 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNADIR: Differential Attention Flow for Non-Autoregressive Transliteration in Indic Languages
Jan 18, 2026In this work, we argue that not all sequence-to-sequence tasks require the strong inductive biases of autoregressive (AR) models. Tasks like multilingual transliteration, code refactoring, grammatical correction or text normalization often rely on local dependencies where the full modeling capacity of AR models can be overkill, creating a trade-off between their high accuracy and high inference latency. While non-autoregressive (NAR) models offer speed, they typically suffer from hallucinations and poor length control. To explore this trade-off, we focus on the multilingual transliteration task in Indic languages and introduce NADIR, a novel NAR architecture designed to strike a balance between speed and accuracy. NADIR integrates a Differential Transformer and a Mixture-of-Experts mechanism, enabling it to robustly model complex character mappings without sequential dependencies. NADIR achieves over a 13x speed-up compared to the state-of-the-art AR baseline. It maintains a competitive mean Character Error Rate of 15.78%, compared to 14.44% for the AR model and 21.88% for a standard NAR equivalent. Importantly, NADIR reduces Repetition errors by 49.53%, Substitution errors by 24.45%, Omission errors by 32.92%, and Insertion errors by 16.87%. This work provides a practical blueprint for building fast and reliable NAR systems, effectively bridging the gap between AR accuracy and the demands of real-time, large-scale deployment.
On Characterizing the Evolution of Embedding Space of Neural Networks using Algebraic Topology
Nov 09, 2023We study how the topology of feature embedding space changes as it passes through the layers of a well-trained deep neural network (DNN) through Betti numbers. Motivated by existing studies using simplicial complexes on shallow fully connected networks (FCN), we present an extended analysis using Cubical homology instead, with a variety of popular deep architectures and real image datasets. We demonstrate that as depth increases, a topologically complicated dataset is transformed into a simple one, resulting in Betti numbers attaining their lowest possible value. The rate of decay in topological complexity (as a metric) helps quantify the impact of architectural choices on the generalization ability. Interestingly from a representation learning perspective, we highlight several invariances such as topological invariance of (1) an architecture on similar datasets; (2) embedding space of a dataset for architectures of variable depth; (3) embedding space to input resolution/size, and (4) data sub-sampling. In order to further demonstrate the link between expressivity \& the generalization capability of a network, we consider the task of ranking pre-trained models for downstream classification task (transfer learning). Compared to existing approaches, the proposed metric has a better correlation to the actually achievable accuracy via fine-tuning the pre-trained model.
Data Encoding For Healthcare Data Democratisation and Information Leakage Prevention
May 05, 2023The lack of data democratization and information leakage from trained models hinder the development and acceptance of robust deep learning-based healthcare solutions. This paper argues that irreversible data encoding can provide an effective solution to achieve data democratization without violating the privacy constraints imposed on healthcare data and clinical models. An ideal encoding framework transforms the data into a new space where it is imperceptible to a manual or computational inspection. However, encoded data should preserve the semantics of the original data such that deep learning models can be trained effectively. This paper hypothesizes the characteristics of the desired encoding framework and then exploits random projections and random quantum encoding to realize this framework for dense and longitudinal or time-series data. Experimental evaluation highlights that models trained on encoded time-series data effectively uphold the information bottleneck principle and hence, exhibit lesser information leakage from trained models.
Coordinate descent on the orthogonal group for recurrent neural network training
Jul 30, 2021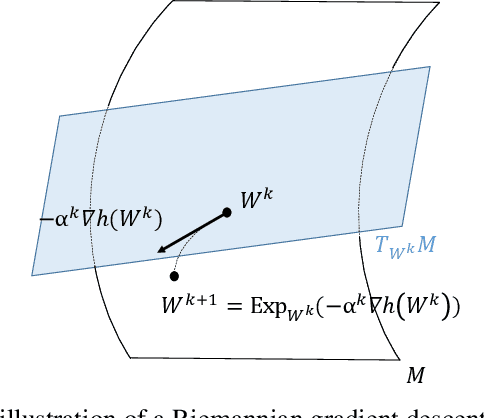

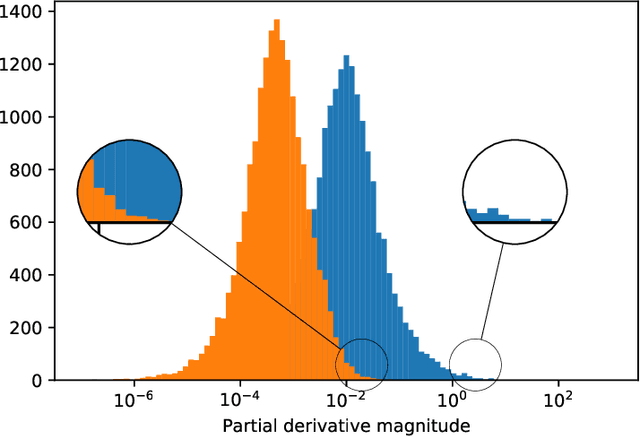
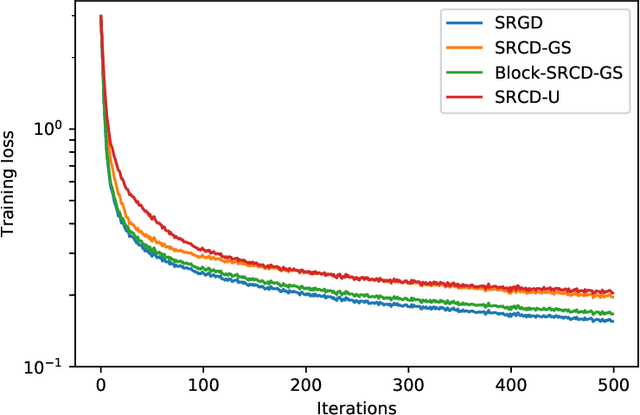
We propose to use stochastic Riemannian coordinate descent on the orthogonal group for recurrent neural network training. The algorithm rotates successively two columns of the recurrent matrix, an operation that can be efficiently implemented as a multiplication by a Givens matrix. In the case when the coordinate is selected uniformly at random at each iteration, we prove the convergence of the proposed algorithm under standard assumptions on the loss function, stepsize and minibatch noise. In addition, we numerically demonstrate that the Riemannian gradient in recurrent neural network training has an approximately sparse structure. Leveraging this observation, we propose a faster variant of the proposed algorithm that relies on the Gauss-Southwell rule. Experiments on a benchmark recurrent neural network training problem are presented to demonstrate the effectiveness of the proposed algorithm.
Activation function design for deep networks: linearity and effective initialisation
May 17, 2021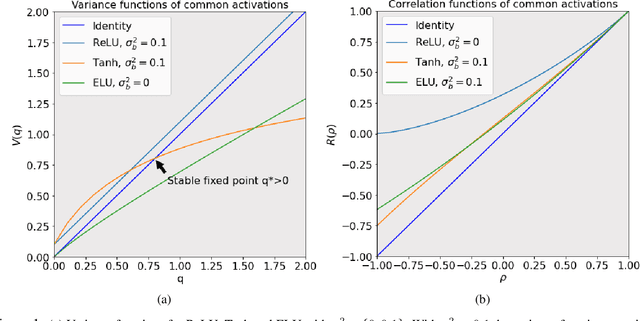
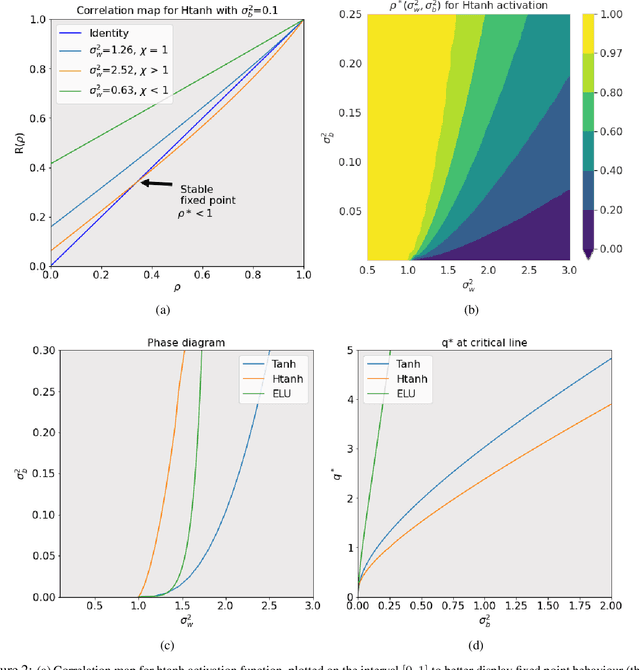
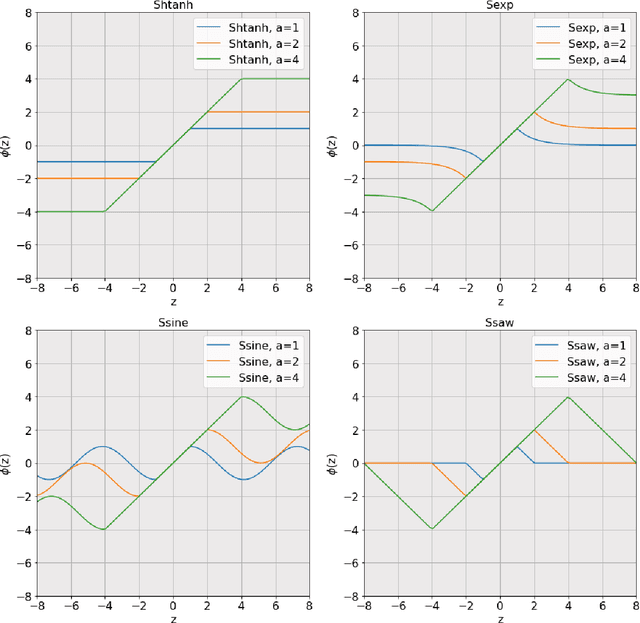
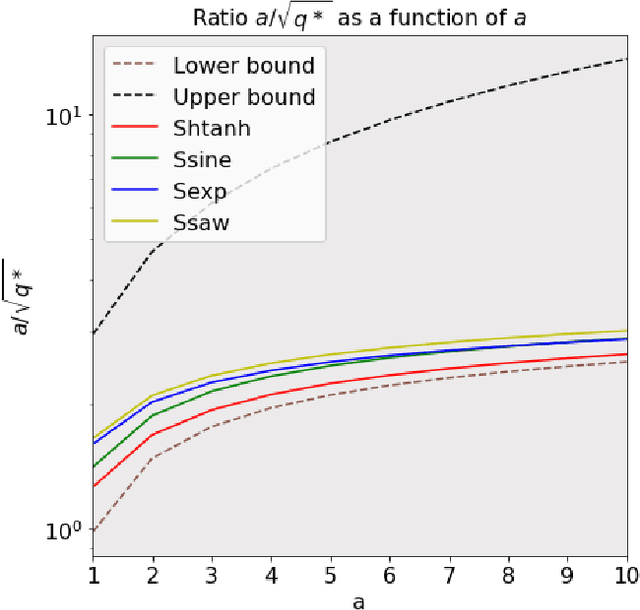
The activation function deployed in a deep neural network has great influence on the performance of the network at initialisation, which in turn has implications for training. In this paper we study how to avoid two problems at initialisation identified in prior works: rapid convergence of pairwise input correlations, and vanishing and exploding gradients. We prove that both these problems can be avoided by choosing an activation function possessing a sufficiently large linear region around the origin, relative to the bias variance $\sigma_b^2$ of the network's random initialisation. We demonstrate empirically that using such activation functions leads to tangible benefits in practice, both in terms test and training accuracy as well as training time. Furthermore, we observe that the shape of the nonlinear activation outside the linear region appears to have a relatively limited impact on training. Finally, our results also allow us to train networks in a new hyperparameter regime, with a much larger bias variance than has previously been possible.
An Empirical Study of Derivative-Free-Optimization Algorithms for Targeted Black-Box Attacks in Deep Neural Networks
Dec 03, 2020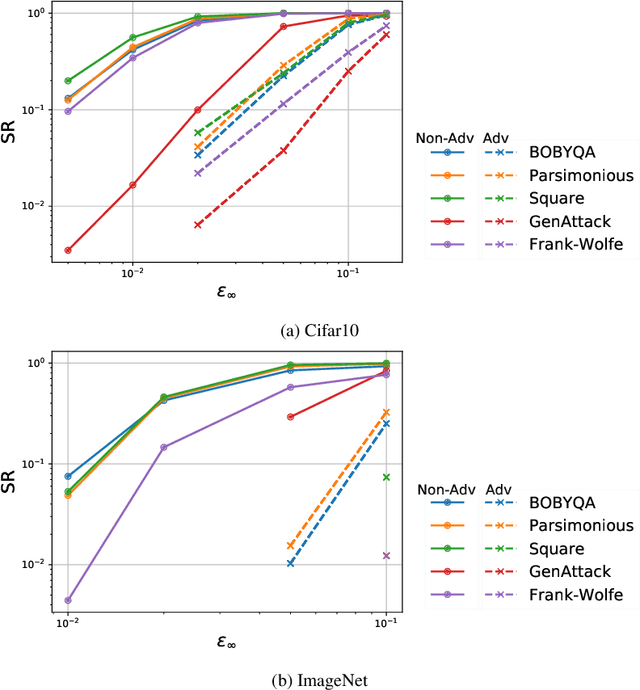
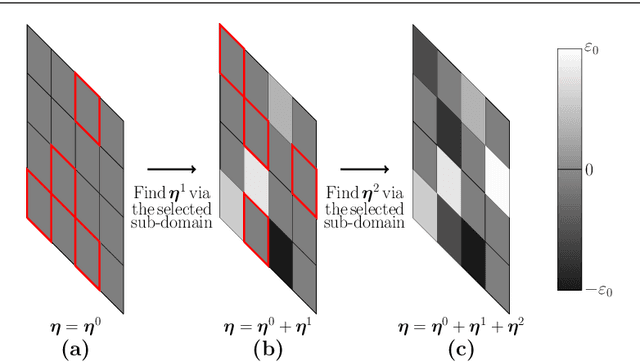
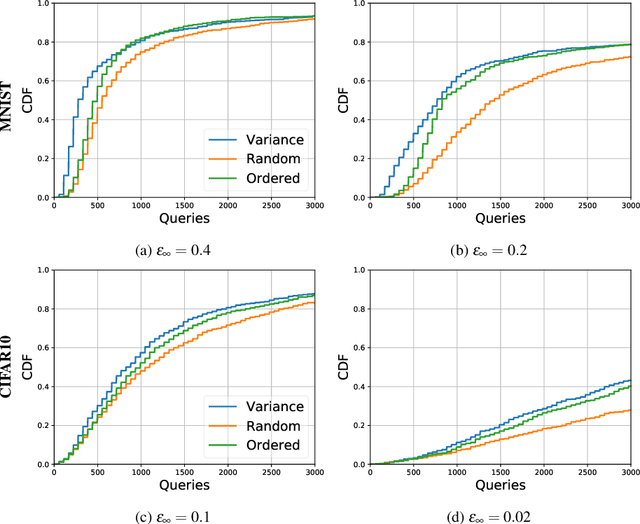
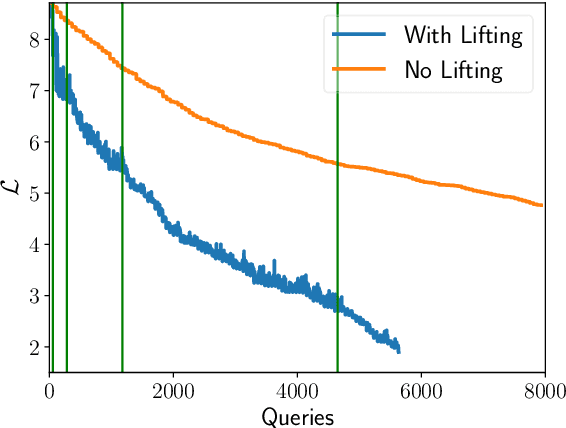
We perform a comprehensive study on the performance of derivative free optimization (DFO) algorithms for the generation of targeted black-box adversarial attacks on Deep Neural Network (DNN) classifiers assuming the perturbation energy is bounded by an $\ell_\infty$ constraint and the number of queries to the network is limited. This paper considers four pre-existing state-of-the-art DFO-based algorithms along with the introduction of a new algorithm built on BOBYQA, a model-based DFO method. We compare these algorithms in a variety of settings according to the fraction of images that they successfully misclassify given a maximum number of queries to the DNN. The experiments disclose how the likelihood of finding an adversarial example depends on both the algorithm used and the setting of the attack; algorithms limiting the search of adversarial example to the vertices of the $\ell^\infty$ constraint work particularly well without structural defenses, while the presented BOBYQA based algorithm works better for especially small perturbation energies. This variance in performance highlights the importance of new algorithms being compared to the state-of-the-art in a variety of settings, and the effectiveness of adversarial defenses being tested using as wide a range of algorithms as possible.
A Model-Based Derivative-Free Approach to Black-Box Adversarial Examples: BOBYQA
Feb 24, 2020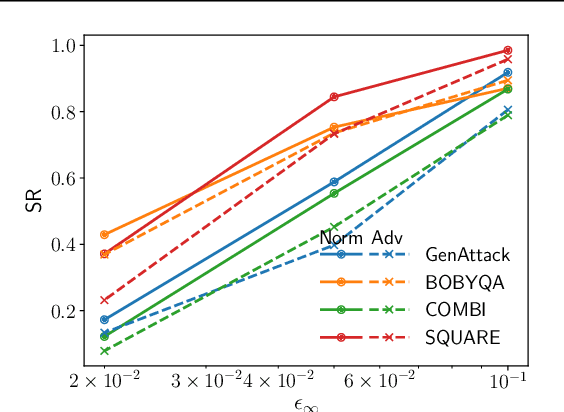
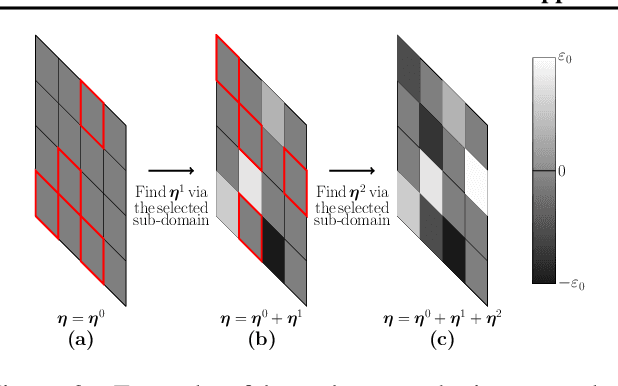
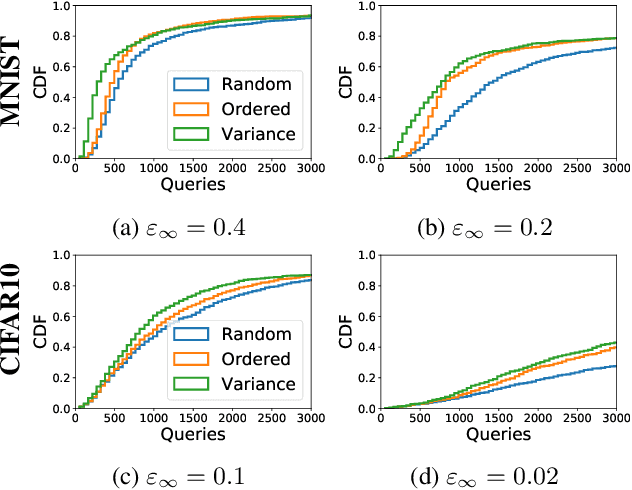
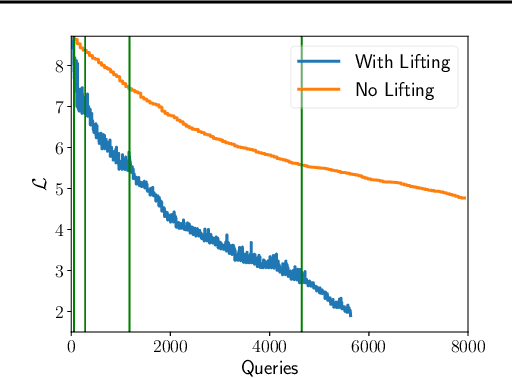
We demonstrate that model-based derivative free optimisation algorithms can generate adversarial targeted misclassification of deep networks using fewer network queries than non-model-based methods. Specifically, we consider the black-box setting, and show that the number of networks queries is less impacted by making the task more challenging either through reducing the allowed $\ell^{\infty}$ perturbation energy or training the network with defences against adversarial misclassification. We illustrate this by contrasting the BOBYQA algorithm with the state-of-the-art model-free adversarial targeted misclassification approaches based on genetic, combinatorial, and direct-search algorithms. We observe that for high $\ell^{\infty}$ energy perturbations on networks, the aforementioned simpler model-free methods require the fewest queries. In contrast, the proposed BOBYQA based method achieves state-of-the-art results when the perturbation energy decreases, or if the network is trained against adversarial perturbations.
Conv-codes: Audio Hashing For Bird Species Classification
Feb 07, 2019
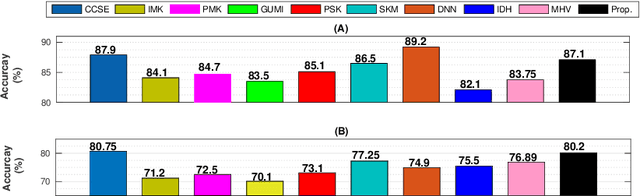
In this work, we propose a supervised, convex representation based audio hashing framework for bird species classification. The proposed framework utilizes archetypal analysis, a matrix factorization technique, to obtain convex-sparse representations of a bird vocalization. These convex representations are hashed using Bloom filters with non-cryptographic hash functions to obtain compact binary codes, designated as conv-codes. The conv-codes extracted from the training examples are clustered using class-specific k-medoids clustering with Jaccard coefficient as the similarity metric. A hash table is populated using the cluster centers as keys while hash values/slots are pointers to the species identification information. During testing, the hash table is searched to find the species information corresponding to a cluster center that exhibits maximum similarity with the test conv-code. Hence, the proposed framework classifies a bird vocalization in the conv-code space and requires no explicit classifier or reconstruction error calculations. Apart from that, based on min-hash and direct addressing, we also propose a variant of the proposed framework that provides faster and effective classification. The performances of both these frameworks are compared with existing bird species classification frameworks on the audio recordings of 50 different bird species.