 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRAFT: Decoupling Ranking and Calibration for Survival Analysis
Feb 08, 2026Survival analysis is complicated by censored data, high-dimensional features, and non-linear interactions. Classical models are interpretable but restrictive, while deep learning models are flexible but often non-interpretable and sensitive to noise. We propose GRAFT (Gated Residual Accelerated Failure Time), a novel AFT model that decouples prognostic ranking from calibration. GRAFT's hybrid architecture combines a linear AFT model with a non-linear residual neural network, and it also integrates stochastic gates for automatic, end-to-end feature selection. The model is trained by directly optimizing a differentiable, C-index-aligned ranking loss using stochastic conditional imputation from local Kaplan-Meier estimators. In public benchmarks, GRAFT outperforms baselines in discrimination and calibration, while remaining robust and sparse in high-noise settings.
Labels have Human Values: Value Calibration of Subjective Tasks
Jan 10, 2026Building NLP systems for subjective tasks requires one to ensure their alignment to contrasting human values. We propose the MultiCalibrated Subjective Task Learner framework (MC-STL), which clusters annotations into identifiable human value clusters by three approaches (similarity of annotator rationales, expert-value taxonomies or rater's sociocultural descriptors) and calibrates predictions for each value cluster by learning cluster-specific embeddings. We demonstrate MC-STL on several subjective learning settings, including ordinal, binary, and preference learning predictions, and evaluate it on multiple datasets covering toxic chatbot conversations, offensive social media posts, and human preference alignment. The results show that MC-STL consistently outperforms the baselines that ignore the latent value structure of the annotations, delivering gains in discrimination, value-specific calibration, and disagreement-aware metrics.
Learning Survival Distributions with the Asymmetric Laplace Distribution
May 07, 2025Probabilistic survival analysis models seek to estimate the distribution of the future occurrence (time) of an event given a set of covariates. In recent years, these models have preferred nonparametric specifications that avoid directly estimating survival distributions via discretization. Specifically, they estimate the probability of an individual event at fixed times or the time of an event at fixed probabilities (quantiles), using supervised learning. Borrowing ideas from the quantile regression literature, we propose a parametric survival analysis method based on the Asymmetric Laplace Distribution (ALD). This distribution allows for closed-form calculation of popular event summaries such as mean, median, mode, variation, and quantiles. The model is optimized by maximum likelihood to learn, at the individual level, the parameters (location, scale, and asymmetry) of the ALD distribution. Extensive results on synthetic and real-world data demonstrate that the proposed method outperforms parametric and nonparametric approaches in terms of accuracy, discrimination and calibration.
Learning to Substitute Words with Model-based Score Ranking
Feb 09, 2025



Smart word substitution aims to enhance sentence quality by improving word choices; however current benchmarks rely on human-labeled data. Since word choices are inherently subjective, ground-truth word substitutions generated by a small group of annotators are often incomplete and likely not generalizable. To circumvent this issue, we instead employ a model-based score (BARTScore) to quantify sentence quality, thus forgoing the need for human annotations. Specifically, we use this score to define a distribution for each word substitution, allowing one to test whether a substitution is statistically superior relative to others. In addition, we propose a loss function that directly optimizes the alignment between model predictions and sentence scores, while also enhancing the overall quality score of a substitution. Crucially, model learning no longer requires human labels, thus avoiding the cost of annotation while maintaining the quality of the text modified with substitutions. Experimental results show that the proposed approach outperforms both masked language models (BERT, BART) and large language models (GPT-4, LLaMA). The source code is available at https://github.com/Hyfred/Substitute-Words-with-Ranking.
Transformer In-Context Learning for Categorical Data
May 27, 2024



Recent research has sought to understand Transformers through the lens of in-context learning with functional data. We extend that line of work with the goal of moving closer to language models, considering categorical outcomes, nonlinear underlying models, and nonlinear attention. The contextual data are of the form $\textsf{C}=(x_1,c_1,\dots,x_N,c_{N})$ where each $c_i\in\{0,\dots,C-1\}$ is drawn from a categorical distribution that depends on covariates $x_i\in\mathbb{R}^d$. Contextual outcomes in the $m$th set of contextual data, $\textsf{C}_m$, are modeled in terms of latent function $f_m(x)\in\textsf{F}$, where $\textsf{F}$ is a functional class with $(C-1)$-dimensional vector output. The probability of observing class $c\in\{0,\dots,C-1\}$ is modeled in terms of the output components of $f_m(x)$ via the softmax. The Transformer parameters may be trained with $M$ contextual examples, $\{\textsf{C}_m\}_{m=1,M}$, and the trained model is then applied to new contextual data $\textsf{C}_{M+1}$ for new $f_{M+1}(x)\in\textsf{F}$. The goal is for the Transformer to constitute the probability of each category $c\in\{0,\dots,C-1\}$ for a new query $x_{N_{M+1}+1}$. We assume each component of $f_m(x)$ resides in a reproducing kernel Hilbert space (RKHS), specifying $\textsf{F}$. Analysis and an extensive set of experiments suggest that on its forward pass the Transformer (with attention defined by the RKHS kernel) implements a form of gradient descent of the underlying function, connected to the latent vector function associated with the softmax. We present what is believed to be the first real-world demonstration of this few-shot-learning methodology, using the ImageNet dataset.
Conditioning on Time is All You Need for Synthetic Survival Data Generation
May 27, 2024Synthetic data generation holds considerable promise, offering avenues to enhance privacy, fairness, and data accessibility. Despite the availability of various methods for generating synthetic tabular data, challenges persist, particularly in specialized applications such as survival analysis. One significant obstacle in survival data generation is censoring, which manifests as not knowing the precise timing of observed (target) events for certain instances. Existing methods face difficulties in accurately reproducing the real distribution of event times for both observed (uncensored) events and censored events, i.e., the generated event-time distributions do not accurately match the underlying distributions of the real data. So motivated, we propose a simple paradigm to produce synthetic survival data by generating covariates conditioned on event times (and censoring indicators), thus allowing one to reuse existing conditional generative models for tabular data without significant computational overhead, and without making assumptions about the (usually unknown) generation mechanism underlying censoring. We evaluate this method via extensive experiments on real-world datasets. Our methodology outperforms multiple competitive baselines at generating survival data, while improving the performance of downstream survival models trained on it and tested on real data.
Deep learning-driven pulmonary arteries and veins segmentation reveals demography-associated pulmonary vasculature anatomy
Apr 11, 2024Pulmonary artery-vein segmentation is crucial for diagnosing pulmonary diseases and surgical planning, and is traditionally achieved by Computed Tomography Pulmonary Angiography (CTPA). However, concerns regarding adverse health effects from contrast agents used in CTPA have constrained its clinical utility. In contrast, identifying arteries and veins using non-contrast CT, a conventional and low-cost clinical examination routine, has long been considered impossible. Here we propose a High-abundant Pulmonary Artery-vein Segmentation (HiPaS) framework achieving accurate artery-vein segmentation on both non-contrast CT and CTPA across various spatial resolutions. HiPaS first performs spatial normalization on raw CT scans via a super-resolution module, and then iteratively achieves segmentation results at different branch levels by utilizing the low-level vessel segmentation as a prior for high-level vessel segmentation. We trained and validated HiPaS on our established multi-centric dataset comprising 1,073 CT volumes with meticulous manual annotation. Both quantitative experiments and clinical evaluation demonstrated the superior performance of HiPaS, achieving a dice score of 91.8% and a sensitivity of 98.0%. Further experiments demonstrated the non-inferiority of HiPaS segmentation on non-contrast CT compared to segmentation on CTPA. Employing HiPaS, we have conducted an anatomical study of pulmonary vasculature on 10,613 participants in China (five sites), discovering a new association between pulmonary vessel abundance and sex and age: vessel abundance is significantly higher in females than in males, and slightly decreases with age, under the controlling of lung volumes (p < 0.0001). HiPaS realizing accurate artery-vein segmentation delineates a promising avenue for clinical diagnosis and understanding pulmonary physiology in a non-invasive manner.
Improving Event Time Prediction by Learning to Partition the Event Time Space
Oct 24, 2023



Recently developed survival analysis methods improve upon existing approaches by predicting the probability of event occurrence in each of a number pre-specified (discrete) time intervals. By avoiding placing strong parametric assumptions on the event density, this approach tends to improve prediction performance, particularly when data are plentiful. However, in clinical settings with limited available data, it is often preferable to judiciously partition the event time space into a limited number of intervals well suited to the prediction task at hand. In this work, we develop a method to learn from data a set of cut points defining such a partition. We show that in two simulated datasets, we are able to recover intervals that match the underlying generative model. We then demonstrate improved prediction performance on three real-world observational datasets, including a large, newly harmonized stroke risk prediction dataset. Finally, we argue that our approach facilitates clinical decision-making by suggesting time intervals that are most appropriate for each task, in the sense that they facilitate more accurate risk prediction.
InfoPrompt: Information-Theoretic Soft Prompt Tuning for Natural Language Understanding
Jun 08, 2023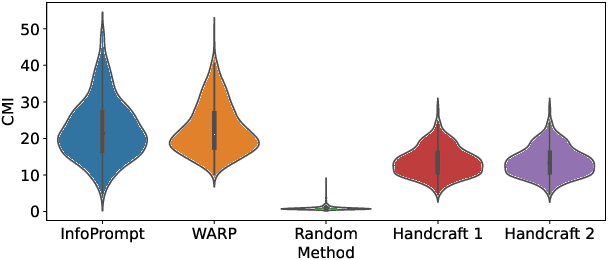


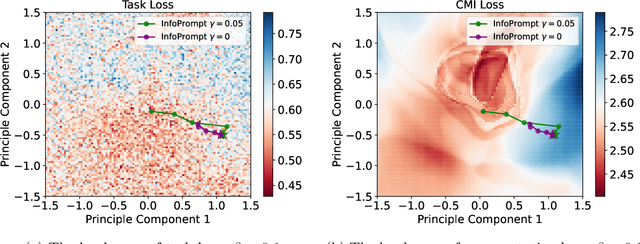
Soft prompt tuning achieves superior performances across a wide range of few-shot tasks. However, the performances of prompt tuning can be highly sensitive to the initialization of the prompts. We also empirically observe that conventional prompt tuning methods cannot encode and learn sufficient task-relevant information from prompt tokens. In this work, we develop an information-theoretic framework that formulates soft prompt tuning as maximizing mutual information between prompts and other model parameters (or encoded representations). This novel view helps us to develop a more efficient, accurate and robust soft prompt tuning method InfoPrompt. With this framework, we develop two novel mutual information based loss functions, to (i) discover proper prompt initialization for the downstream tasks and learn sufficient task-relevant information from prompt tokens and (ii) encourage the output representation from the pretrained language model to be more aware of the task-relevant information captured in the learnt prompt. Extensive experiments validate that InfoPrompt can significantly accelerate the convergence of the prompt tuning and outperform traditional prompt tuning methods. Finally, we provide a formal theoretical result for showing to show that gradient descent type algorithm can be used to train our mutual information loss.
An Effective Meaningful Way to Evaluate Survival Models
Jun 01, 2023One straightforward metric to evaluate a survival prediction model is based on the Mean Absolute Error (MAE) -- the average of the absolute difference between the time predicted by the model and the true event time, over all subjects. Unfortunately, this is challenging because, in practice, the test set includes (right) censored individuals, meaning we do not know when a censored individual actually experienced the event. In this paper, we explore various metrics to estimate MAE for survival datasets that include (many) censored individuals. Moreover, we introduce a novel and effective approach for generating realistic semi-synthetic survival datasets to facilitate the evaluation of metrics. Our findings, based on the analysis of the semi-synthetic datasets, reveal that our proposed metric (MAE using pseudo-observations) is able to rank models accurately based on their performance, and often closely matches the true MAE -- in particular, is better than several alternative methods.