 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing CLIP's Comprehension of 360-Degree Textual and Visual Semantics
Apr 27, 2026The dream of instantly creating rich 360-degree panoramic worlds from text is rapidly becoming a reality, yet a crucial gap exists in our ability to reliably evaluate their semantic alignment. Contrastive Language-Image Pre-training (CLIP) models, standard AI evaluators, predominantly trained on perspective image-text pairs, face an open question regarding their understanding of the unique characteristics of 360-degree panoramic image-text pairs. This paper addresses this gap by first introducing two concepts: \emph{360-degree textual semantics}, semantic information conveyed by explicit format identifiers, and \emph{360-degree visual semantics}, invariant semantics under horizontal circular shifts. To probe CLIP's comprehension of these semantics, we then propose novel evaluation methodologies using keyword manipulation and horizontal circular shifts of varying magnitudes. Rigorous statistical analyses across popular CLIP configurations reveal that: (1) CLIP models effectively leverage explicit textual identifiers, demonstrating an understanding of 360-degree textual semantics; and (2) CLIP models fail to robustly preserve semantic alignment under horizontal circular shifts, indicating limited comprehension of 360-degree visual semantics. To address this limitation, we propose a LoRA-based fine-tuning framework that explicitly instills invariance to circular shifts. Our fine-tuned models exhibit improved comprehension of 360-degree visual semantics, though with a slight degradation in original semantic evaluation performance, highlighting a fundamental trade-off in adapting CLIP to 360-degree panoramic images. Code is available at https://github.com/littlewhitesea/360Semantics.
The Curse and Blessing of Mean Bias in FP4-Quantized LLM Training
Mar 11, 2026Large language models trained on natural language exhibit pronounced anisotropy: a small number of directions concentrate disproportionate energy, while the remaining dimensions form a broad semantic tail. In low-bit training regimes, this geometry becomes numerically unstable. Because blockwise quantization scales are determined by extreme elementwise magnitudes, dominant directions stretch the dynamic range, compressing long-tail semantic variation into narrow numerical bins. We show that this instability is primarily driven by a coherent rank-one mean bias, which constitutes the dominant component of spectral anisotropy in LLM representations. This mean component emerges systematically across layers and training stages and accounts for the majority of extreme activation magnitudes, making it the principal driver of dynamic-range inflation under low precision. Crucially, because the dominant instability is rank-one, it can be eliminated through a simple source-level mean-subtraction operation. This bias-centric conditioning recovers most of the stability benefits of SVD-based spectral methods while requiring only reduction operations and standard quantization kernels. Empirical results on FP4 (W4A4G4) training show that mean removal substantially narrows the loss gap to BF16 and restores downstream performance, providing a hardware-efficient path to stable low-bit LLM training.
SD-MoE: Spectral Decomposition for Effective Expert Specialization
Feb 13, 2026Mixture-of-Experts (MoE) architectures scale Large Language Models via expert specialization induced by conditional computation. In practice, however, expert specialization often fails: some experts become functionally similar, while others functioning as de facto shared experts, limiting the effective capacity and model performance. In this work, we analysis from a spectral perspective on parameter and gradient spaces, uncover that (1) experts share highly overlapping dominant spectral components in their parameters, (2) dominant gradient subspaces are strongly aligned across experts, driven by ubiquitous low-rank structure in human corpus, and (3) gating mechanisms preferentially route inputs along these dominant directions, further limiting specialization. To address this, we propose Spectral-Decoupled MoE (SD-MoE), which decomposes both parameter and gradient in the spectral space. SD-MoE improves performance across downstream tasks, enables effective expert specialization, incurring minimal additional computation, and can be seamlessly integrated into a wide range of existing MoE architectures, including Qwen and DeepSeek.
Multi-Head Attention as a Source of Catastrophic Forgetting in MoE Transformers
Feb 13, 2026Mixture-of-Experts (MoE) architectures are often considered a natural fit for continual learning because sparse routing should localize updates and reduce interference, yet MoE Transformers still forget substantially even with sparse, well-balanced expert utilization. We attribute this gap to a pre-routing bottleneck: multi-head attention concatenates head-specific signals into a single post-attention router input, forcing routing to act on co-occurring feature compositions rather than separable head channels. We show that this router input simultaneously encodes multiple separately decodable semantic and structural factors with uneven head support, and that different feature compositions induce weakly aligned parameter-gradient directions; as a result, routing maps many distinct compositions to the same route. We quantify this collision effect via a route-wise effective composition number $N_{eff}$ and find that higher $N_{eff}$ is associated with larger old-task loss increases after continual training. Motivated by these findings, we propose MH-MoE, which performs head-wise routing over sub-representations to increase routing granularity and reduce composition collisions. On TRACE with Qwen3-0.6B/8B, MH-MoE effectively mitigates forgetting, reducing BWT on Qwen3-0.6B from 11.2% (LoRAMoE) to 4.5%.
Dispelling the Curse of Singularities in Neural Network Optimizations
Feb 01, 2026This work investigates the optimization instability of deep neural networks from a less-explored yet insightful perspective: the emergence and amplification of singularities in the parametric space. Our analysis reveals that parametric singularities inevitably grow with gradient updates and further intensify alignment with representations, leading to increased singularities in the representation space. We show that the gradient Frobenius norms are bounded by the top singular values of the weight matrices, and as training progresses, the mutually reinforcing growth of weight and representation singularities, termed the curse of singularities, relaxes these bounds, escalating the risk of sharp loss explosions. To counter this, we propose Parametric Singularity Smoothing (PSS), a lightweight, flexible, and effective method for smoothing the singular spectra of weight matrices. Extensive experiments across diverse datasets, architectures, and optimizers demonstrate that PSS mitigates instability, restores trainability even after failure, and improves both training efficiency and generalization.
Train Faster, Perform Better: Modular Adaptive Training in Over-Parameterized Models
May 13, 2024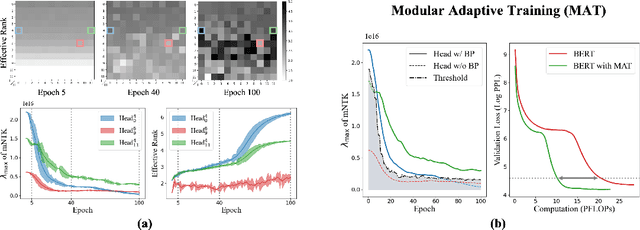

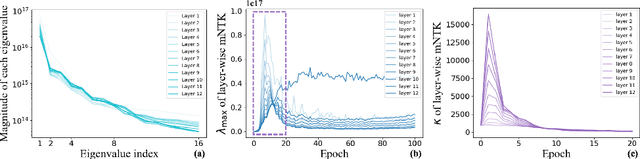

Despite their prevalence in deep-learning communities, over-parameterized models convey high demands of computational costs for proper training. This work studies the fine-grained, modular-level learning dynamics of over-parameterized models to attain a more efficient and fruitful training strategy. Empirical evidence reveals that when scaling down into network modules, such as heads in self-attention models, we can observe varying learning patterns implicitly associated with each module's trainability. To describe such modular-level learning capabilities, we introduce a novel concept dubbed modular neural tangent kernel (mNTK), and we demonstrate that the quality of a module's learning is tightly associated with its mNTK's principal eigenvalue $\lambda_{\max}$. A large $\lambda_{\max}$ indicates that the module learns features with better convergence, while those miniature ones may impact generalization negatively. Inspired by the discovery, we propose a novel training strategy termed Modular Adaptive Training (MAT) to update those modules with their $\lambda_{\max}$ exceeding a dynamic threshold selectively, concentrating the model on learning common features and ignoring those inconsistent ones. Unlike most existing training schemes with a complete BP cycle across all network modules, MAT can significantly save computations by its partially-updating strategy and can further improve performance. Experiments show that MAT nearly halves the computational cost of model training and outperforms the accuracy of baselines.
Is dataset condensation a silver bullet for healthcare data sharing?
May 05, 2023Safeguarding personal information is paramount for healthcare data sharing, a challenging issue without any silver bullet thus far. We study the prospect of a recent deep-learning advent, dataset condensation (DC), in sharing healthcare data for AI research, and the results are promising. The condensed data abstracts original records and irreversibly conceals individual-level knowledge to achieve a bona fide de-identification, which permits free sharing. Moreover, the original deep-learning utilities are well preserved in the condensed data with compressed volume and accelerated model convergences. In PhysioNet-2012, a condensed dataset of 20 samples can orient deep models attaining 80.3% test AUC of mortality prediction (versus 85.8% of 5120 original records), an inspiring discovery generalised to MIMIC-III and Coswara datasets. We also interpret the inhere privacy protections of DC through theoretical analysis and empirical evidence. Dataset condensation opens a new gate to sharing healthcare data for AI research with multiple desirable traits.
Self-supervised Video-centralised Transformer for Video Face Clustering
Mar 24, 2022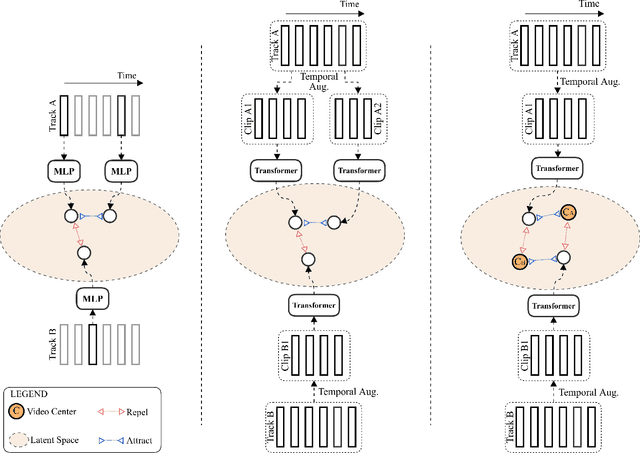

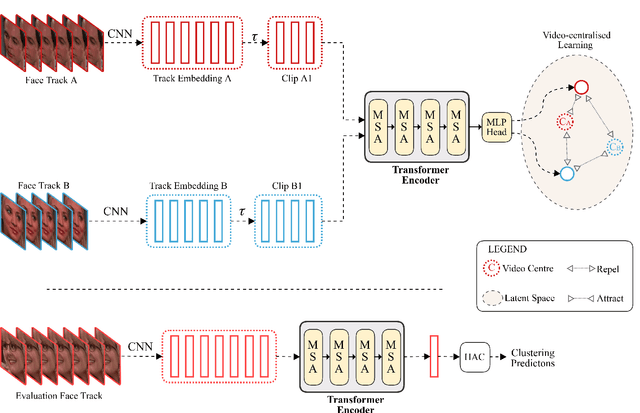
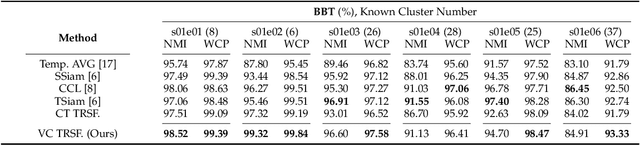
This paper presents a novel method for face clustering in videos using a video-centralised transformer. Previous works often employed contrastive learning to learn frame-level representation and used average pooling to aggregate the features along the temporal dimension. This approach may not fully capture the complicated video dynamics. In addition, despite the recent progress in video-based contrastive learning, few have attempted to learn a self-supervised clustering-friendly face representation that benefits the video face clustering task. To overcome these limitations, our method employs a transformer to directly learn video-level representations that can better reflect the temporally-varying property of faces in videos, while we also propose a video-centralised self-supervised framework to train the transformer model. We also investigate face clustering in egocentric videos, a fast-emerging field that has not been studied yet in works related to face clustering. To this end, we present and release the first large-scale egocentric video face clustering dataset named EasyCom-Clustering. We evaluate our proposed method on both the widely used Big Bang Theory (BBT) dataset and the new EasyCom-Clustering dataset. Results show the performance of our video-centralised transformer has surpassed all previous state-of-the-art methods on both benchmarks, exhibiting a self-attentive understanding of face videos.
Do Smart Glasses Dream of Sentimental Visions? Deep Emotionship Analysis for Eyewear Devices
Jan 24, 2022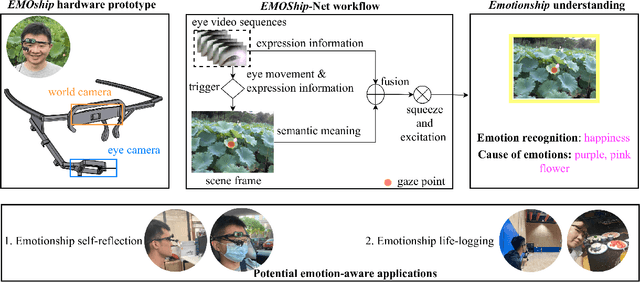

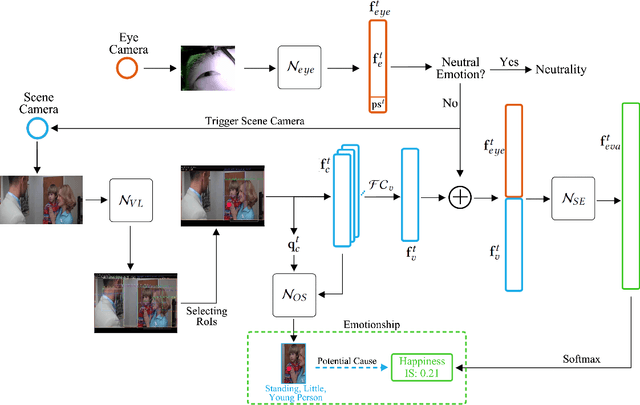
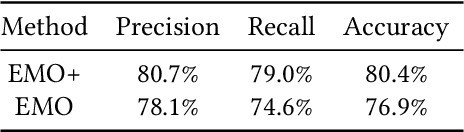
Emotion recognition in smart eyewear devices is highly valuable but challenging. One key limitation of previous works is that the expression-related information like facial or eye images is considered as the only emotional evidence. However, emotional status is not isolated; it is tightly associated with people's visual perceptions, especially those sentimental ones. However, little work has examined such associations to better illustrate the cause of different emotions. In this paper, we study the emotionship analysis problem in eyewear systems, an ambitious task that requires not only classifying the user's emotions but also semantically understanding the potential cause of such emotions. To this end, we devise EMOShip, a deep-learning-based eyewear system that can automatically detect the wearer's emotional status and simultaneously analyze its associations with semantic-level visual perceptions. Experimental studies with 20 participants demonstrate that, thanks to the emotionship awareness, EMOShip not only achieves superior emotion recognition accuracy over existing methods (80.2% vs. 69.4%), but also provides a valuable understanding of the cause of emotions. Pilot studies with 20 participants further motivate the potential use of EMOShip to empower emotion-aware applications, such as emotionship self-reflection and emotionship life-logging.
MemX: An Attention-Aware Smart Eyewear System for Personalized Moment Auto-capture
May 03, 2021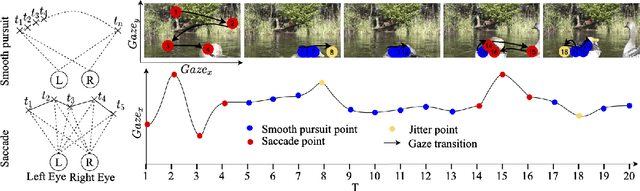

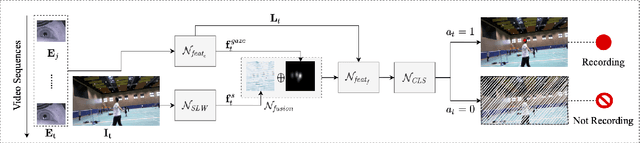
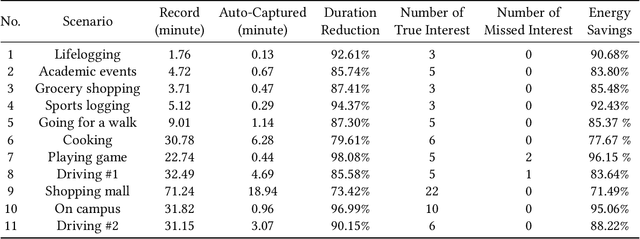
This work presents MemX: a biologically-inspired attention-aware eyewear system developed with the goal of pursuing the long-awaited vision of a personalized visual Memex. MemX captures human visual attention on the fly, analyzes the salient visual content, and records moments of personal interest in the form of compact video snippets. Accurate attentive scene detection and analysis on resource-constrained platforms is challenging because these tasks are computation and energy intensive. We propose a new temporal visual attention network that unifies human visual attention tracking and salient visual content analysis. Attention tracking focuses computation-intensive video analysis on salient regions, while video analysis makes human attention detection and tracking more accurate. Using the YouTube-VIS dataset and 30 participants, we experimentally show that MemX significantly improves the attention tracking accuracy over the eye-tracking-alone method, while maintaining high system energy efficiency. We have also conducted 11 in-field pilot studies across a range of daily usage scenarios, which demonstrate the feasibility and potential benefits of MemX.