 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometric Characterisation and Structured Trajectory Surrogates for Clinical Dataset Condensation
Apr 23, 2026Dataset condensation constructs compact synthetic datasets that retain the training utility of large real-world datasets, enabling efficient model development and potentially supporting downstream research in governed domains such as healthcare. Trajectory matching (TM) is a widely used condensation approach that supervises synthetic data using changes in model parameters observed during training on real data, yet the structure of this supervision signal remains poorly understood. In this paper, we provide a geometric characterisation of trajectory matching, showing that a fixed synthetic dataset can only reproduce a limited span of such training-induced parameter changes. When the resulting supervision signal is spectrally broad, this creates a conditional representability bottleneck. Motivated by this mismatch, we propose Bezier Trajectory Matching (BTM), which replaces SGD trajectories with quadratic Bezier trajectory surrogates between initial and final model states. These surrogates are optimised to reduce average loss along the path while replacing broad SGD-derived supervision with a more structured, lower-rank signal that is better aligned with the optimisation constraints of a fixed synthetic dataset, and they substantially reduce trajectory storage. Experiments on five clinical datasets demonstrate that BTM consistently matches or improves upon standard trajectory matching, with the largest gains in low-prevalence and low-synthetic-budget settings. These results indicate that effective trajectory matching depends on structuring the supervision signal rather than reproducing stochastic optimisation paths.
BAS: A Decision-Theoretic Approach to Evaluating Large Language Model Confidence
Apr 03, 2026Large language models (LLMs) often produce confident but incorrect answers in settings where abstention would be safer. Standard evaluation protocols, however, require a response and do not account for how confidence should guide decisions under different risk preferences. To address this gap, we introduce the Behavioral Alignment Score (BAS), a decision-theoretic metric for evaluating how well LLM confidence supports abstention-aware decision making. BAS is derived from an explicit answer-or-abstain utility model and aggregates realized utility across a continuum of risk thresholds, yielding a measure of decision-level reliability that depends on both the magnitude and ordering of confidence. We show theoretically that truthful confidence estimates uniquely maximize expected BAS utility, linking calibration to decision-optimal behavior. BAS is related to proper scoring rules such as log loss, but differs structurally: log loss penalizes underconfidence and overconfidence symmetrically, whereas BAS imposes an asymmetric penalty that strongly prioritizes avoiding overconfident errors. Using BAS alongside widely used metrics such as ECE and AURC, we then construct a benchmark of self-reported confidence reliability across multiple LLMs and tasks. Our results reveal substantial variation in decision-useful confidence, and while larger and more accurate models tend to achieve higher BAS, even frontier models remain prone to severe overconfidence. Importantly, models with similar ECE or AURC can exhibit very different BAS due to highly overconfident errors, highlighting limitations of standard metrics. We further show that simple interventions, such as top-$k$ confidence elicitation and post-hoc calibration, can meaningfully improve confidence reliability. Overall, our work provides both a principled metric and a comprehensive benchmark for evaluating LLM confidence reliability.
Entropy Alone is Insufficient for Safe Selective Prediction in LLMs
Mar 22, 2026Selective prediction systems can mitigate harms resulting from language model hallucinations by abstaining from answering in high-risk cases. Uncertainty quantification techniques are often employed to identify such cases, but are rarely evaluated in the context of the wider selective prediction policy and its ability to operate at low target error rates. We identify a model-dependent failure mode of entropy-based uncertainty methods that leads to unreliable abstention behaviour, and address it by combining entropy scores with a correctness probe signal. We find that across three QA benchmarks (TriviaQA, BioASQ, MedicalQA) and four model families, the combined score generally improves both the risk--coverage trade-off and calibration performance relative to entropy-only baselines. Our results highlight the importance of deployment-facing evaluation of uncertainty methods, using metrics that directly reflect whether a system can be trusted to operate at a stated risk level.
Democratising Clinical AI through Dataset Condensation for Classical Clinical Models
Mar 10, 2026Dataset condensation (DC) learns a compact synthetic dataset that enables models to match the performance of full-data training, prioritising utility over distributional fidelity. While typically explored for computational efficiency, DC also holds promise for healthcare data democratisation, especially when paired with differential privacy, allowing synthetic data to serve as a safe alternative to real records. However, existing DC methods rely on differentiable neural networks, limiting their compatibility with widely used clinical models such as decision trees and Cox regression. We address this gap using a differentially private, zero-order optimisation framework that extends DC to non-differentiable models using only function evaluations. Empirical results across six datasets, including both classification and survival tasks, show that the proposed method produces condensed datasets that preserve model utility while providing effective differential privacy guarantees - enabling model-agnostic data sharing for clinical prediction tasks without exposing sensitive patient information.
RiskAgent: Autonomous Medical AI Copilot for Generalist Risk Prediction
Mar 05, 2025The application of Large Language Models (LLMs) to various clinical applications has attracted growing research attention. However, real-world clinical decision-making differs significantly from the standardized, exam-style scenarios commonly used in current efforts. In this paper, we present the RiskAgent system to perform a broad range of medical risk predictions, covering over 387 risk scenarios across diverse complex diseases, e.g., cardiovascular disease and cancer. RiskAgent is designed to collaborate with hundreds of clinical decision tools, i.e., risk calculators and scoring systems that are supported by evidence-based medicine. To evaluate our method, we have built the first benchmark MedRisk specialized for risk prediction, including 12,352 questions spanning 154 diseases, 86 symptoms, 50 specialties, and 24 organ systems. The results show that our RiskAgent, with 8 billion model parameters, achieves 76.33% accuracy, outperforming the most recent commercial LLMs, o1, o3-mini, and GPT-4.5, and doubling the 38.39% accuracy of GPT-4o. On rare diseases, e.g., Idiopathic Pulmonary Fibrosis (IPF), RiskAgent outperforms o1 and GPT-4.5 by 27.27% and 45.46% accuracy, respectively. Finally, we further conduct a generalization evaluation on an external evidence-based diagnosis benchmark and show that our RiskAgent achieves the best results. These encouraging results demonstrate the great potential of our solution for diverse diagnosis domains. To improve the adaptability of our model in different scenarios, we have built and open-sourced a family of models ranging from 1 billion to 70 billion parameters. Our code, data, and models are all available at https://github.com/AI-in-Health/RiskAgent.
Surveying Facial Recognition Models for Diverse Indian Demographics: A Comparative Analysis on LFW and Custom Dataset
Dec 11, 2024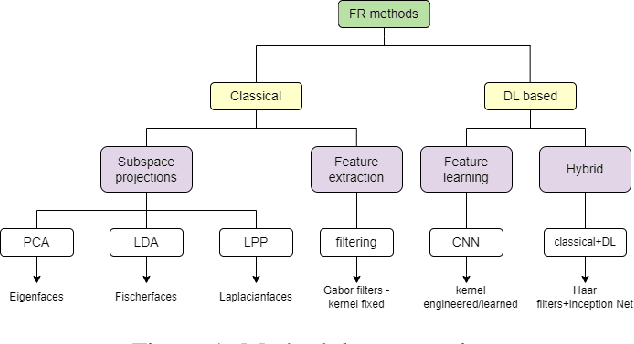



Facial recognition technology has made significant advances, yet its effectiveness across diverse ethnic backgrounds, particularly in specific Indian demographics, is less explored. This paper presents a detailed evaluation of both traditional and deep learning-based facial recognition models using the established LFW dataset and our newly developed IITJ Faces of Academia Dataset (JFAD), which comprises images of students from IIT Jodhpur. This unique dataset is designed to reflect the ethnic diversity of India, providing a critical test bed for assessing model performance in a focused academic environment. We analyze models ranging from holistic approaches like Eigenfaces and SIFT to advanced hybrid models that integrate CNNs with Gabor filters, Laplacian transforms, and segmentation techniques. Our findings reveal significant insights into the models' ability to adapt to the ethnic variability within Indian demographics and suggest modifications to enhance accuracy and inclusivity in real-world applications. The JFAD not only serves as a valuable resource for further research but also highlights the need for developing facial recognition systems that perform equitably across diverse populations.
Efficient Task Grouping Through Samplewise Optimisation Landscape Analysis
Dec 05, 2024Shared training approaches, such as multi-task learning (MTL) and gradient-based meta-learning, are widely used in various machine learning applications, but they often suffer from negative transfer, leading to performance degradation in specific tasks. While several optimisation techniques have been developed to mitigate this issue for pre-selected task cohorts, identifying optimal task combinations for joint learning - known as task grouping - remains underexplored and computationally challenging due to the exponential growth in task combinations and the need for extensive training and evaluation cycles. This paper introduces an efficient task grouping framework designed to reduce these overwhelming computational demands of the existing methods. The proposed framework infers pairwise task similarities through a sample-wise optimisation landscape analysis, eliminating the need for the shared model training required to infer task similarities in existing methods. With task similarities acquired, a graph-based clustering algorithm is employed to pinpoint near-optimal task groups, providing an approximate yet efficient and effective solution to the originally NP-hard problem. Empirical assessments conducted on 8 different datasets highlight the effectiveness of the proposed framework, revealing a five-fold speed enhancement compared to previous state-of-the-art methods. Moreover, the framework consistently demonstrates comparable performance, confirming its remarkable efficiency and effectiveness in task grouping.
F$^3$OCUS -- Federated Finetuning of Vision-Language Foundation Models with Optimal Client Layer Updating Strategy via Multi-objective Meta-Heuristics
Nov 17, 2024



Effective training of large Vision-Language Models (VLMs) on resource-constrained client devices in Federated Learning (FL) requires the usage of parameter-efficient fine-tuning (PEFT) strategies. To this end, we demonstrate the impact of two factors \textit{viz.}, client-specific layer importance score that selects the most important VLM layers for fine-tuning and inter-client layer diversity score that encourages diverse layer selection across clients for optimal VLM layer selection. We first theoretically motivate and leverage the principal eigenvalue magnitude of layerwise Neural Tangent Kernels and show its effectiveness as client-specific layer importance score. Next, we propose a novel layer updating strategy dubbed F$^3$OCUS that jointly optimizes the layer importance and diversity factors by employing a data-free, multi-objective, meta-heuristic optimization on the server. We explore 5 different meta-heuristic algorithms and compare their effectiveness for selecting model layers and adapter layers towards PEFT-FL. Furthermore, we release a new MedVQA-FL dataset involving overall 707,962 VQA triplets and 9 modality-specific clients and utilize it to train and evaluate our method. Overall, we conduct more than 10,000 client-level experiments on 6 Vision-Language FL task settings involving 58 medical image datasets and 4 different VLM architectures of varying sizes to demonstrate the effectiveness of the proposed method.
All models are local: time to replace external validation with recurrent local validation
May 13, 2023External validation is often recommended to ensure the generalizability of ML models. However, it neither guarantees generalizability nor equates to a model's clinical usefulness (the ultimate goal of any clinical decision-support tool). External validation is misaligned with current healthcare ML needs. First, patient data changes across time, geography, and facilities. These changes create significant volatility in the performance of a single fixed model (especially for deep learning models, which dominate clinical ML). Second, newer ML techniques, current market forces, and updated regulatory frameworks are enabling frequent updating and monitoring of individual deployed model instances. We submit that external validation is insufficient to establish ML models' safety or utility. Proposals to fix the external validation paradigm do not go far enough. Continued reliance on it as the ultimate test is likely to lead us astray. We propose the MLOps-inspired paradigm of recurring local validation as an alternative that ensures the validity of models while protecting against performance-disruptive data variability. This paradigm relies on site-specific reliability tests before every deployment, followed by regular and recurrent checks throughout the life cycle of the deployed algorithm. Initial and recurrent reliability tests protect against performance-disruptive distribution shifts, and concept drifts that jeopardize patient safety.
Is dataset condensation a silver bullet for healthcare data sharing?
May 05, 2023Safeguarding personal information is paramount for healthcare data sharing, a challenging issue without any silver bullet thus far. We study the prospect of a recent deep-learning advent, dataset condensation (DC), in sharing healthcare data for AI research, and the results are promising. The condensed data abstracts original records and irreversibly conceals individual-level knowledge to achieve a bona fide de-identification, which permits free sharing. Moreover, the original deep-learning utilities are well preserved in the condensed data with compressed volume and accelerated model convergences. In PhysioNet-2012, a condensed dataset of 20 samples can orient deep models attaining 80.3% test AUC of mortality prediction (versus 85.8% of 5120 original records), an inspiring discovery generalised to MIMIC-III and Coswara datasets. We also interpret the inhere privacy protections of DC through theoretical analysis and empirical evidence. Dataset condensation opens a new gate to sharing healthcare data for AI research with multiple desirable traits.