 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Video-centralised Transformer for Video Face Clustering
Paper and Code
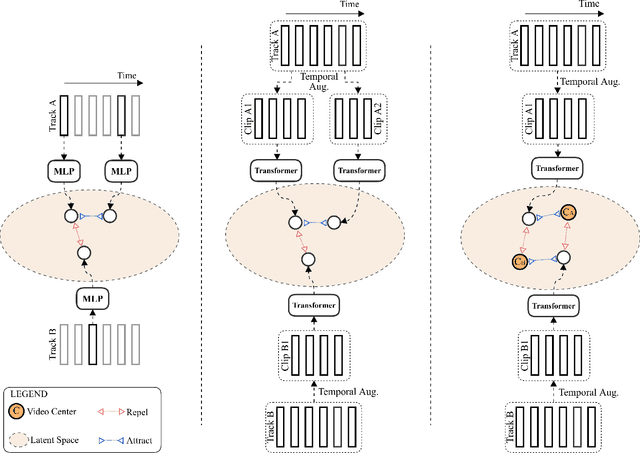

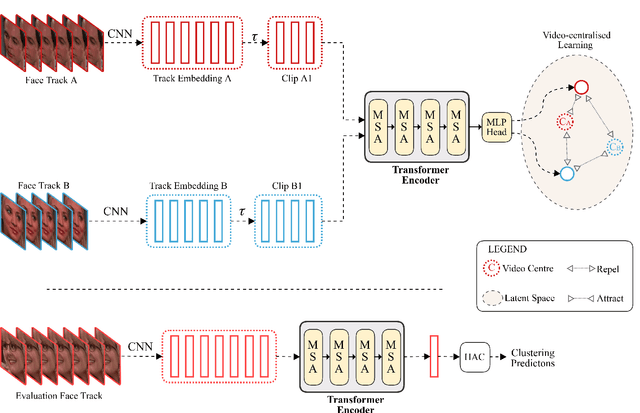
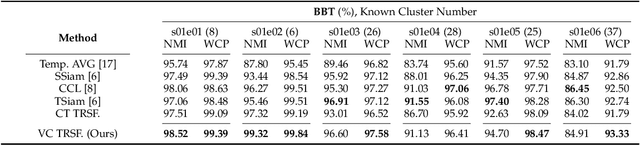
This paper presents a novel method for face clustering in videos using a video-centralised transformer. Previous works often employed contrastive learning to learn frame-level representation and used average pooling to aggregate the features along the temporal dimension. This approach may not fully capture the complicated video dynamics. In addition, despite the recent progress in video-based contrastive learning, few have attempted to learn a self-supervised clustering-friendly face representation that benefits the video face clustering task. To overcome these limitations, our method employs a transformer to directly learn video-level representations that can better reflect the temporally-varying property of faces in videos, while we also propose a video-centralised self-supervised framework to train the transformer model. We also investigate face clustering in egocentric videos, a fast-emerging field that has not been studied yet in works related to face clustering. To this end, we present and release the first large-scale egocentric video face clustering dataset named EasyCom-Clustering. We evaluate our proposed method on both the widely used Big Bang Theory (BBT) dataset and the new EasyCom-Clustering dataset. Results show the performance of our video-centralised transformer has surpassed all previous state-of-the-art methods on both benchmarks, exhibiting a self-attentive understanding of face videos.