 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWatchGuardian: Enabling User-Defined Personalized Just-in-Time Intervention on Smartwatch
Feb 09, 2025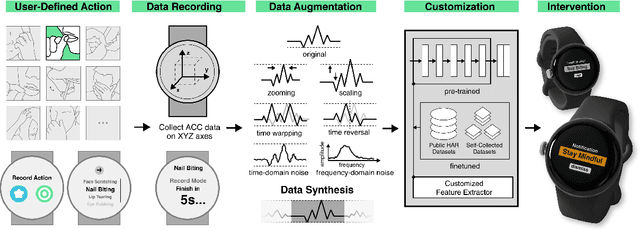
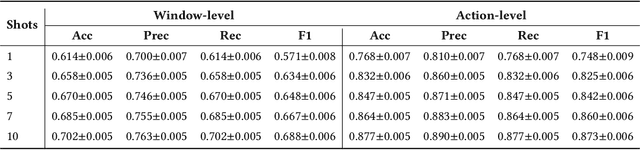
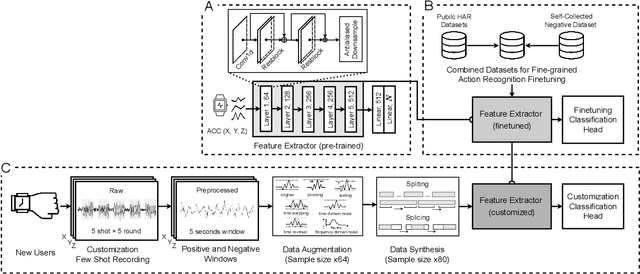
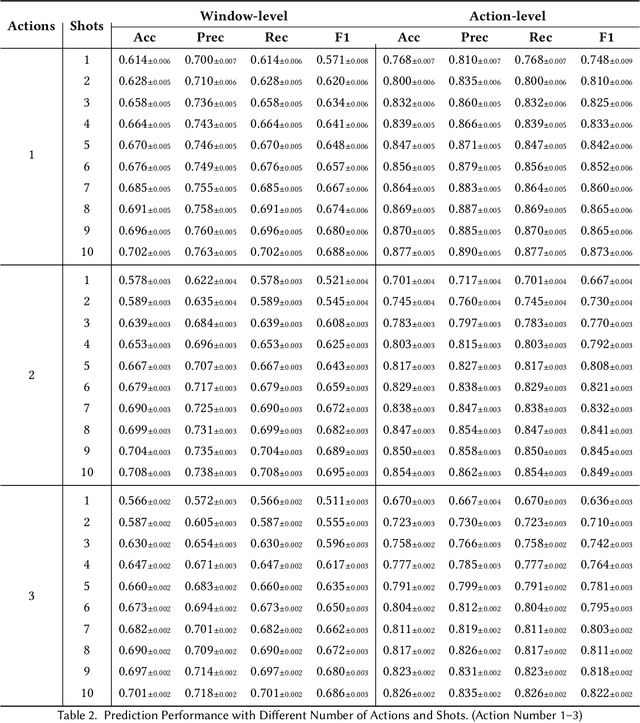
While just-in-time interventions (JITIs) have effectively targeted common health behaviors, individuals often have unique needs to intervene in personal undesirable actions that can negatively affect physical, mental, and social well-being. We present WatchGuardian, a smartwatch-based JITI system that empowers users to define custom interventions for these personal actions with a small number of samples. For the model to detect new actions based on limited new data samples, we developed a few-shot learning pipeline that finetuned a pre-trained inertial measurement unit (IMU) model on public hand-gesture datasets. We then designed a data augmentation and synthesis process to train additional classification layers for customization. Our offline evaluation with 26 participants showed that with three, five, and ten examples, our approach achieved an average accuracy of 76.8%, 84.7%, and 87.7%, and an F1 score of 74.8%, 84.2%, and 87.2% We then conducted a four-hour intervention study to compare WatchGuardian against a rule-based intervention. Our results demonstrated that our system led to a significant reduction by 64.0 +- 22.6% in undesirable actions, substantially outperforming the baseline by 29.0%. Our findings underscore the effectiveness of a customizable, AI-driven JITI system for individuals in need of behavioral intervention in personal undesirable actions. We envision that our work can inspire broader applications of user-defined personalized intervention with advanced AI solutions.
Who Should I Trust: AI or Myself? Leveraging Human and AI Correctness Likelihood to Promote Appropriate Trust in AI-Assisted Decision-Making
Jan 14, 2023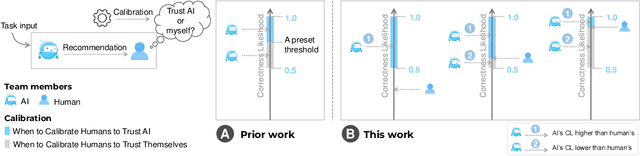
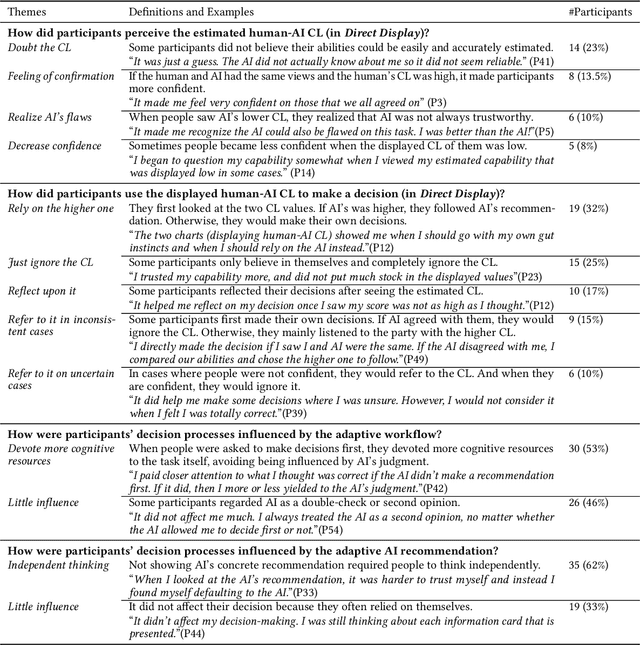
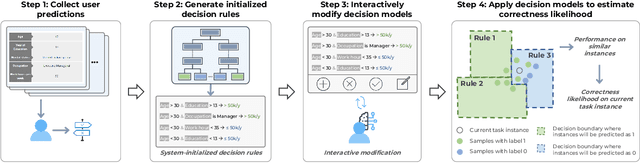
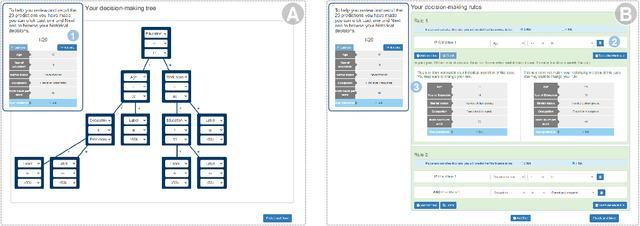
In AI-assisted decision-making, it is critical for human decision-makers to know when to trust AI and when to trust themselves. However, prior studies calibrated human trust only based on AI confidence indicating AI's correctness likelihood (CL) but ignored humans' CL, hindering optimal team decision-making. To mitigate this gap, we proposed to promote humans' appropriate trust based on the CL of both sides at a task-instance level. We first modeled humans' CL by approximating their decision-making models and computing their potential performance in similar instances. We demonstrated the feasibility and effectiveness of our model via two preliminary studies. Then, we proposed three CL exploitation strategies to calibrate users' trust explicitly/implicitly in the AI-assisted decision-making process. Results from a between-subjects experiment (N=293) showed that our CL exploitation strategies promoted more appropriate human trust in AI, compared with only using AI confidence. We further provided practical implications for more human-compatible AI-assisted decision-making.