 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniFaceRig: Fully Automatic Inner-Mouth-Aware Face Rigging Across Diverse 3D Character Topologies
Jun 06, 2026Facial rigging - creating FACS-based blendshapes together with inner-mouth geometry (teeth, gums, and tongue) - remains a major bottleneck in 3D character production. Existing pipelines still require substantial designer effort, especially for manual landmark annotation, per-character template adjustment, and inner-mouth placement. We present OmniFaceRig, a fully automatic end-to-end pipeline that converts a static surface-only 3D character mesh, with no pre-modeled oral cavity, into an inner-mouth-aware FACS rig with up to 155 blendshapes, procedurally fitted teeth, gums, and tongue, and re-packed UV/texture. OmniFaceRig supports diverse topologies - humans, humanoids, long-muzzled animals (e.g., dogs, wolves, foxes), and short-muzzled animals (e.g., cats, bears, rabbits, tigers) - with no manual landmarks, no user-provided templates, and no per-asset setup. The pipeline combines hybrid VLM+CV riggability checking, multi-model face parsing, dense keypoint-driven template registration, procedural inner-mouth construction, and collision-aware blendshape transfer. For non-human characters, OmniFaceRig selects topology-specific face and inner-mouth templates and uses collision-aware inner-mouth fitting to reduce teeth-face intersections without exposing users to category-specific tuning. We also publicly release Omni-Bench, a freely available benchmark dataset of 1,000 biped 3D characters with FACS facial blendshapes and inner-mouth geometry, spanning humans, humanoids, cats, dogs, and other animals. Experiments show high final rigging success on screened Omni-Bench inputs, nearly complete face detection recall from the segmentation ensemble and reliable inner-mouth placement with low penetration. Together, OmniFaceRig provides an automatic path from static generated characters to animation-ready facial rigs across both human and non-human topologies.
MinerU-Popo: Universal Post-Processing Model for Structured Document Parsing
May 24, 2026VLM-based OCR models have become the de facto choice for document parsing, as they can accurately extract page-level elements (e.g., paragraphs within individual pages) together with their bounding boxes and textual content. However, downstream applications such as RAG require coherent document-level information, whereas these models often break cross-page continuity and fail to recover disrupted structures, such as paragraphs and tables truncated by page boundaries. Such relationships are not confined to a single page; instead, they require joint analysis of titles, paragraphs, tables, and images spanning multiple pages. A natural solution is therefore to reuse existing OCR outputs and reconstruct document-level logical structures through post-processing. To this end, we propose MinerU-Popo, a lightweight and universal framework for POst-Processing OCR outputs, which converts page-level results from diverse parsers into coherent document-level structures. MinerU-Popo decomposes the problem into four focused subtasks: text truncation recovery, table truncation recovery, title hierarchy reconstruction, and image-text association. To address these effectively, we build a task-oriented data engine with task-specific input filtering, and use the generated data (30K) to fine-tune a lightweight post-processing model (Qwen3-VL-4B). To support long documents, we introduce dynamic chunking with overlap-based synchronization, which aligns chunk-level outputs from the fine-tuned model and preserves global consistency. Finally, we assemble the aligned outputs into a tree-structured document representation, further enriched with node chunking and summaries for downstream retrieval and analysis. Empirical results show MinerU-Popo improves title-hierarchy TEDS by at least 20% across all five tested OCR models, improves RAG accuracy and reduces per-query latency.
RAM-SD: Retrieval-Augmented Multi-agent framework for Sarcasm Detection
Jan 14, 2026Sarcasm detection remains a significant challenge due to its reliance on nuanced contextual understanding, world knowledge, and multi-faceted linguistic cues that vary substantially across different sarcastic expressions. Existing approaches, from fine-tuned transformers to large language models, apply a uniform reasoning strategy to all inputs, struggling to address the diverse analytical demands of sarcasm. These demands range from modeling contextual expectation violations to requiring external knowledge grounding or recognizing specific rhetorical patterns. To address this limitation, we introduce RAM-SD, a Retrieval-Augmented Multi-Agent framework for Sarcasm Detection. The framework operates through four stages: (1) contextual retrieval grounds the query in both sarcastic and non-sarcastic exemplars; (2) a meta-planner classifies the sarcasm type and selects an optimal reasoning plan from a predefined set; (3) an ensemble of specialized agents performs complementary, multi-view analysis; and (4) an integrator synthesizes these analyses into a final, interpretable judgment with a natural language explanation. Evaluated on four standard benchmarks, RAM-SD achieves a state-of-the-art Macro-F1 of 77.74%, outperforming the strong GPT-4o+CoC baseline by 7.01 points. Our framework not only sets a new performance benchmark but also provides transparent and interpretable reasoning traces, illuminating the cognitive processes behind sarcasm comprehension.
The Demon is in Ambiguity: Revisiting Situation Recognition with Single Positive Multi-Label Learning
Aug 29, 2025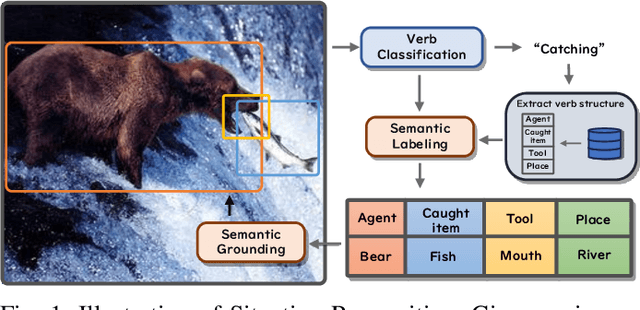
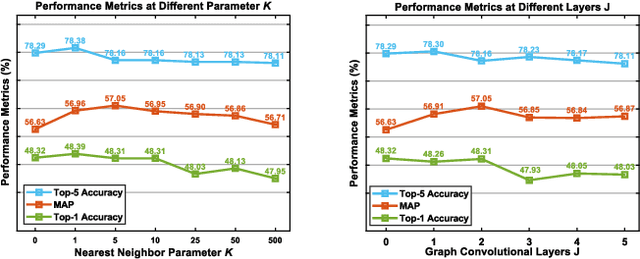
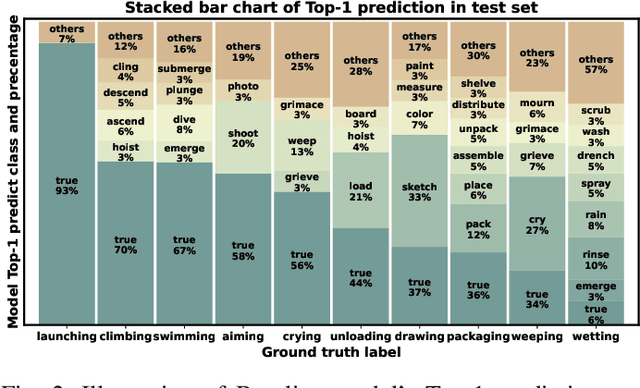
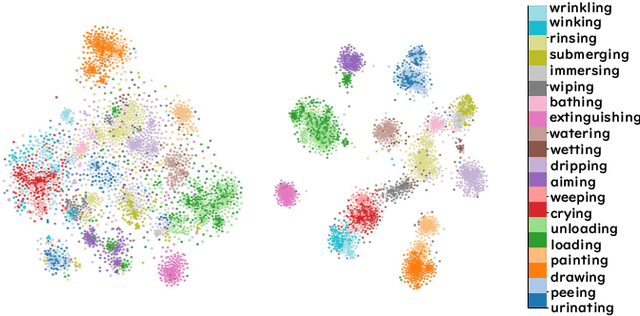
Context recognition (SR) is a fundamental task in computer vision that aims to extract structured semantic summaries from images by identifying key events and their associated entities. Specifically, given an input image, the model must first classify the main visual events (verb classification), then identify the participating entities and their semantic roles (semantic role labeling), and finally localize these entities in the image (semantic role localization). Existing methods treat verb classification as a single-label problem, but we show through a comprehensive analysis that this formulation fails to address the inherent ambiguity in visual event recognition, as multiple verb categories may reasonably describe the same image. This paper makes three key contributions: First, we reveal through empirical analysis that verb classification is inherently a multi-label problem due to the ubiquitous semantic overlap between verb categories. Second, given the impracticality of fully annotating large-scale datasets with multiple labels, we propose to reformulate verb classification as a single positive multi-label learning (SPMLL) problem - a novel perspective in SR research. Third, we design a comprehensive multi-label evaluation benchmark for SR that is carefully designed to fairly evaluate model performance in a multi-label setting. To address the challenges of SPMLL, we futher develop the Graph Enhanced Verb Multilayer Perceptron (GE-VerbMLP), which combines graph neural networks to capture label correlations and adversarial training to optimize decision boundaries. Extensive experiments on real-world datasets show that our approach achieves more than 3\% MAP improvement while remaining competitive on traditional top-1 and top-5 accuracy metrics.
LLM-Powered Proactive Data Systems
Feb 18, 2025With the power of LLMs, we now have the ability to query data that was previously impossible to query, including text, images, and video. However, despite this enormous potential, most present-day data systems that leverage LLMs are reactive, reflecting our community's desire to map LLMs to known abstractions. Most data systems treat LLMs as an opaque black box that operates on user inputs and data as is, optimizing them much like any other approximate, expensive UDFs, in conjunction with other relational operators. Such data systems do as they are told, but fail to understand and leverage what the LLM is being asked to do (i.e. the underlying operations, which may be error-prone), the data the LLM is operating on (e.g., long, complex documents), or what the user really needs. They don't take advantage of the characteristics of the operations and/or the data at hand, or ensure correctness of results when there are imprecisions and ambiguities. We argue that data systems instead need to be proactive: they need to be given more agency -- armed with the power of LLMs -- to understand and rework the user inputs and the data and to make decisions on how the operations and the data should be represented and processed. By allowing the data system to parse, rewrite, and decompose user inputs and data, or to interact with the user in ways that go beyond the standard single-shot query-result paradigm, the data system is able to address user needs more efficiently and effectively. These new capabilities lead to a rich design space where the data system takes more initiative: they are empowered to perform optimization based on the transformation operations, data characteristics, and user intent. We discuss various successful examples of how this framework has been and can be applied in real-world tasks, and present future directions for this ambitious research agenda.
TWIX: Automatically Reconstructing Structured Data from Templatized Documents
Jan 11, 2025



Many documents, that we call templatized documents, are programmatically generated by populating fields in a visual template. Effective data extraction from these documents is crucial to supporting downstream analytical tasks. Current data extraction tools often struggle with complex document layouts, incur high latency and/or cost on large datasets, and often require significant human effort, when extracting tables or values given user-specified fields from documents. The key insight of our tool, TWIX, is to predict the underlying template used to create such documents, modeling the visual and structural commonalities across documents. Data extraction based on this predicted template provides a more principled, accurate, and efficient solution at a low cost. Comprehensive evaluations on 34 diverse real-world datasets show that uncovering the template is crucial for data extraction from templatized documents. TWIX achieves over 90% precision and recall on average, outperforming tools from industry: Textract and Azure Document Intelligence, and vision-based LLMs like GPT-4-Vision, by over 25% in precision and recall. TWIX scales easily to large datasets and is 734X faster and 5836X cheaper than vision-based LLMs for extracting data from a large document collection with 817 pages.
Context Does Matter: End-to-end Panoptic Narrative Grounding with Deformable Attention Refined Matching Network
Oct 25, 2023Panoramic Narrative Grounding (PNG) is an emerging visual grounding task that aims to segment visual objects in images based on dense narrative captions. The current state-of-the-art methods first refine the representation of phrase by aggregating the most similar $k$ image pixels, and then match the refined text representations with the pixels of the image feature map to generate segmentation results. However, simply aggregating sampled image features ignores the contextual information, which can lead to phrase-to-pixel mis-match. In this paper, we propose a novel learning framework called Deformable Attention Refined Matching Network (DRMN), whose main idea is to bring deformable attention in the iterative process of feature learning to incorporate essential context information of different scales of pixels. DRMN iteratively re-encodes pixels with the deformable attention network after updating the feature representation of the top-$k$ most similar pixels. As such, DRMN can lead to accurate yet discriminative pixel representations, purify the top-$k$ most similar pixels, and consequently alleviate the phrase-to-pixel mis-match substantially.Experimental results show that our novel design significantly improves the matching results between text phrases and image pixels. Concretely, DRMN achieves new state-of-the-art performance on the PNG benchmark with an average recall improvement 3.5%. The codes are available in: https://github.com/JaMesLiMers/DRMN.
FAN-Trans: Online Knowledge Distillation for Facial Action Unit Detection
Nov 11, 2022Due to its importance in facial behaviour analysis, facial action unit (AU) detection has attracted increasing attention from the research community. Leveraging the online knowledge distillation framework, we propose the ``FANTrans" method for AU detection. Our model consists of a hybrid network of convolution and transformer blocks to learn per-AU features and to model AU co-occurrences. The model uses a pre-trained face alignment network as the feature extractor. After further transformation by a small learnable add-on convolutional subnet, the per-AU features are fed into transformer blocks to enhance their representation. As multiple AUs often appear together, we propose a learnable attention drop mechanism in the transformer block to learn the correlation between the features for different AUs. We also design a classifier that predicts AU presence by considering all AUs' features, to explicitly capture label dependencies. Finally, we make the attempt of adapting online knowledge distillation in the training stage for this task, further improving the model's performance. Experiments on the BP4D and DISFA datasets demonstrating the effectiveness of proposed method.
* 9 pages, 6 figures
Self-supervised Video-centralised Transformer for Video Face Clustering
Mar 24, 2022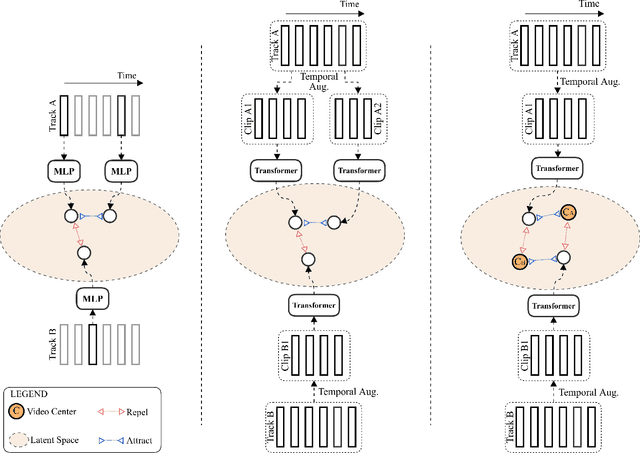

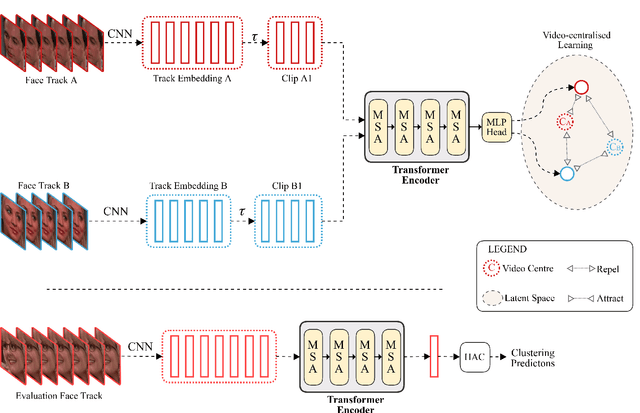
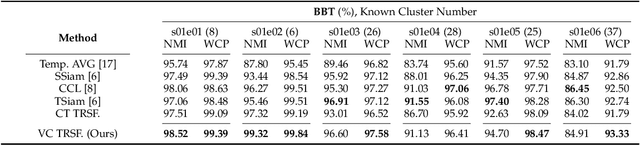
This paper presents a novel method for face clustering in videos using a video-centralised transformer. Previous works often employed contrastive learning to learn frame-level representation and used average pooling to aggregate the features along the temporal dimension. This approach may not fully capture the complicated video dynamics. In addition, despite the recent progress in video-based contrastive learning, few have attempted to learn a self-supervised clustering-friendly face representation that benefits the video face clustering task. To overcome these limitations, our method employs a transformer to directly learn video-level representations that can better reflect the temporally-varying property of faces in videos, while we also propose a video-centralised self-supervised framework to train the transformer model. We also investigate face clustering in egocentric videos, a fast-emerging field that has not been studied yet in works related to face clustering. To this end, we present and release the first large-scale egocentric video face clustering dataset named EasyCom-Clustering. We evaluate our proposed method on both the widely used Big Bang Theory (BBT) dataset and the new EasyCom-Clustering dataset. Results show the performance of our video-centralised transformer has surpassed all previous state-of-the-art methods on both benchmarks, exhibiting a self-attentive understanding of face videos.
FP-Age: Leveraging Face Parsing Attention for Facial Age Estimation in the Wild
Jun 21, 2021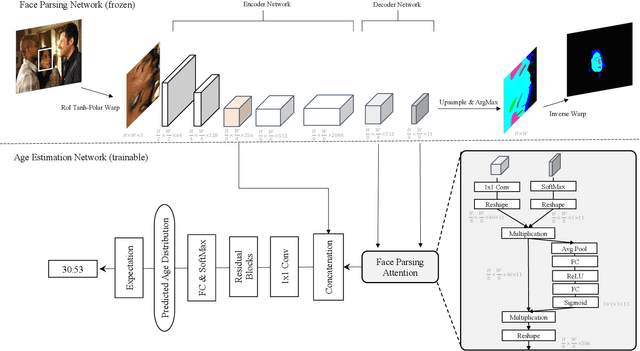
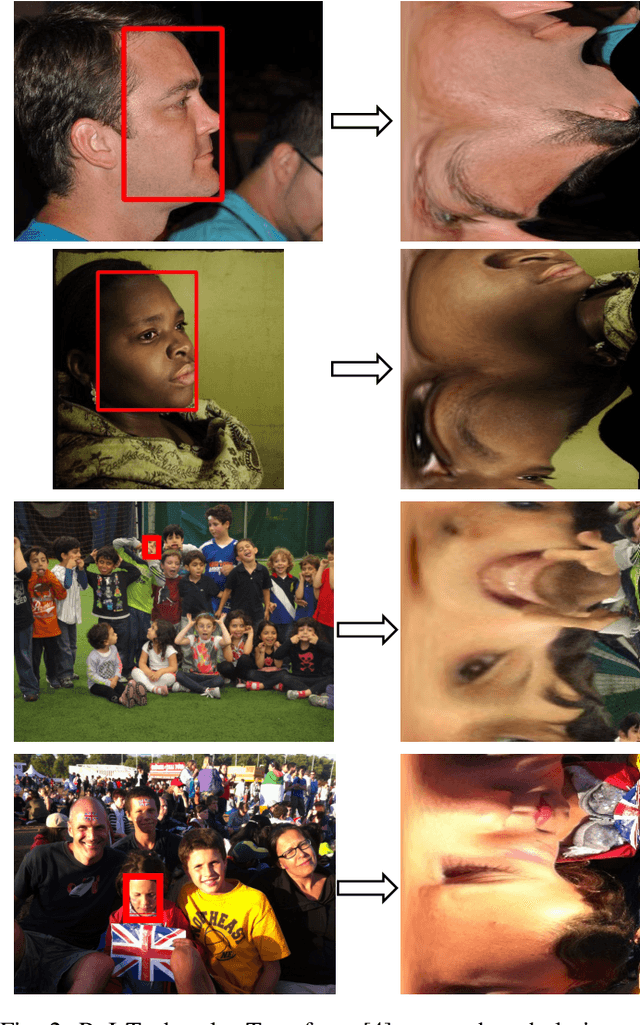

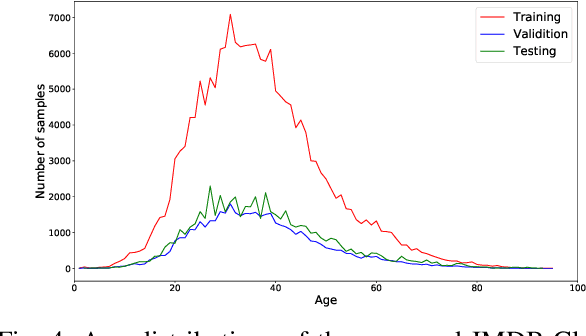
Image-based age estimation aims to predict a person's age from facial images. It is used in a variety of real-world applications. Although end-to-end deep models have achieved impressive results for age estimation on benchmark datasets, their performance in-the-wild still leaves much room for improvement due to the challenges caused by large variations in head pose, facial expressions, and occlusions. To address this issue, we propose a simple yet effective method to explicitly incorporate facial semantics into age estimation, so that the model would learn to correctly focus on the most informative facial components from unaligned facial images regardless of head pose and non-rigid deformation. To this end, we design a face parsing-based network to learn semantic information at different scales and a novel face parsing attention module to leverage these semantic features for age estimation. To evaluate our method on in-the-wild data, we also introduce a new challenging large-scale benchmark called IMDB-Clean. This dataset is created by semi-automatically cleaning the noisy IMDB-WIKI dataset using a constrained clustering method. Through comprehensive experiment on IMDB-Clean and other benchmark datasets, under both intra-dataset and cross-dataset evaluation protocols, we show that our method consistently outperforms all existing age estimation methods and achieves a new state-of-the-art performance. To the best of our knowledge, our work presents the first attempt of leveraging face parsing attention to achieve semantic-aware age estimation, which may be inspiring to other high level facial analysis tasks.