 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Event Time Prediction by Learning to Partition the Event Time Space
Oct 24, 2023



Recently developed survival analysis methods improve upon existing approaches by predicting the probability of event occurrence in each of a number pre-specified (discrete) time intervals. By avoiding placing strong parametric assumptions on the event density, this approach tends to improve prediction performance, particularly when data are plentiful. However, in clinical settings with limited available data, it is often preferable to judiciously partition the event time space into a limited number of intervals well suited to the prediction task at hand. In this work, we develop a method to learn from data a set of cut points defining such a partition. We show that in two simulated datasets, we are able to recover intervals that match the underlying generative model. We then demonstrate improved prediction performance on three real-world observational datasets, including a large, newly harmonized stroke risk prediction dataset. Finally, we argue that our approach facilitates clinical decision-making by suggesting time intervals that are most appropriate for each task, in the sense that they facilitate more accurate risk prediction.
All models are local: time to replace external validation with recurrent local validation
May 13, 2023External validation is often recommended to ensure the generalizability of ML models. However, it neither guarantees generalizability nor equates to a model's clinical usefulness (the ultimate goal of any clinical decision-support tool). External validation is misaligned with current healthcare ML needs. First, patient data changes across time, geography, and facilities. These changes create significant volatility in the performance of a single fixed model (especially for deep learning models, which dominate clinical ML). Second, newer ML techniques, current market forces, and updated regulatory frameworks are enabling frequent updating and monitoring of individual deployed model instances. We submit that external validation is insufficient to establish ML models' safety or utility. Proposals to fix the external validation paradigm do not go far enough. Continued reliance on it as the ultimate test is likely to lead us astray. We propose the MLOps-inspired paradigm of recurring local validation as an alternative that ensures the validity of models while protecting against performance-disruptive data variability. This paradigm relies on site-specific reliability tests before every deployment, followed by regular and recurrent checks throughout the life cycle of the deployed algorithm. Initial and recurrent reliability tests protect against performance-disruptive distribution shifts, and concept drifts that jeopardize patient safety.
Survival Analysis meets Counterfactual Inference
Jun 14, 2020
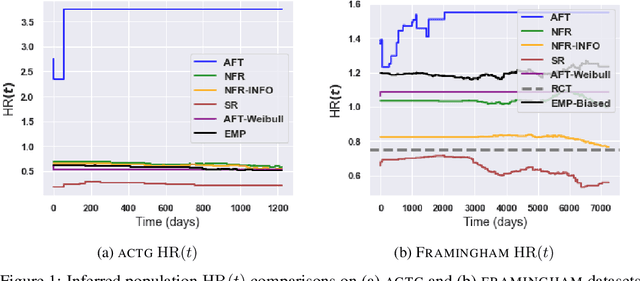
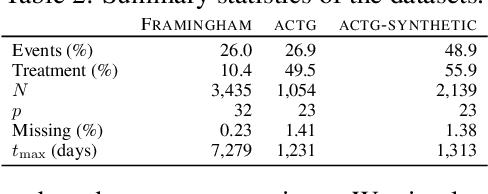
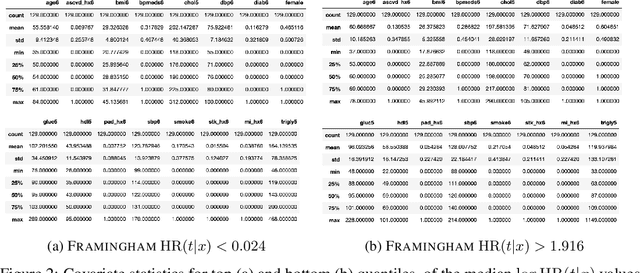
There is growing interest in applying machine learning methods for counterfactual inference from observational data. However, approaches that account for survival outcomes are relatively limited. Survival data are frequently encountered across diverse medical applications, \textit{i.e.}, drug development, risk profiling, and clinical trials, and such data are also relevant in fields like manufacturing (for equipment monitoring). When the outcome of interest is time-to-event, special precautions for handling censored events need to be taken, as ignoring censored outcomes may lead to biased estimates. We propose a theoretically grounded unified framework for counterfactual inference applicable to survival outcomes. Further, we formulate a nonparametric hazard ratio metric for evaluating average and individualized treatment effects. Experimental results on real-world and semi-synthetic datasets, the latter which we introduce, demonstrate that the proposed approach significantly outperforms competitive alternatives in both survival-outcome predictions and treatment-effect estimation.