 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscipLink: Unfolding Interdisciplinary Information Seeking Process via Human-AI Co-Exploration
Aug 01, 2024



Interdisciplinary studies often require researchers to explore literature in diverse branches of knowledge. Yet, navigating through the highly scattered knowledge from unfamiliar disciplines poses a significant challenge. In this paper, we introduce DiscipLink, a novel interactive system that facilitates collaboration between researchers and large language models (LLMs) in interdisciplinary information seeking (IIS). Based on users' topics of interest, DiscipLink initiates exploratory questions from the perspectives of possible relevant fields of study, and users can further tailor these questions. DiscipLink then supports users in searching and screening papers under selected questions by automatically expanding queries with disciplinary-specific terminologies, extracting themes from retrieved papers, and highlighting the connections between papers and questions. Our evaluation, comprising a within-subject comparative experiment and an open-ended exploratory study, reveals that DiscipLink can effectively support researchers in breaking down disciplinary boundaries and integrating scattered knowledge in diverse fields. The findings underscore the potential of LLM-powered tools in fostering information-seeking practices and bolstering interdisciplinary research.
FARPLS: A Feature-Augmented Robot Trajectory Preference Labeling System to Assist Human Labelers' Preference Elicitation
Mar 10, 2024Preference-based learning aims to align robot task objectives with human values. One of the most common methods to infer human preferences is by pairwise comparisons of robot task trajectories. Traditional comparison-based preference labeling systems seldom support labelers to digest and identify critical differences between complex trajectories recorded in videos. Our formative study (N = 12) suggests that individuals may overlook non-salient task features and establish biased preference criteria during their preference elicitation process because of partial observations. In addition, they may experience mental fatigue when given many pairs to compare, causing their label quality to deteriorate. To mitigate these issues, we propose FARPLS, a Feature-Augmented Robot trajectory Preference Labeling System. FARPLS highlights potential outliers in a wide variety of task features that matter to humans and extracts the corresponding video keyframes for easy review and comparison. It also dynamically adjusts the labeling order according to users' familiarities, difficulties of the trajectory pair, and level of disagreements. At the same time, the system monitors labelers' consistency and provides feedback on labeling progress to keep labelers engaged. A between-subjects study (N = 42, 105 pairs of robot pick-and-place trajectories per person) shows that FARPLS can help users establish preference criteria more easily and notice more relevant details in the presented trajectories than the conventional interface. FARPLS also improves labeling consistency and engagement, mitigating challenges in preference elicitation without raising cognitive loads significantly
Competent but Rigid: Identifying the Gap in Empowering AI to Participate Equally in Group Decision-Making
Feb 17, 2023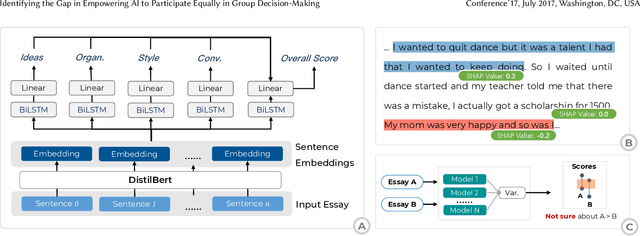

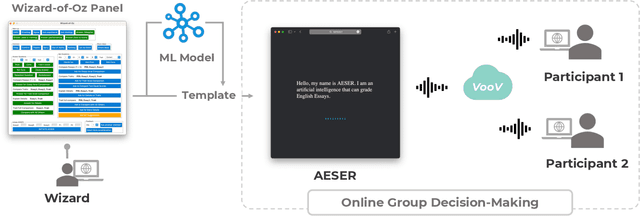

Existing research on human-AI collaborative decision-making focuses mainly on the interaction between AI and individual decision-makers. There is a limited understanding of how AI may perform in group decision-making. This paper presents a wizard-of-oz study in which two participants and an AI form a committee to rank three English essays. One novelty of our study is that we adopt a speculative design by endowing AI equal power to humans in group decision-making.We enable the AI to discuss and vote equally with other human members. We find that although the voice of AI is considered valuable, AI still plays a secondary role in the group because it cannot fully follow the dynamics of the discussion and make progressive contributions. Moreover, the divergent opinions of our participants regarding an "equal AI" shed light on the possible future of human-AI relations.
Who Should I Trust: AI or Myself? Leveraging Human and AI Correctness Likelihood to Promote Appropriate Trust in AI-Assisted Decision-Making
Jan 14, 2023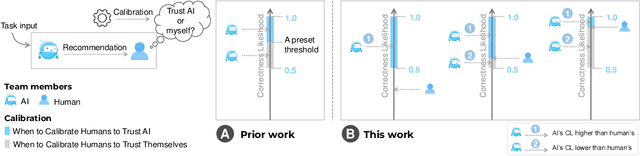
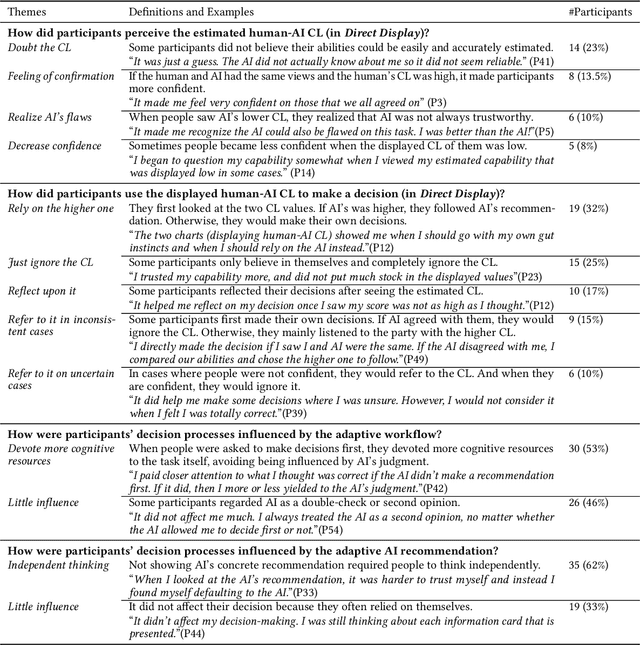
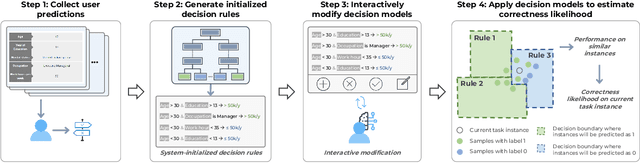
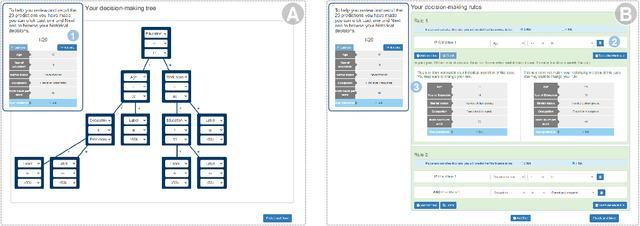
In AI-assisted decision-making, it is critical for human decision-makers to know when to trust AI and when to trust themselves. However, prior studies calibrated human trust only based on AI confidence indicating AI's correctness likelihood (CL) but ignored humans' CL, hindering optimal team decision-making. To mitigate this gap, we proposed to promote humans' appropriate trust based on the CL of both sides at a task-instance level. We first modeled humans' CL by approximating their decision-making models and computing their potential performance in similar instances. We demonstrated the feasibility and effectiveness of our model via two preliminary studies. Then, we proposed three CL exploitation strategies to calibrate users' trust explicitly/implicitly in the AI-assisted decision-making process. Results from a between-subjects experiment (N=293) showed that our CL exploitation strategies promoted more appropriate human trust in AI, compared with only using AI confidence. We further provided practical implications for more human-compatible AI-assisted decision-making.
Branch Ranking for Efficient Mixed-Integer Programming via Offline Ranking-based Policy Learning
Jul 26, 2022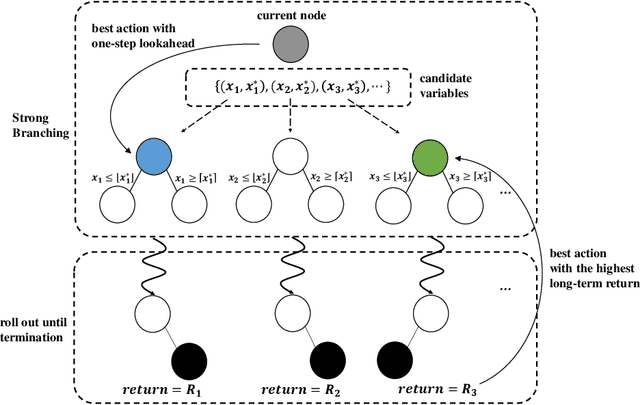
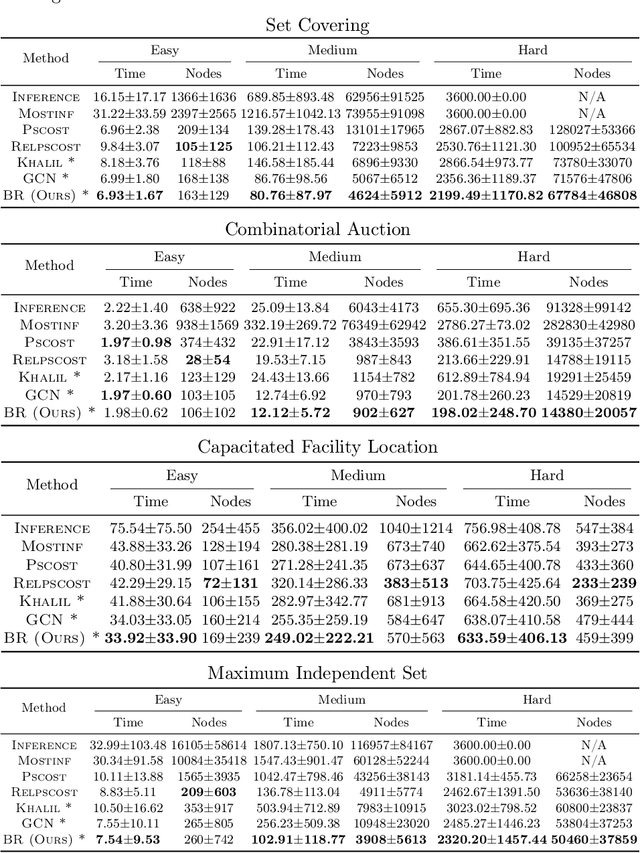
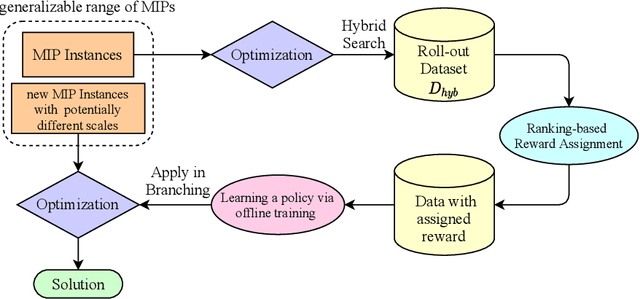

Deriving a good variable selection strategy in branch-and-bound is essential for the efficiency of modern mixed-integer programming (MIP) solvers. With MIP branching data collected during the previous solution process, learning to branch methods have recently become superior over heuristics. As branch-and-bound is naturally a sequential decision making task, one should learn to optimize the utility of the whole MIP solving process instead of being myopic on each step. In this work, we formulate learning to branch as an offline reinforcement learning (RL) problem, and propose a long-sighted hybrid search scheme to construct the offline MIP dataset, which values the long-term utilities of branching decisions. During the policy training phase, we deploy a ranking-based reward assignment scheme to distinguish the promising samples from the long-term or short-term view, and train the branching model named Branch Ranking via offline policy learning. Experiments on synthetic MIP benchmarks and real-world tasks demonstrate that Branch Rankink is more efficient and robust, and can better generalize to large scales of MIP instances compared to the widely used heuristics and state-of-the-art learning-based branching models.