 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeco: Extending Personal Physical Objects into Pervasive AI Companion through a Dual-Embodiment Framework
May 05, 2026Individuals frequently form deep attachments to physical objects (e.g., plush toys) that usually cannot sense or respond to their emotions. While AI companions offer responsiveness and personalization, they exist independently of these physical objects and lack an ongoing connection to them. To bridge this gap, we conducted a formative study (N=9) to explore how digital agents could inherit and extend the emotional bond, deriving four design principles (Faithful Identity, Calibrated Agency, Ambient Presence, and Reciprocal Memory). We then present the Dual-Embodiment Companion Framework, instantiated as Deco, a mobile system integrating multimodal Large Language Models (LLMs) and Augmented Reality to create synchronized digital embodiments of users' physical companions. A within-subjects study (N=25) showed Deco significantly outperformed a personalized LLM-empowered digital companion baseline on perceived companionship, emotional bond, and design-principle scales (all p<0.01). A seven-day field deployment (N=17) showed sustained engagement, subjective well-being improvement (p=.040), and three key relational patterns: digital activities retroactively vitalized physical objects, bond deepening was driven by emotional engagement depth rather than interaction frequency, and users sustained bonds while actively navigating digital companions' AI nature. This work highlights a promising alternative for designing digital companions: moving from creating new relationships to dual embodiment, where digital agents seamlessly extend the emotional history of physical objects.
DPRF: A Generalizable Dynamic Persona Refinement Framework for Optimizing Behavior Alignment Between Personalized LLM Role-Playing Agents and Humans
Oct 16, 2025The emerging large language model role-playing agents (LLM RPAs) aim to simulate individual human behaviors, but the persona fidelity is often undermined by manually-created profiles (e.g., cherry-picked information and personality characteristics) without validating the alignment with the target individuals. To address this limitation, our work introduces the Dynamic Persona Refinement Framework (DPRF).DPRF aims to optimize the alignment of LLM RPAs' behaviors with those of target individuals by iteratively identifying the cognitive divergence, either through free-form or theory-grounded, structured analysis, between generated behaviors and human ground truth, and refining the persona profile to mitigate these divergences.We evaluate DPRF with five LLMs on four diverse behavior-prediction scenarios: formal debates, social media posts with mental health issues, public interviews, and movie reviews.DPRF can consistently improve behavioral alignment considerably over baseline personas and generalizes across models and scenarios.Our work provides a robust methodology for creating high-fidelity persona profiles and enhancing the validity of downstream applications, such as user simulation, social studies, and personalized AI.
SurgWound-Bench: A Benchmark for Surgical Wound Diagnosis
Aug 21, 2025Surgical site infection (SSI) is one of the most common and costly healthcare-associated infections and and surgical wound care remains a significant clinical challenge in preventing SSIs and improving patient outcomes. While recent studies have explored the use of deep learning for preliminary surgical wound screening, progress has been hindered by concerns over data privacy and the high costs associated with expert annotation. Currently, no publicly available dataset or benchmark encompasses various types of surgical wounds, resulting in the absence of an open-source Surgical-Wound screening tool. To address this gap: (1) we present SurgWound, the first open-source dataset featuring a diverse array of surgical wound types. It contains 697 surgical wound images annotated by 3 professional surgeons with eight fine-grained clinical attributes. (2) Based on SurgWound, we introduce the first benchmark for surgical wound diagnosis, which includes visual question answering (VQA) and report generation tasks to comprehensively evaluate model performance. (3) Furthermore, we propose a three-stage learning framework, WoundQwen, for surgical wound diagnosis. In the first stage, we employ five independent MLLMs to accurately predict specific surgical wound characteristics. In the second stage, these predictions serve as additional knowledge inputs to two MLLMs responsible for diagnosing outcomes, which assess infection risk and guide subsequent interventions. In the third stage, we train a MLLM that integrates the diagnostic results from the previous two stages to produce a comprehensive report. This three-stage framework can analyze detailed surgical wound characteristics and provide subsequent instructions to patients based on surgical images, paving the way for personalized wound care, timely intervention, and improved patient outcomes.
Multi-Agent-as-Judge: Aligning LLM-Agent-Based Automated Evaluation with Multi-Dimensional Human Evaluation
Jul 28, 2025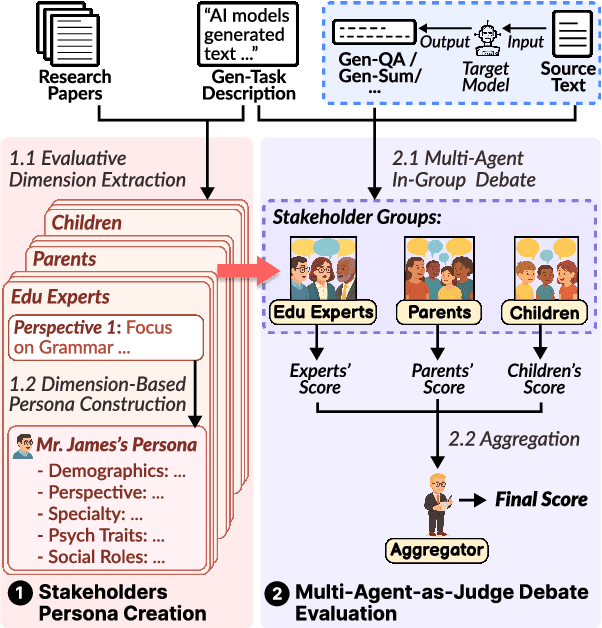



Nearly all human work is collaborative; thus, the evaluation of real-world NLP applications often requires multiple dimensions that align with diverse human perspectives. As real human evaluator resources are often scarce and costly, the emerging "LLM-as-a-judge" paradigm sheds light on a promising approach to leverage LLM agents to believably simulate human evaluators. Yet, to date, existing LLM-as-a-judge approaches face two limitations: persona descriptions of agents are often arbitrarily designed, and the frameworks are not generalizable to other tasks. To address these challenges, we propose MAJ-EVAL, a Multi-Agent-as-Judge evaluation framework that can automatically construct multiple evaluator personas with distinct dimensions from relevant text documents (e.g., research papers), instantiate LLM agents with the personas, and engage in-group debates with multi-agents to Generate multi-dimensional feedback. Our evaluation experiments in both the educational and medical domains demonstrate that MAJ-EVAL can generate evaluation results that better align with human experts' ratings compared with conventional automated evaluation metrics and existing LLM-as-a-judge methods.
UXAgent: A System for Simulating Usability Testing of Web Design with LLM Agents
Apr 13, 2025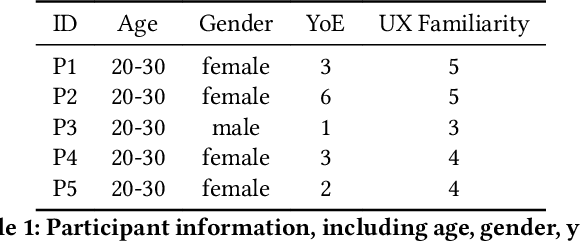
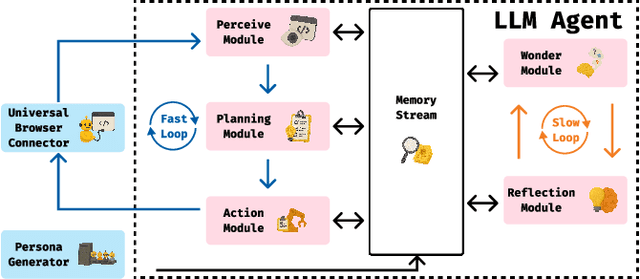
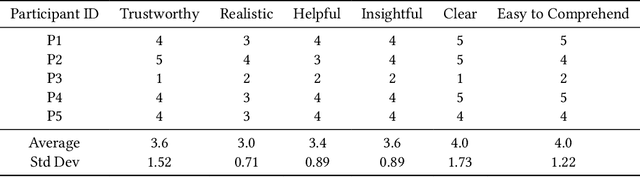
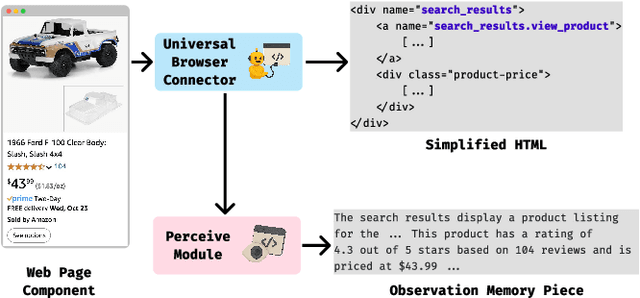
Usability testing is a fundamental research method that user experience (UX) researchers use to evaluate and iterate a web design, but\textbf{ how to evaluate and iterate the usability testing study design } itself? Recent advances in Large Language Model-simulated Agent (\textbf{LLM Agent}) research inspired us to design \textbf{UXAgent} to support UX researchers in evaluating and reiterating their usability testing study design before they conduct the real human-subject study. Our system features a Persona Generator module, an LLM Agent module, and a Universal Browser Connector module to automatically generate thousands of simulated users to interactively test the target website. The system also provides an Agent Interview Interface and a Video Replay Interface so that the UX researchers can easily review and analyze the generated qualitative and quantitative log data. Through a heuristic evaluation, five UX researcher participants praised the innovation of our system but also expressed concerns about the future of LLM Agent usage in UX studies.
AgentA/B: Automated and Scalable Web A/BTesting with Interactive LLM Agents
Apr 13, 2025



A/B testing experiment is a widely adopted method for evaluating UI/UX design decisions in modern web applications. Yet, traditional A/B testing remains constrained by its dependence on the large-scale and live traffic of human participants, and the long time of waiting for the testing result. Through formative interviews with six experienced industry practitioners, we identified critical bottlenecks in current A/B testing workflows. In response, we present AgentA/B, a novel system that leverages Large Language Model-based autonomous agents (LLM Agents) to automatically simulate user interaction behaviors with real webpages. AgentA/B enables scalable deployment of LLM agents with diverse personas, each capable of navigating the dynamic webpage and interactively executing multi-step interactions like search, clicking, filtering, and purchasing. In a demonstrative controlled experiment, we employ AgentA/B to simulate a between-subject A/B testing with 1,000 LLM agents Amazon.com, and compare agent behaviors with real human shopping behaviors at a scale. Our findings suggest AgentA/B can emulate human-like behavior patterns.
UXAgent: An LLM Agent-Based Usability Testing Framework for Web Design
Feb 18, 2025



Usability testing is a fundamental yet challenging (e.g., inflexible to iterate the study design flaws and hard to recruit study participants) research method for user experience (UX) researchers to evaluate a web design. Recent advances in Large Language Model-simulated Agent (LLM-Agent) research inspired us to design UXAgent to support UX researchers in evaluating and reiterating their usability testing study design before they conduct the real human subject study. Our system features an LLM-Agent module and a universal browser connector module so that UX researchers can automatically generate thousands of simulated users to test the target website. The results are shown in qualitative (e.g., interviewing how an agent thinks ), quantitative (e.g., # of actions), and video recording formats for UX researchers to analyze. Through a heuristic user evaluation with five UX researchers, participants praised the innovation of our system but also expressed concerns about the future of LLM Agent-assisted UX study.
Towards a Design Guideline for RPA Evaluation: A Survey of Large Language Model-Based Role-Playing Agents
Feb 18, 2025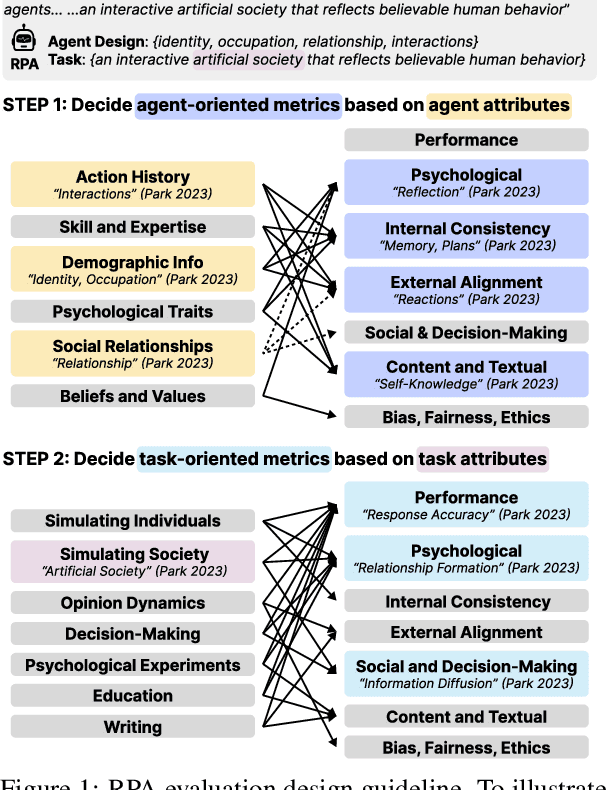
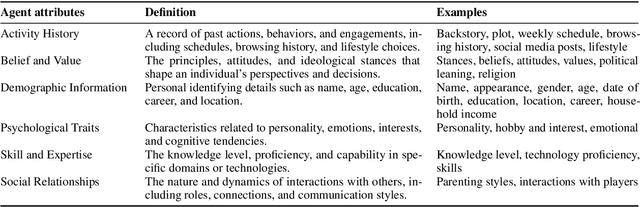
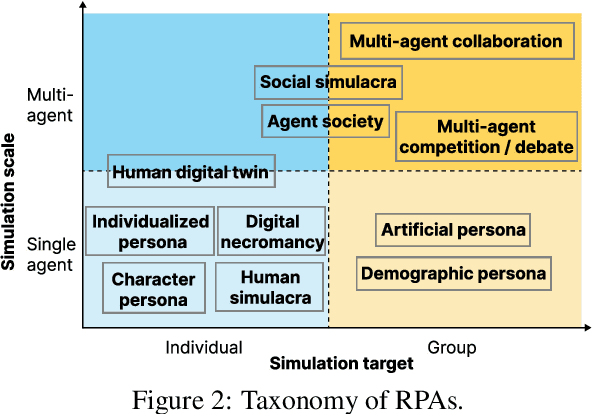

Role-Playing Agent (RPA) is an increasingly popular type of LLM Agent that simulates human-like behaviors in a variety of tasks. However, evaluating RPAs is challenging due to diverse task requirements and agent designs. This paper proposes an evidence-based, actionable, and generalizable evaluation design guideline for LLM-based RPA by systematically reviewing 1,676 papers published between Jan. 2021 and Dec. 2024. Our analysis identifies six agent attributes, seven task attributes, and seven evaluation metrics from existing literature. Based on these findings, we present an RPA evaluation design guideline to help researchers develop more systematic and consistent evaluation methods.
RECOVER: Designing a Large Language Model-based Remote Patient Monitoring System for Postoperative Gastrointestinal Cancer Care
Feb 09, 2025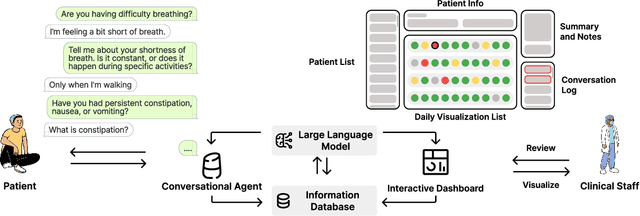

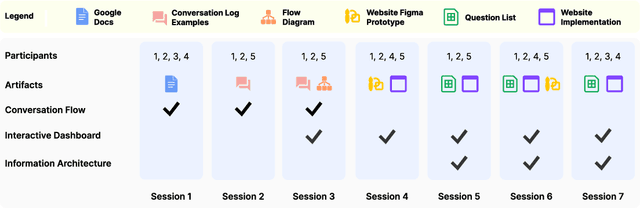
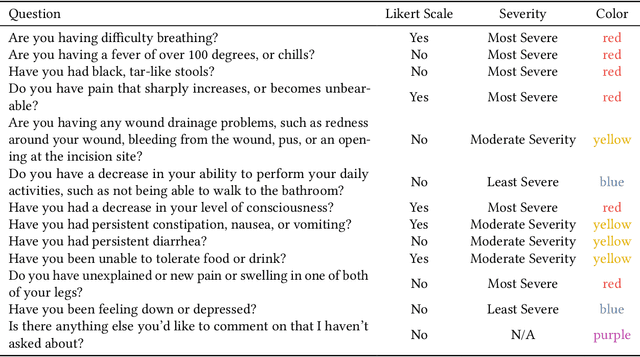
Cancer surgery is a key treatment for gastrointestinal (GI) cancers, a group of cancers that account for more than 35% of cancer-related deaths worldwide, but postoperative complications are unpredictable and can be life-threatening. In this paper, we investigate how recent advancements in large language models (LLMs) can benefit remote patient monitoring (RPM) systems through clinical integration by designing RECOVER, an LLM-powered RPM system for postoperative GI cancer care. To closely engage stakeholders in the design process, we first conducted seven participatory design sessions with five clinical staff and interviewed five cancer patients to derive six major design strategies for integrating clinical guidelines and information needs into LLM-based RPM systems. We then designed and implemented RECOVER, which features an LLM-powered conversational agent for cancer patients and an interactive dashboard for clinical staff to enable efficient postoperative RPM. Finally, we used RECOVER as a pilot system to assess the implementation of our design strategies with four clinical staff and five patients, providing design implications by identifying crucial design elements, offering insights on responsible AI, and outlining opportunities for future LLM-powered RPM systems.
WatchGuardian: Enabling User-Defined Personalized Just-in-Time Intervention on Smartwatch
Feb 09, 2025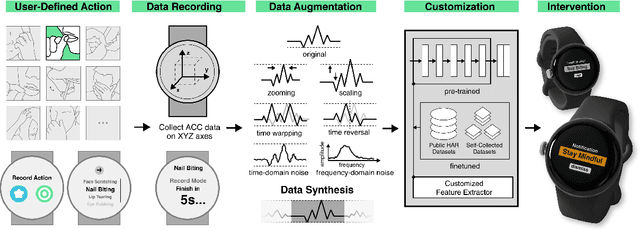
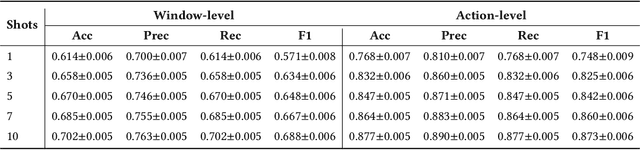
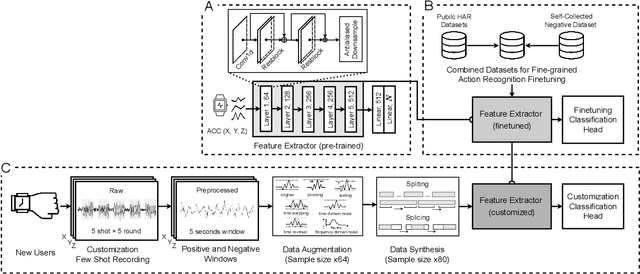
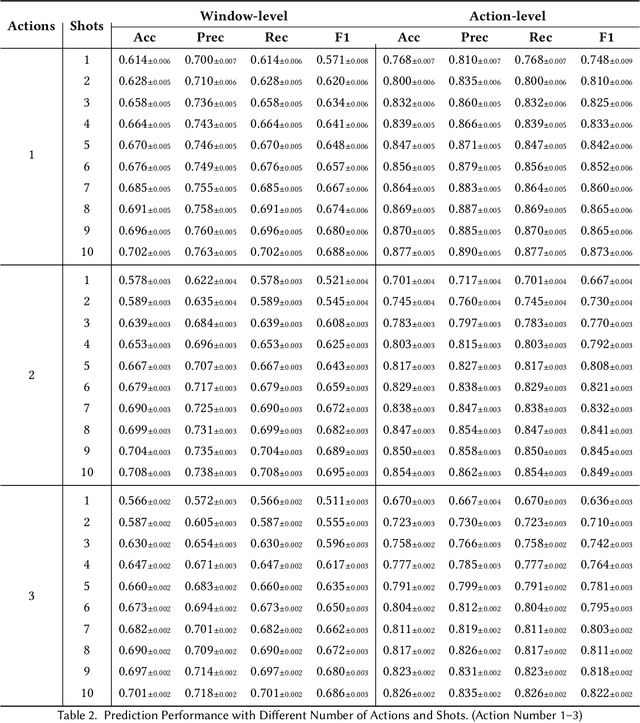
While just-in-time interventions (JITIs) have effectively targeted common health behaviors, individuals often have unique needs to intervene in personal undesirable actions that can negatively affect physical, mental, and social well-being. We present WatchGuardian, a smartwatch-based JITI system that empowers users to define custom interventions for these personal actions with a small number of samples. For the model to detect new actions based on limited new data samples, we developed a few-shot learning pipeline that finetuned a pre-trained inertial measurement unit (IMU) model on public hand-gesture datasets. We then designed a data augmentation and synthesis process to train additional classification layers for customization. Our offline evaluation with 26 participants showed that with three, five, and ten examples, our approach achieved an average accuracy of 76.8%, 84.7%, and 87.7%, and an F1 score of 74.8%, 84.2%, and 87.2% We then conducted a four-hour intervention study to compare WatchGuardian against a rule-based intervention. Our results demonstrated that our system led to a significant reduction by 64.0 +- 22.6% in undesirable actions, substantially outperforming the baseline by 29.0%. Our findings underscore the effectiveness of a customizable, AI-driven JITI system for individuals in need of behavioral intervention in personal undesirable actions. We envision that our work can inspire broader applications of user-defined personalized intervention with advanced AI solutions.