 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreamMemBench: Streaming Evaluation of Agent Memory for Future-Oriented Assistance
Jun 12, 2026A central role of personal-agent memory is to turn stored information and prior interactions into future-oriented assistance. In daily use, useful cues come from what the agent observes and how the user interacts with the agent, and the agent must carry them forward from the current request to similar future tasks. Existing memory benchmarks usually test dialogue recall or task improvement in isolation, leaving the trajectory from streaming observations to later assistance largely untested. We introduce StreamMemBench, a streaming benchmark that constructs a two-step task sequence around each evidence anchor from EgoLife egocentric streams. The initial task tests evidence use, while the follow-up task tests whether feedback and interaction experience are reused. Four metrics diagnose evidence recall, initial evidence use, feedback incorporation, and follow-up reuse. Experiments with eight memory systems across two backbones show that current systems often fail to use observed evidence or turn feedback into reliable follow-up behavior, even when evidence is stored or feedback is incorporated locally. StreamMemBench is publicly available at https://github.com/landian60/StreamMemBench.
From Hidden Profiles to Governable Personalization: Recommender Systems in the Age of LLM Agents
Apr 22, 2026Personalization has traditionally depended on platform-specific user models that are optimized for prediction but remain largely inaccessible to the people they describe. As LLM-based assistants increasingly mediate search, shopping, travel, and content access, this arrangement may be giving way to a new personalization stack in which user representation is no longer confined to isolated platforms. In this paper, we argue that the key issue is not simply that large language models can enhance recommendation quality, but that they reconfigure where and how user representations are produced, exposed, and acted upon. We propose a shift from hidden platform profiling toward governable personalization, where user representations may become more inspectable, revisable, portable, and consequential across services. Building on this view, we identify five research fronts for recommender systems: transparent yet privacy-preserving user modeling, intent translation and alignment, cross-domain representation and memory design, trustworthy commercialization in assistant-mediated environments, and operational mechanisms for ownership, access, and accountability. We position these not as isolated technical challenges, but as interconnected design problems created by the emergence of LLM agents as intermediaries between users and digital platforms. We argue that the future of recommender systems will depend not only on better inference, but on building personalization systems that users can meaningfully understand, shape, and govern.
Transparent and Controllable Recommendation Filtering via Multimodal Multi-Agent Collaboration
Apr 19, 2026While personalized recommender systems excel at content discovery, they frequently expose users to undesirable or discomforting information, highlighting the critical need for user-centric filtering tools. Current methods leveraging Large Language Models (LLMs) struggle with two major bottlenecks: they lack multimodal awareness to identify visually inappropriate content, and they are highly prone to "over-association" -- incorrectly generalizing a user's specific dislike (e.g., anxiety-inducing marketing) to block benign, educational materials. These unconstrained hallucinations lead to a high volume of false positives, ultimately undermining user agency. To overcome these challenges, we introduce a novel framework that integrates end-to-cloud collaboration, multimodal perception, and multi-agent orchestration. Our system employs a fact-grounded adjudication pipeline to eliminate inferential hallucinations. Furthermore, it constructs a dynamic, two-tier preference graph that allows for explicit, human-in-the-loop modifications (via Delta-adjustments), explicitly preventing the algorithm from catastrophically forgetting fine-grained user intents. Evaluated on an adversarial dataset comprising 473 highly confusing samples, the proposed architecture effectively curbed over-association, decreasing the false positive rate by 74.3% and achieving nearly twice the F1-Score of traditional text-only baselines. Additionally, a 7-day longitudinal field study with 19 participants demonstrated robust intent alignment and enhanced governance efficiency. User feedback confirmed that the framework drastically improves algorithmic transparency, rebuilds user control, and alleviates the fear of missing out (FOMO), paving the way for transparent human-AI co-governance in personalized feeds.
Drift-Aware Continual Tokenization for Generative Recommendation
Mar 31, 2026Generative recommendation commonly adopts a two-stage pipeline in which a learnable tokenizer maps items to discrete token sequences (i.e. identifiers) and an autoregressive generative recommender model (GRM) performs prediction based on these identifiers. Recent tokenizers further incorporate collaborative signals so that items with similar user-behavior patterns receive similar codes, substantially improving recommendation quality. However, real-world environments evolve continuously: new items cause identifier collision and shifts, while new interactions induce collaborative drift in existing items (e.g., changing co-occurrence patterns and popularity). Fully retraining both tokenizer and GRM is often prohibitively expensive, yet naively fine-tuning the tokenizer can alter token sequences for the majority of existing items, undermining the GRM's learned token-embedding alignment. To balance plasticity and stability for collaborative tokenizers, we propose DACT, a Drift-Aware Continual Tokenization framework with two stages: (i) tokenizer fine-tuning, augmented with a jointly trained Collaborative Drift Identification Module (CDIM) that outputs item-level drift confidence and enables differentiated optimization for drifting and stationary items; and (ii) hierarchical code reassignment using a relaxed-to-strict strategy to update token sequences while limiting unnecessary changes. Experiments on three real-world datasets with two representative GRMs show that DACT consistently achieves better performance than baselines, demonstrating effective adaptation to collaborative evolution with reduced disruption to prior knowledge. Our implementation is publicly available at https://github.com/HomesAmaranta/DACT for reproducibility.
Feature-Indexed Federated Recommendation with Residual-Quantized Codebooks
Jan 26, 2026Federated recommendation provides a privacy-preserving solution for training recommender systems without centralizing user interactions. However, existing methods follow an ID-indexed communication paradigm that transmit whole item embeddings between clients and the server, which has three major limitations: 1) consumes uncontrollable communication resources, 2) the uploaded item information cannot generalize to related non-interacted items, and 3) is sensitive to client noisy feedback. To solve these problems, it is necessary to fundamentally change the existing ID-indexed communication paradigm. Therefore, we propose a feature-indexed communication paradigm that transmits feature code embeddings as codebooks rather than raw item embeddings. Building on this paradigm, we present RQFedRec, which assigns each item a list of discrete code IDs via Residual Quantization (RQ)-Kmeans. Each client generates and trains code embeddings as codebooks based on discrete code IDs provided by the server, and the server collects and aggregates these codebooks rather than item embeddings. This design makes communication controllable since the codebooks could cover all items, enabling updates to propagate across related items in same code ID. In addition, since code embedding represents many items, which is more robust to a single noisy item. To jointly capture semantic and collaborative information, RQFedRec further adopts a collaborative-semantic dual-channel aggregation with a curriculum strategy that emphasizes semantic codes early and gradually increases the contribution of collaborative codes over training. Extensive experiments on real-world datasets demonstrate that RQFedRec consistently outperforms state-of-the-art federated recommendation baselines while significantly reducing communication overhead.
Bidirectional Knowledge Distillation for Enhancing Sequential Recommendation with Large Language Models
May 23, 2025Large language models (LLMs) have demonstrated exceptional performance in understanding and generating semantic patterns, making them promising candidates for sequential recommendation tasks. However, when combined with conventional recommendation models (CRMs), LLMs often face challenges related to high inference costs and static knowledge transfer methods. In this paper, we propose a novel mutual distillation framework, LLMD4Rec, that fosters dynamic and bidirectional knowledge exchange between LLM-centric and CRM-based recommendation systems. Unlike traditional unidirectional distillation methods, LLMD4Rec enables iterative optimization by alternately refining both models, enhancing the semantic understanding of CRMs and enriching LLMs with collaborative signals from user-item interactions. By leveraging sample-wise adaptive weighting and aligning output distributions, our approach eliminates the need for additional parameters while ensuring effective knowledge transfer. Extensive experiments on real-world datasets demonstrate that LLMD4Rec significantly improves recommendation accuracy across multiple benchmarks without increasing inference costs. This method provides a scalable and efficient solution for combining the strengths of both LLMs and CRMs in sequential recommendation systems.
EcomScriptBench: A Multi-task Benchmark for E-commerce Script Planning via Step-wise Intention-Driven Product Association
May 21, 2025Goal-oriented script planning, or the ability to devise coherent sequences of actions toward specific goals, is commonly employed by humans to plan for typical activities. In e-commerce, customers increasingly seek LLM-based assistants to generate scripts and recommend products at each step, thereby facilitating convenient and efficient shopping experiences. However, this capability remains underexplored due to several challenges, including the inability of LLMs to simultaneously conduct script planning and product retrieval, difficulties in matching products caused by semantic discrepancies between planned actions and search queries, and a lack of methods and benchmark data for evaluation. In this paper, we step forward by formally defining the task of E-commerce Script Planning (EcomScript) as three sequential subtasks. We propose a novel framework that enables the scalable generation of product-enriched scripts by associating products with each step based on the semantic similarity between the actions and their purchase intentions. By applying our framework to real-world e-commerce data, we construct the very first large-scale EcomScript dataset, EcomScriptBench, which includes 605,229 scripts sourced from 2.4 million products. Human annotations are then conducted to provide gold labels for a sampled subset, forming an evaluation benchmark. Extensive experiments reveal that current (L)LMs face significant challenges with EcomScript tasks, even after fine-tuning, while injecting product purchase intentions improves their performance.
FedCIA: Federated Collaborative Information Aggregation for Privacy-Preserving Recommendation
Apr 19, 2025Recommendation algorithms rely on user historical interactions to deliver personalized suggestions, which raises significant privacy concerns. Federated recommendation algorithms tackle this issue by combining local model training with server-side model aggregation, where most existing algorithms use a uniform weighted summation to aggregate item embeddings from different client models. This approach has three major limitations: 1) information loss during aggregation, 2) failure to retain personalized local features, and 3) incompatibility with parameter-free recommendation algorithms. To address these limitations, we first review the development of recommendation algorithms and recognize that their core function is to share collaborative information, specifically the global relationship between users and items. With this understanding, we propose a novel aggregation paradigm named collaborative information aggregation, which focuses on sharing collaborative information rather than item parameters. Based on this new paradigm, we introduce the federated collaborative information aggregation (FedCIA) method for privacy-preserving recommendation. This method requires each client to upload item similarity matrices for aggregation, which allows clients to align their local models without constraining embeddings to a unified vector space. As a result, it mitigates information loss caused by direct summation, preserves the personalized embedding distributions of individual clients, and supports the aggregation of parameter-free models. Theoretical analysis and experimental results on real-world datasets demonstrate the superior performance of FedCIA compared with the state-of-the-art federated recommendation algorithms. Code is available at https://github.com/Mingzhe-Han/FedCIA.
UXAgent: A System for Simulating Usability Testing of Web Design with LLM Agents
Apr 13, 2025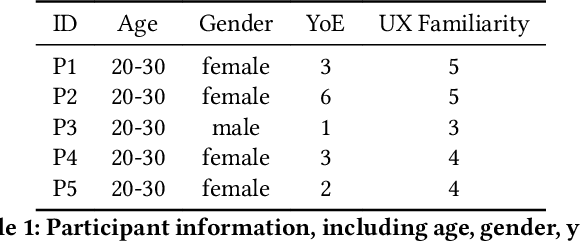
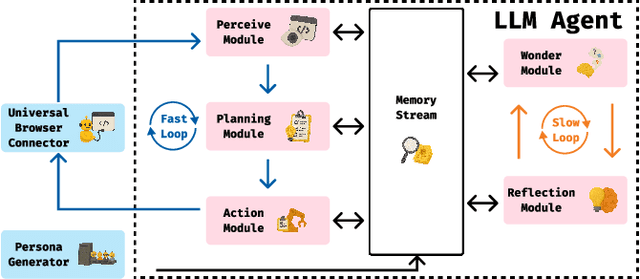
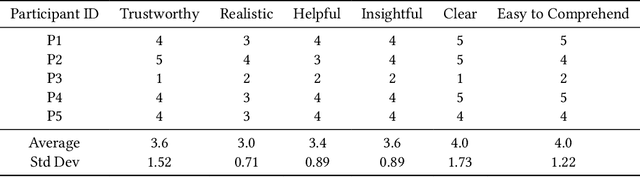
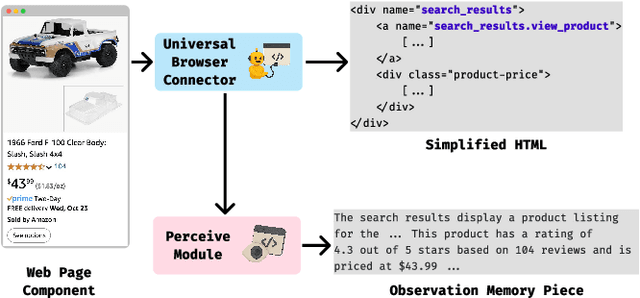
Usability testing is a fundamental research method that user experience (UX) researchers use to evaluate and iterate a web design, but\textbf{ how to evaluate and iterate the usability testing study design } itself? Recent advances in Large Language Model-simulated Agent (\textbf{LLM Agent}) research inspired us to design \textbf{UXAgent} to support UX researchers in evaluating and reiterating their usability testing study design before they conduct the real human-subject study. Our system features a Persona Generator module, an LLM Agent module, and a Universal Browser Connector module to automatically generate thousands of simulated users to interactively test the target website. The system also provides an Agent Interview Interface and a Video Replay Interface so that the UX researchers can easily review and analyze the generated qualitative and quantitative log data. Through a heuristic evaluation, five UX researcher participants praised the innovation of our system but also expressed concerns about the future of LLM Agent usage in UX studies.
Enhancing LLM-Based Recommendations Through Personalized Reasoning
Feb 19, 2025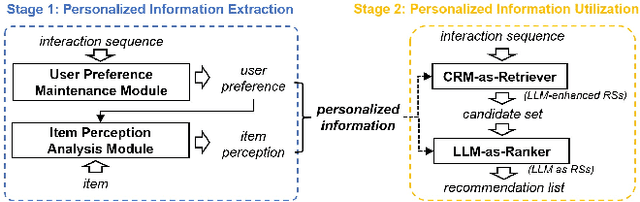
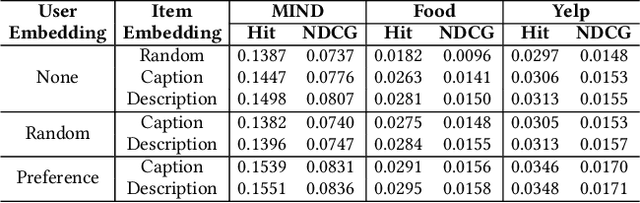
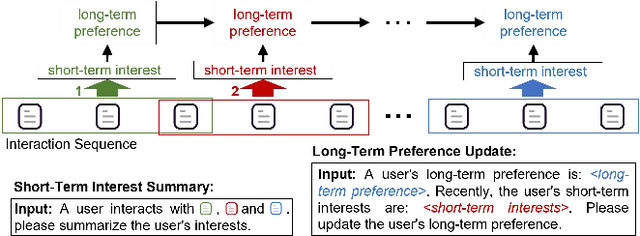
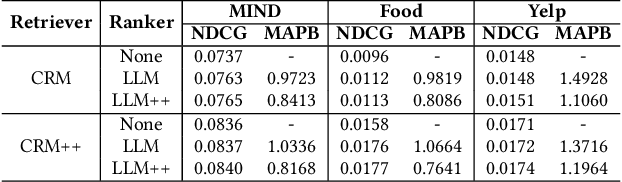
Current recommendation systems powered by large language models (LLMs) often underutilize their reasoning capabilities due to a lack of explicit logical structuring. To address this limitation, we introduce CoT-Rec, a framework that integrates Chain-of-Thought (CoT) reasoning into LLM-driven recommendations by incorporating two crucial processes: user preference analysis and item perception evaluation. CoT-Rec operates in two key phases: (1) personalized data extraction, where user preferences and item perceptions are identified, and (2) personalized data application, where this information is leveraged to refine recommendations. Our experimental analysis demonstrates that CoT-Rec improves recommendation accuracy by making better use of LLMs' reasoning potential. The implementation is publicly available at https://anonymous.4open.science/r/CoT-Rec.