 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Curse and Blessing of Mean Bias in FP4-Quantized LLM Training
Mar 11, 2026Large language models trained on natural language exhibit pronounced anisotropy: a small number of directions concentrate disproportionate energy, while the remaining dimensions form a broad semantic tail. In low-bit training regimes, this geometry becomes numerically unstable. Because blockwise quantization scales are determined by extreme elementwise magnitudes, dominant directions stretch the dynamic range, compressing long-tail semantic variation into narrow numerical bins. We show that this instability is primarily driven by a coherent rank-one mean bias, which constitutes the dominant component of spectral anisotropy in LLM representations. This mean component emerges systematically across layers and training stages and accounts for the majority of extreme activation magnitudes, making it the principal driver of dynamic-range inflation under low precision. Crucially, because the dominant instability is rank-one, it can be eliminated through a simple source-level mean-subtraction operation. This bias-centric conditioning recovers most of the stability benefits of SVD-based spectral methods while requiring only reduction operations and standard quantization kernels. Empirical results on FP4 (W4A4G4) training show that mean removal substantially narrows the loss gap to BF16 and restores downstream performance, providing a hardware-efficient path to stable low-bit LLM training.
Multi-Head Attention as a Source of Catastrophic Forgetting in MoE Transformers
Feb 13, 2026Mixture-of-Experts (MoE) architectures are often considered a natural fit for continual learning because sparse routing should localize updates and reduce interference, yet MoE Transformers still forget substantially even with sparse, well-balanced expert utilization. We attribute this gap to a pre-routing bottleneck: multi-head attention concatenates head-specific signals into a single post-attention router input, forcing routing to act on co-occurring feature compositions rather than separable head channels. We show that this router input simultaneously encodes multiple separately decodable semantic and structural factors with uneven head support, and that different feature compositions induce weakly aligned parameter-gradient directions; as a result, routing maps many distinct compositions to the same route. We quantify this collision effect via a route-wise effective composition number $N_{eff}$ and find that higher $N_{eff}$ is associated with larger old-task loss increases after continual training. Motivated by these findings, we propose MH-MoE, which performs head-wise routing over sub-representations to increase routing granularity and reduce composition collisions. On TRACE with Qwen3-0.6B/8B, MH-MoE effectively mitigates forgetting, reducing BWT on Qwen3-0.6B from 11.2% (LoRAMoE) to 4.5%.
SD-MoE: Spectral Decomposition for Effective Expert Specialization
Feb 13, 2026Mixture-of-Experts (MoE) architectures scale Large Language Models via expert specialization induced by conditional computation. In practice, however, expert specialization often fails: some experts become functionally similar, while others functioning as de facto shared experts, limiting the effective capacity and model performance. In this work, we analysis from a spectral perspective on parameter and gradient spaces, uncover that (1) experts share highly overlapping dominant spectral components in their parameters, (2) dominant gradient subspaces are strongly aligned across experts, driven by ubiquitous low-rank structure in human corpus, and (3) gating mechanisms preferentially route inputs along these dominant directions, further limiting specialization. To address this, we propose Spectral-Decoupled MoE (SD-MoE), which decomposes both parameter and gradient in the spectral space. SD-MoE improves performance across downstream tasks, enables effective expert specialization, incurring minimal additional computation, and can be seamlessly integrated into a wide range of existing MoE architectures, including Qwen and DeepSeek.
Dispelling the Curse of Singularities in Neural Network Optimizations
Feb 01, 2026This work investigates the optimization instability of deep neural networks from a less-explored yet insightful perspective: the emergence and amplification of singularities in the parametric space. Our analysis reveals that parametric singularities inevitably grow with gradient updates and further intensify alignment with representations, leading to increased singularities in the representation space. We show that the gradient Frobenius norms are bounded by the top singular values of the weight matrices, and as training progresses, the mutually reinforcing growth of weight and representation singularities, termed the curse of singularities, relaxes these bounds, escalating the risk of sharp loss explosions. To counter this, we propose Parametric Singularity Smoothing (PSS), a lightweight, flexible, and effective method for smoothing the singular spectra of weight matrices. Extensive experiments across diverse datasets, architectures, and optimizers demonstrate that PSS mitigates instability, restores trainability even after failure, and improves both training efficiency and generalization.
White-Box Op-Amp Design via Human-Mimicking Reasoning
Jan 29, 2026This brief proposes \emph{White-Op}, an interpretable operational amplifier (op-amp) parameter design framework based on the human-mimicking reasoning of large-language-model agents. We formalize the implicit human reasoning mechanism into explicit steps of \emph{\textbf{introducing hypothetical constraints}}, and develop an iterative, human-like \emph{\textbf{hypothesis-verification-decision}} workflow. Specifically, the agent is guided to introduce hypothetical constraints to derive and properly regulate positions of symbolically tractable poles and zeros, thus formulating a closed-form mathematical optimization problem, which is then solved programmatically and verified via simulation. Theory-simulation result analysis guides the decision-making for refinement. Experiments on 9 op-amp topologies show that, unlike the uninterpretable black-box baseline which finally fails in 5 topologies, White-Op achieves reliable, interpretable behavioral-level designs with only 8.52\% theoretical prediction error and the design functionality retains after transistor-level mapping for all topologies. White-Op is open-sourced at \textcolor{blue}{https://github.com/zhchenfdu/whiteop}.
Bridging the Initialization Gap: A Co-Optimization Framework for Mixed-Size Global Placement
Nov 13, 2025Global placement is a critical step with high computational complexity in VLSI physical design. Modern analytical placers formulate the placement problem as a nonlinear optimization, where initialization strongly affects both convergence behavior and final placement quality. However, existing initialization methods exhibit a trade-off: area-aware initializers account for cell areas but are computationally expensive and can dominate total runtime, while fast point-based initializers ignore cell area, leading to a modeling gap that impairs convergence and solution quality. We propose a lightweight co-optimization framework that bridges this initialization gap through two strategies. First, an area-hint refinement initializer incorporates heuristic cell area information into a signed graph signal by augmenting the netlist graph with virtual nodes and negative-weight edges, yielding an area-aware and spectrally smooth placement initialization. Second, a macro-schedule placement procedure progressively restores area constraints, enabling a smooth transition from the refined initializer to the full area-aware objective and producing high-quality placement results. We evaluate the framework on macro-heavy ISPD2005 academic benchmarks and two real-world industrial designs across two technology nodes (12 cases in total). Experimental results show that our method consistently improves half-perimeter wirelength (HPWL) over point-based initializers in 11 out of 12 cases, achieving up to 2.2% HPWL reduction, while running approximately 100 times faster than the state-of-the-art area-aware initializer.
AnalogSeeker: An Open-source Foundation Language Model for Analog Circuit Design
Aug 14, 2025In this paper, we propose AnalogSeeker, an effort toward an open-source foundation language model for analog circuit design, with the aim of integrating domain knowledge and giving design assistance. To overcome the scarcity of data in this field, we employ a corpus collection strategy based on the domain knowledge framework of analog circuits. High-quality, accessible textbooks across relevant subfields are systematically curated and cleaned into a textual domain corpus. To address the complexity of knowledge of analog circuits, we introduce a granular domain knowledge distillation method. Raw, unlabeled domain corpus is decomposed into typical, granular learning nodes, where a multi-agent framework distills implicit knowledge embedded in unstructured text into question-answer data pairs with detailed reasoning processes, yielding a fine-grained, learnable dataset for fine-tuning. To address the unexplored challenges in training analog circuit foundation models, we explore and share our training methods through both theoretical analysis and experimental validation. We finally establish a fine-tuning-centric training paradigm, customizing and implementing a neighborhood self-constrained supervised fine-tuning algorithm. This approach enhances training outcomes by constraining the perturbation magnitude between the model's output distributions before and after training. In practice, we train the Qwen2.5-32B-Instruct model to obtain AnalogSeeker, which achieves 85.04% accuracy on AMSBench-TQA, the analog circuit knowledge evaluation benchmark, with a 15.67% point improvement over the original model and is competitive with mainstream commercial models. Furthermore, AnalogSeeker also shows effectiveness in the downstream operational amplifier design task. AnalogSeeker is open-sourced at https://huggingface.co/analogllm/analogseeker for research use.
Bidirectional Knowledge Distillation for Enhancing Sequential Recommendation with Large Language Models
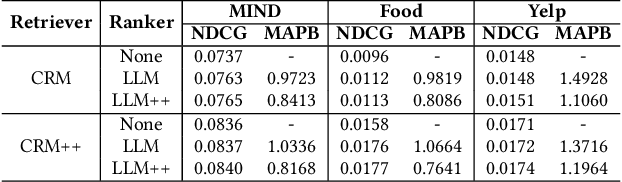
May 23, 2025Large language models (LLMs) have demonstrated exceptional performance in understanding and generating semantic patterns, making them promising candidates for sequential recommendation tasks. However, when combined with conventional recommendation models (CRMs), LLMs often face challenges related to high inference costs and static knowledge transfer methods. In this paper, we propose a novel mutual distillation framework, LLMD4Rec, that fosters dynamic and bidirectional knowledge exchange between LLM-centric and CRM-based recommendation systems. Unlike traditional unidirectional distillation methods, LLMD4Rec enables iterative optimization by alternately refining both models, enhancing the semantic understanding of CRMs and enriching LLMs with collaborative signals from user-item interactions. By leveraging sample-wise adaptive weighting and aligning output distributions, our approach eliminates the need for additional parameters while ensuring effective knowledge transfer. Extensive experiments on real-world datasets demonstrate that LLMD4Rec significantly improves recommendation accuracy across multiple benchmarks without increasing inference costs. This method provides a scalable and efficient solution for combining the strengths of both LLMs and CRMs in sequential recommendation systems.
The Power of Graph Signal Processing for Chip Placement Acceleration
Feb 24, 2025

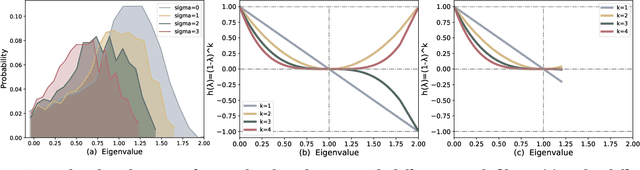
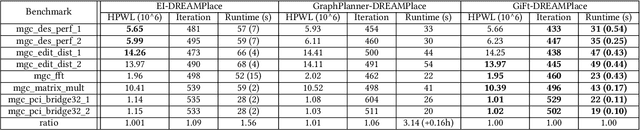
Placement is a critical task with high computation complexity in VLSI physical design. Modern analytical placers formulate the placement objective as a nonlinear optimization task, which suffers a long iteration time. To accelerate and enhance the placement process, recent studies have turned to deep learning-based approaches, particularly leveraging graph convolution networks (GCNs). However, learning-based placers require time- and data-consuming model training due to the complexity of circuit placement that involves large-scale cells and design-specific graph statistics. This paper proposes GiFt, a parameter-free technique for accelerating placement, rooted in graph signal processing. GiFt excels at capturing multi-resolution smooth signals of circuit graphs to generate optimized placement solutions without the need for time-consuming model training, and meanwhile significantly reduces the number of iterations required by analytical placers. Experimental results show that GiFt significantly improving placement efficiency, while achieving competitive or superior performance compared to state-of-the-art placers. In particular, compared to DREAMPlace, the recently proposed GPU-accelerated analytical placer, GF-Placer improves total runtime over 45%.
Enhancing LLM-Based Recommendations Through Personalized Reasoning
Feb 19, 2025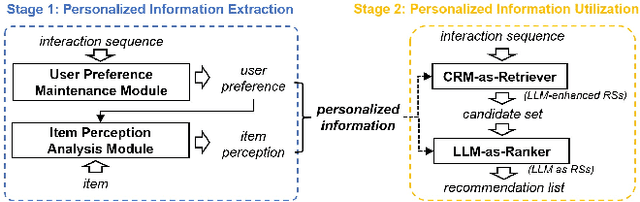
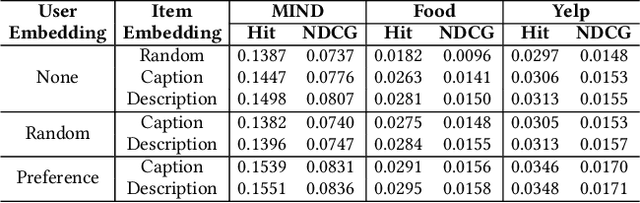
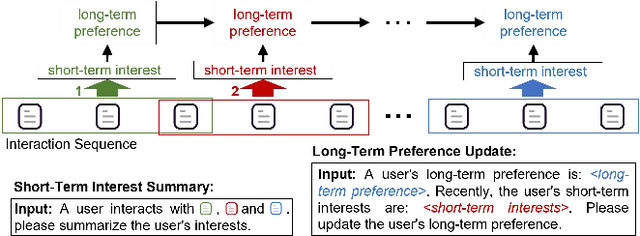
Current recommendation systems powered by large language models (LLMs) often underutilize their reasoning capabilities due to a lack of explicit logical structuring. To address this limitation, we introduce CoT-Rec, a framework that integrates Chain-of-Thought (CoT) reasoning into LLM-driven recommendations by incorporating two crucial processes: user preference analysis and item perception evaluation. CoT-Rec operates in two key phases: (1) personalized data extraction, where user preferences and item perceptions are identified, and (2) personalized data application, where this information is leveraged to refine recommendations. Our experimental analysis demonstrates that CoT-Rec improves recommendation accuracy by making better use of LLMs' reasoning potential. The implementation is publicly available at https://anonymous.4open.science/r/CoT-Rec.