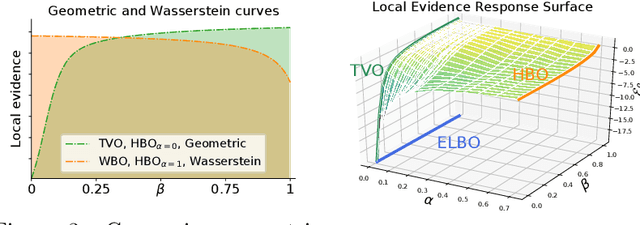
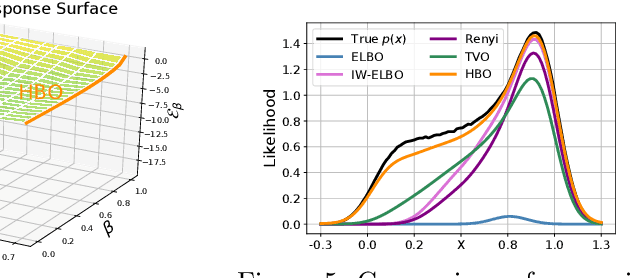
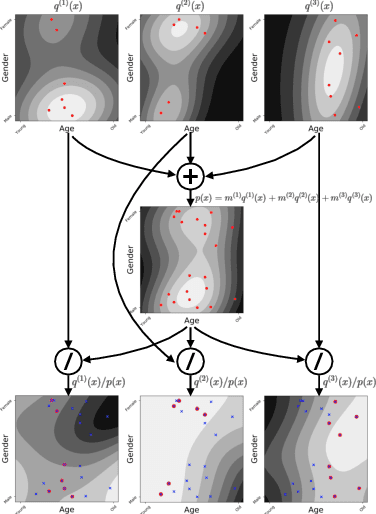
The recent introduction of thermodynamic integration techniques has provided a new framework for understanding and improving variational inference (VI). In this work, we present a careful analysis of the thermodynamic variational objective (TVO), bridging the gap between existing variational objectives and shedding new insights to advance the field. In particular, we elucidate how the TVO naturally connects the three key variational schemes, namely the importance-weighted VI, Renyi-VI, and MCMC-VI, which subsumes most VI objectives employed in practice. To explain the performance gap between theory and practice, we reveal how the pathological geometry of thermodynamic curves negatively affects TVO. By generalizing the integration path from the geometric mean to the weighted Holder mean, we extend the theory of TVO and identify new opportunities for improving VI. This motivates our new VI objectives, named the Holder bounds, which flatten the thermodynamic curves and promise to achieve a one-step approximation of the exact marginal log-likelihood. A comprehensive discussion on the choices of numerical estimators is provided. We present strong empirical evidence on both synthetic and real-world datasets to support our claims.
Weakly supervised cross-domain alignment with optimal transport
Aug 14, 2020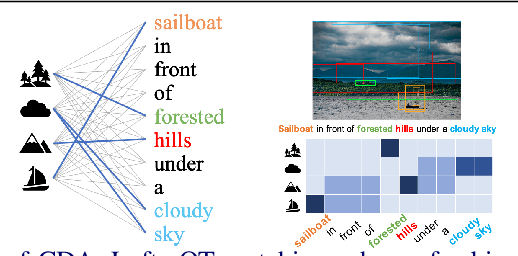
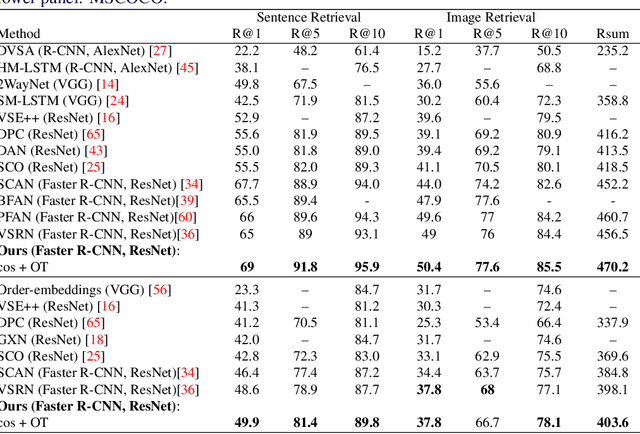
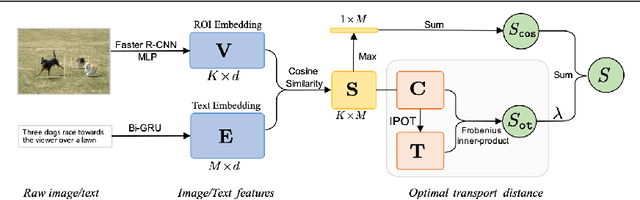
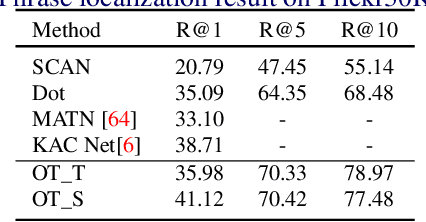
Cross-domain alignment between image objects and text sequences is key to many visual-language tasks, and it poses a fundamental challenge to both computer vision and natural language processing. This paper investigates a novel approach for the identification and optimization of fine-grained semantic similarities between image and text entities, under a weakly-supervised setup, improving performance over state-of-the-art solutions. Our method builds upon recent advances in optimal transport (OT) to resolve the cross-domain matching problem in a principled manner. Formulated as a drop-in regularizer, the proposed OT solution can be efficiently computed and used in combination with other existing approaches. We present empirical evidence to demonstrate the effectiveness of our approach, showing how it enables simpler model architectures to outperform or be comparable with more sophisticated designs on a range of vision-language tasks.
Learning Implicit Text Generation via Feature Matching
May 09, 2020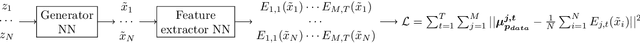
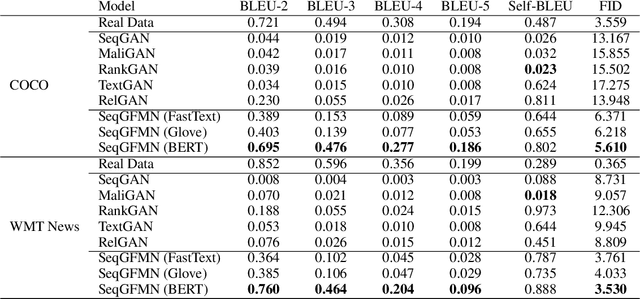
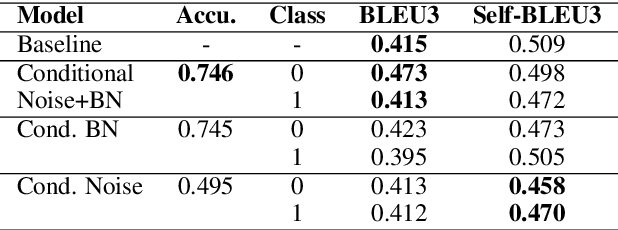
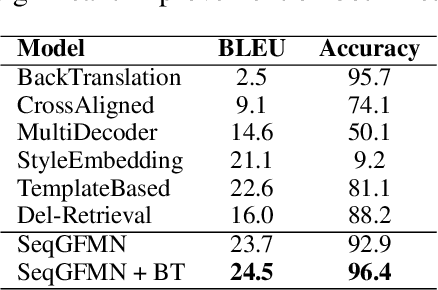
Generative feature matching network (GFMN) is an approach for training implicit generative models for images by performing moment matching on features from pre-trained neural networks. In this paper, we present new GFMN formulations that are effective for sequential data. Our experimental results show the effectiveness of the proposed method, SeqGFMN, for three distinct generation tasks in English: unconditional text generation, class-conditional text generation, and unsupervised text style transfer. SeqGFMN is stable to train and outperforms various adversarial approaches for text generation and text style transfer.
Regularizing Reasons for Outfit Evaluation with Gradient Penalty
Feb 02, 2020
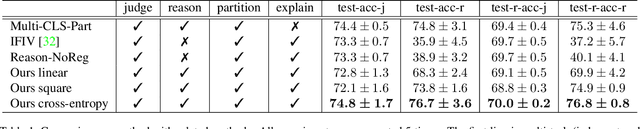
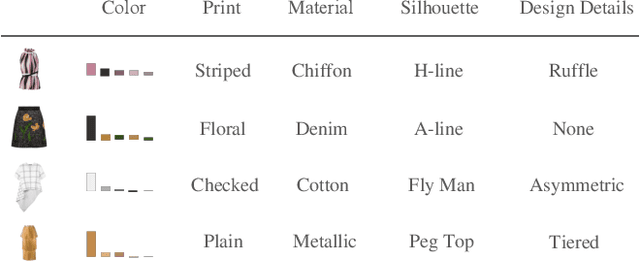
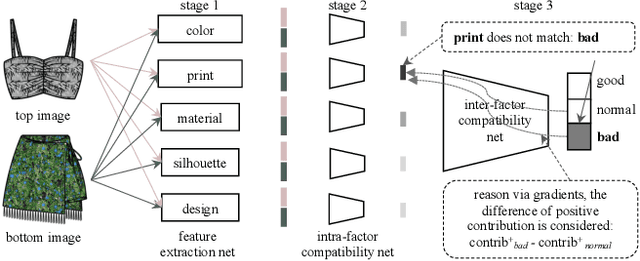
In this paper, we build an outfit evaluation system which provides feedbacks consisting of a judgment with a convincing explanation. The system is trained in a supervised manner which faithfully follows the domain knowledge in fashion. We create the EVALUATION3 dataset which is annotated with judgment, the decisive reason for the judgment, and all corresponding attributes (e.g. print, silhouette, and material \etc.). In the training process, features of all attributes in an outfit are first extracted and then concatenated as the input for the intra-factor compatibility net. Then, the inter-factor compatibility net is used to compute the loss for judgment. We penalize the gradient of judgment loss of so that our Grad-CAM-like reason is regularized to be consistent with the labeled reason. In inference, according to the obtained information of judgment, reason, and attributes, a user-friendly explanation sentence is generated by the pre-defined templates. The experimental results show that the obtained network combines the advantages of high precision and good interpretation.
GO Gradient for Expectation-Based Objectives
Jan 17, 2019
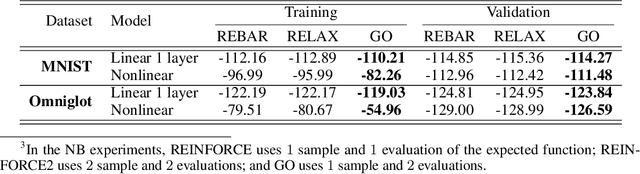

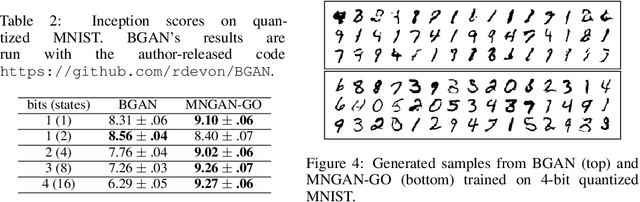
Within many machine learning algorithms, a fundamental problem concerns efficient calculation of an unbiased gradient wrt parameters $\gammav$ for expectation-based objectives $\Ebb_{q_{\gammav} (\yv)} [f(\yv)]$. Most existing methods either (i) suffer from high variance, seeking help from (often) complicated variance-reduction techniques; or (ii) they only apply to reparameterizable continuous random variables and employ a reparameterization trick. To address these limitations, we propose a General and One-sample (GO) gradient that (i) applies to many distributions associated with non-reparameterizable continuous or discrete random variables, and (ii) has the same low-variance as the reparameterization trick. We find that the GO gradient often works well in practice based on only one Monte Carlo sample (although one can of course use more samples if desired). Alongside the GO gradient, we develop a means of propagating the chain rule through distributions, yielding statistical back-propagation, coupling neural networks to common random variables.
Adversarial Learning of a Sampler Based on an Unnormalized Distribution
Jan 03, 2019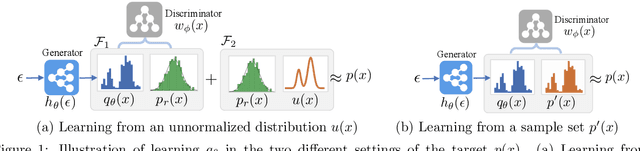
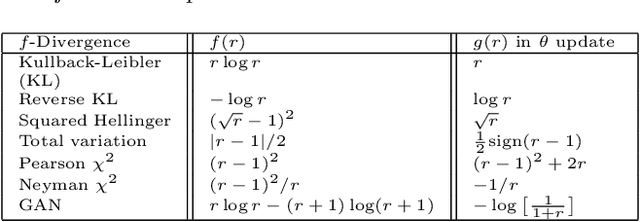
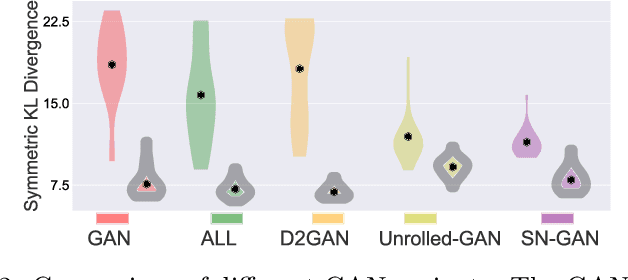
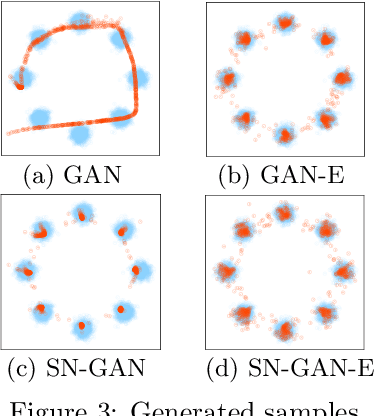
We investigate adversarial learning in the case when only an unnormalized form of the density can be accessed, rather than samples. With insights so garnered, adversarial learning is extended to the case for which one has access to an unnormalized form u(x) of the target density function, but no samples. Further, new concepts in GAN regularization are developed, based on learning from samples or from u(x). The proposed method is compared to alternative approaches, with encouraging results demonstrated across a range of applications, including deep soft Q-learning.