 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDispelling the Curse of Singularities in Neural Network Optimizations
Feb 01, 2026This work investigates the optimization instability of deep neural networks from a less-explored yet insightful perspective: the emergence and amplification of singularities in the parametric space. Our analysis reveals that parametric singularities inevitably grow with gradient updates and further intensify alignment with representations, leading to increased singularities in the representation space. We show that the gradient Frobenius norms are bounded by the top singular values of the weight matrices, and as training progresses, the mutually reinforcing growth of weight and representation singularities, termed the curse of singularities, relaxes these bounds, escalating the risk of sharp loss explosions. To counter this, we propose Parametric Singularity Smoothing (PSS), a lightweight, flexible, and effective method for smoothing the singular spectra of weight matrices. Extensive experiments across diverse datasets, architectures, and optimizers demonstrate that PSS mitigates instability, restores trainability even after failure, and improves both training efficiency and generalization.
Normative Modelling in Neuroimaging: A Practical Guide for Researchers
Sep 08, 2025Normative modelling is an increasingly common statistical technique in neuroimaging that estimates population-level benchmarks in brain structure. It enables the quantification of individual deviations from expected distributions whilst accounting for biological and technical covariates without requiring large, matched control groups. This makes it a powerful alternative to traditional case-control studies for identifying brain structural alterations associated with pathology. Despite the availability of numerous modelling approaches and several toolboxes with pretrained models, the distinct strengths and limitations of normative modelling make it difficult to determine how and when to implement them appropriately. This review offers practical guidance and outlines statistical considerations for clinical researchers using normative modelling in neuroimaging. We compare several open-source normative modelling tools through a worked example using clinical epilepsy data; outlining decision points, common pitfalls, and considerations for responsible implementation, to support broader and more rigorous adoption of normative modelling in neuroimaging research.
Efficient Task Grouping Through Samplewise Optimisation Landscape Analysis
Dec 05, 2024Shared training approaches, such as multi-task learning (MTL) and gradient-based meta-learning, are widely used in various machine learning applications, but they often suffer from negative transfer, leading to performance degradation in specific tasks. While several optimisation techniques have been developed to mitigate this issue for pre-selected task cohorts, identifying optimal task combinations for joint learning - known as task grouping - remains underexplored and computationally challenging due to the exponential growth in task combinations and the need for extensive training and evaluation cycles. This paper introduces an efficient task grouping framework designed to reduce these overwhelming computational demands of the existing methods. The proposed framework infers pairwise task similarities through a sample-wise optimisation landscape analysis, eliminating the need for the shared model training required to infer task similarities in existing methods. With task similarities acquired, a graph-based clustering algorithm is employed to pinpoint near-optimal task groups, providing an approximate yet efficient and effective solution to the originally NP-hard problem. Empirical assessments conducted on 8 different datasets highlight the effectiveness of the proposed framework, revealing a five-fold speed enhancement compared to previous state-of-the-art methods. Moreover, the framework consistently demonstrates comparable performance, confirming its remarkable efficiency and effectiveness in task grouping.
Train Faster, Perform Better: Modular Adaptive Training in Over-Parameterized Models
May 13, 2024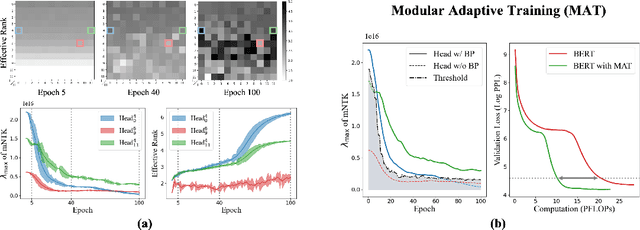

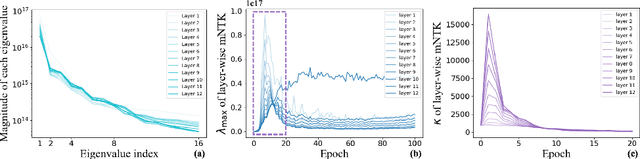

Despite their prevalence in deep-learning communities, over-parameterized models convey high demands of computational costs for proper training. This work studies the fine-grained, modular-level learning dynamics of over-parameterized models to attain a more efficient and fruitful training strategy. Empirical evidence reveals that when scaling down into network modules, such as heads in self-attention models, we can observe varying learning patterns implicitly associated with each module's trainability. To describe such modular-level learning capabilities, we introduce a novel concept dubbed modular neural tangent kernel (mNTK), and we demonstrate that the quality of a module's learning is tightly associated with its mNTK's principal eigenvalue $\lambda_{\max}$. A large $\lambda_{\max}$ indicates that the module learns features with better convergence, while those miniature ones may impact generalization negatively. Inspired by the discovery, we propose a novel training strategy termed Modular Adaptive Training (MAT) to update those modules with their $\lambda_{\max}$ exceeding a dynamic threshold selectively, concentrating the model on learning common features and ignoring those inconsistent ones. Unlike most existing training schemes with a complete BP cycle across all network modules, MAT can significantly save computations by its partially-updating strategy and can further improve performance. Experiments show that MAT nearly halves the computational cost of model training and outperforms the accuracy of baselines.
Is dataset condensation a silver bullet for healthcare data sharing?
May 05, 2023Safeguarding personal information is paramount for healthcare data sharing, a challenging issue without any silver bullet thus far. We study the prospect of a recent deep-learning advent, dataset condensation (DC), in sharing healthcare data for AI research, and the results are promising. The condensed data abstracts original records and irreversibly conceals individual-level knowledge to achieve a bona fide de-identification, which permits free sharing. Moreover, the original deep-learning utilities are well preserved in the condensed data with compressed volume and accelerated model convergences. In PhysioNet-2012, a condensed dataset of 20 samples can orient deep models attaining 80.3% test AUC of mortality prediction (versus 85.8% of 5120 original records), an inspiring discovery generalised to MIMIC-III and Coswara datasets. We also interpret the inhere privacy protections of DC through theoretical analysis and empirical evidence. Dataset condensation opens a new gate to sharing healthcare data for AI research with multiple desirable traits.
Data Encoding For Healthcare Data Democratisation and Information Leakage Prevention
May 05, 2023The lack of data democratization and information leakage from trained models hinder the development and acceptance of robust deep learning-based healthcare solutions. This paper argues that irreversible data encoding can provide an effective solution to achieve data democratization without violating the privacy constraints imposed on healthcare data and clinical models. An ideal encoding framework transforms the data into a new space where it is imperceptible to a manual or computational inspection. However, encoded data should preserve the semantics of the original data such that deep learning models can be trained effectively. This paper hypothesizes the characteristics of the desired encoding framework and then exploits random projections and random quantum encoding to realize this framework for dense and longitudinal or time-series data. Experimental evaluation highlights that models trained on encoded time-series data effectively uphold the information bottleneck principle and hence, exhibit lesser information leakage from trained models.
Training Strategies for Improved Lip-reading
Sep 03, 2022


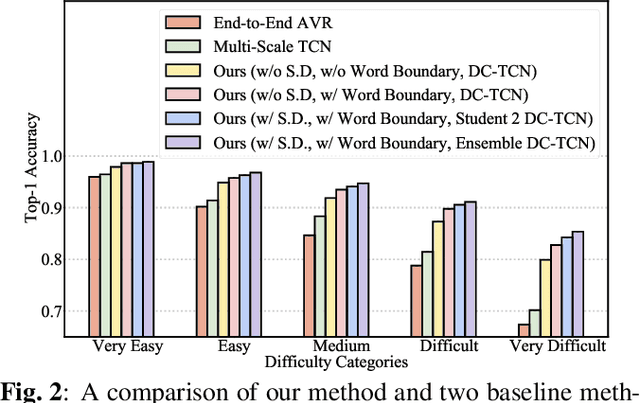
Several training strategies and temporal models have been recently proposed for isolated word lip-reading in a series of independent works. However, the potential of combining the best strategies and investigating the impact of each of them has not been explored. In this paper, we systematically investigate the performance of state-of-the-art data augmentation approaches, temporal models and other training strategies, like self-distillation and using word boundary indicators. Our results show that Time Masking (TM) is the most important augmentation followed by mixup and Densely-Connected Temporal Convolutional Networks (DC-TCN) are the best temporal model for lip-reading of isolated words. Using self-distillation and word boundary indicators is also beneficial but to a lesser extent. A combination of all the above methods results in a classification accuracy of 93.4%, which is an absolute improvement of 4.6% over the current state-of-the-art performance on the LRW dataset. The performance can be further improved to 94.1% by pre-training on additional datasets. An error analysis of the various training strategies reveals that the performance improves by increasing the classification accuracy of hard-to-recognise words.
Self-supervised Video-centralised Transformer for Video Face Clustering
Mar 24, 2022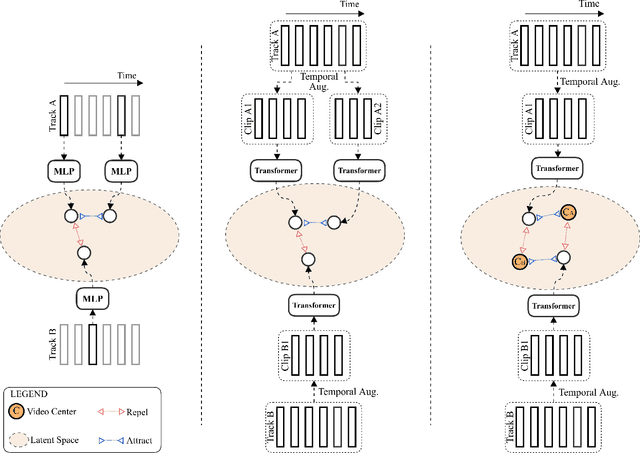

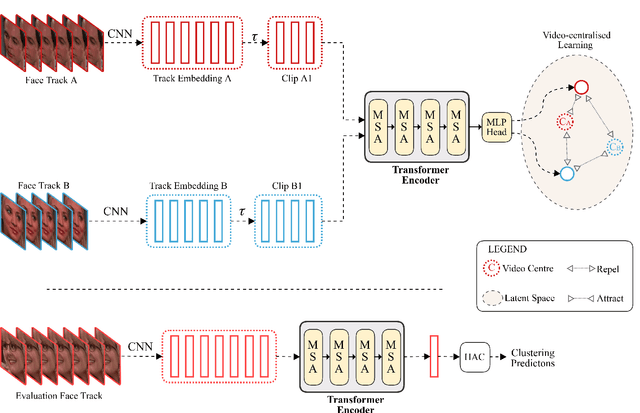
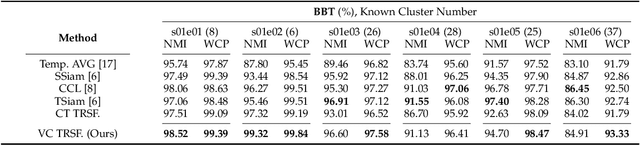
This paper presents a novel method for face clustering in videos using a video-centralised transformer. Previous works often employed contrastive learning to learn frame-level representation and used average pooling to aggregate the features along the temporal dimension. This approach may not fully capture the complicated video dynamics. In addition, despite the recent progress in video-based contrastive learning, few have attempted to learn a self-supervised clustering-friendly face representation that benefits the video face clustering task. To overcome these limitations, our method employs a transformer to directly learn video-level representations that can better reflect the temporally-varying property of faces in videos, while we also propose a video-centralised self-supervised framework to train the transformer model. We also investigate face clustering in egocentric videos, a fast-emerging field that has not been studied yet in works related to face clustering. To this end, we present and release the first large-scale egocentric video face clustering dataset named EasyCom-Clustering. We evaluate our proposed method on both the widely used Big Bang Theory (BBT) dataset and the new EasyCom-Clustering dataset. Results show the performance of our video-centralised transformer has surpassed all previous state-of-the-art methods on both benchmarks, exhibiting a self-attentive understanding of face videos.
Do Smart Glasses Dream of Sentimental Visions? Deep Emotionship Analysis for Eyewear Devices
Jan 24, 2022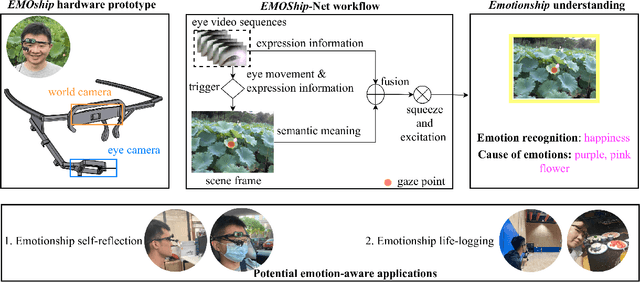

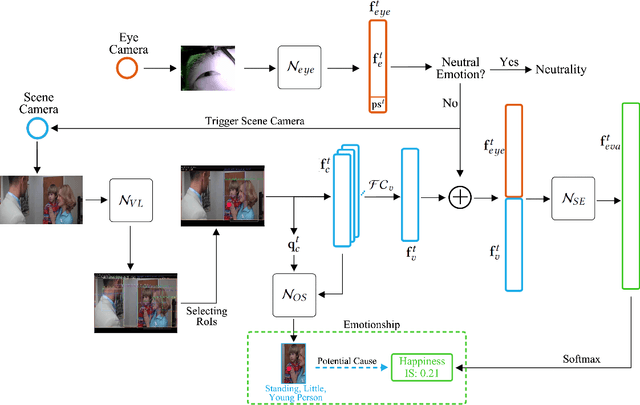
Emotion recognition in smart eyewear devices is highly valuable but challenging. One key limitation of previous works is that the expression-related information like facial or eye images is considered as the only emotional evidence. However, emotional status is not isolated; it is tightly associated with people's visual perceptions, especially those sentimental ones. However, little work has examined such associations to better illustrate the cause of different emotions. In this paper, we study the emotionship analysis problem in eyewear systems, an ambitious task that requires not only classifying the user's emotions but also semantically understanding the potential cause of such emotions. To this end, we devise EMOShip, a deep-learning-based eyewear system that can automatically detect the wearer's emotional status and simultaneously analyze its associations with semantic-level visual perceptions. Experimental studies with 20 participants demonstrate that, thanks to the emotionship awareness, EMOShip not only achieves superior emotion recognition accuracy over existing methods (80.2% vs. 69.4%), but also provides a valuable understanding of the cause of emotions. Pilot studies with 20 participants further motivate the potential use of EMOShip to empower emotion-aware applications, such as emotionship self-reflection and emotionship life-logging.
Domain Generalisation for Apparent Emotional Facial Expression Recognition across Age-Groups
Oct 18, 2021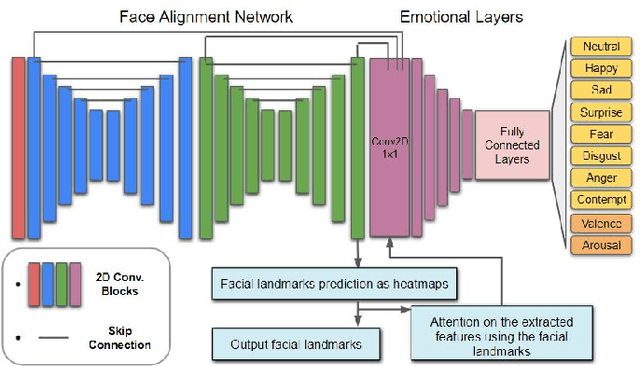
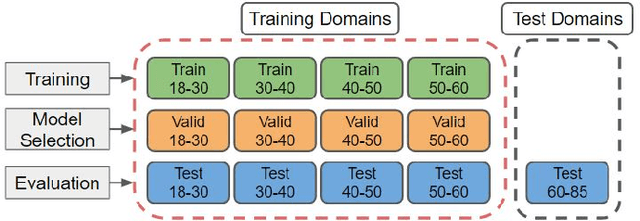
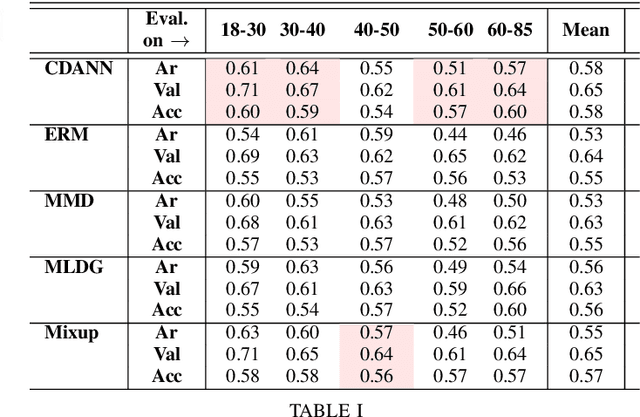
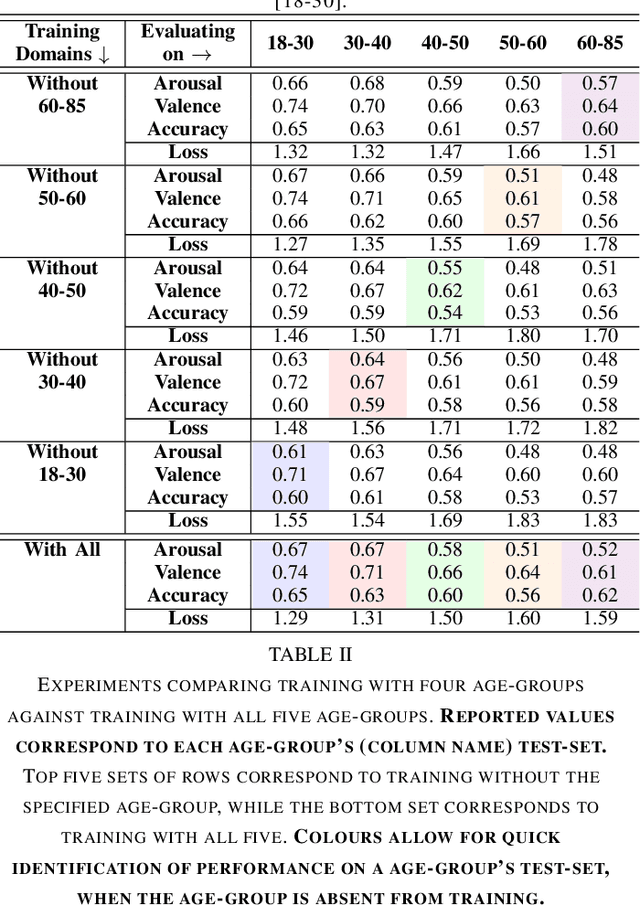
Apparent emotional facial expression recognition has attracted a lot of research attention recently. However, the majority of approaches ignore age differences and train a generic model for all ages. In this work, we study the effect of using different age-groups for training apparent emotional facial expression recognition models. To this end, we study Domain Generalisation in the context of apparent emotional facial expression recognition from facial imagery across different age groups. We first compare several domain generalisation algorithms on the basis of out-of-domain-generalisation, and observe that the Class-Conditional Domain-Adversarial Neural Networks (CDANN) algorithm has the best performance. We then study the effect of variety and number of age-groups used during training on generalisation to unseen age-groups and observe that an increase in the number of training age-groups tends to increase the apparent emotional facial expression recognition performance on unseen age-groups. We also show that exclusion of an age-group during training tends to affect more the performance of the neighbouring age groups.