 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBranch Ranking for Efficient Mixed-Integer Programming via Offline Ranking-based Policy Learning
Jul 26, 2022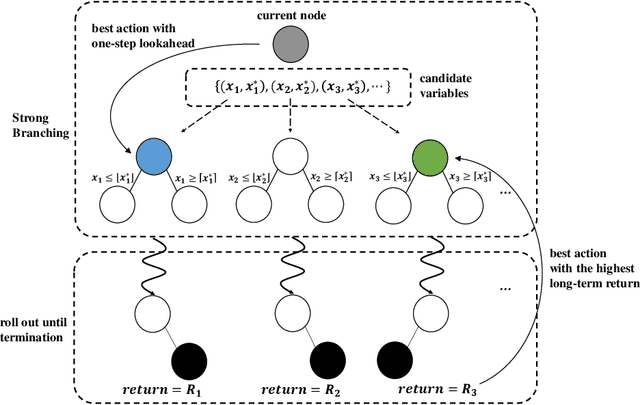
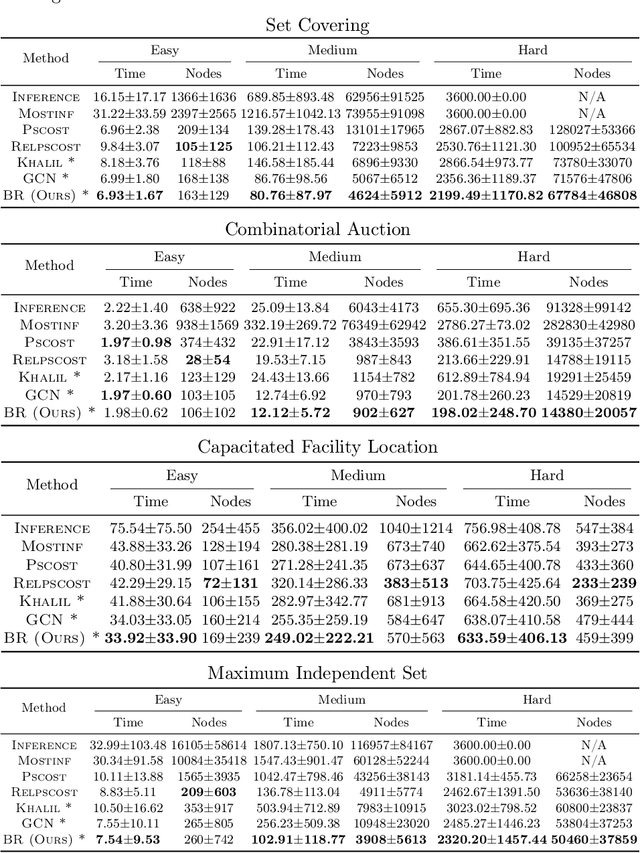
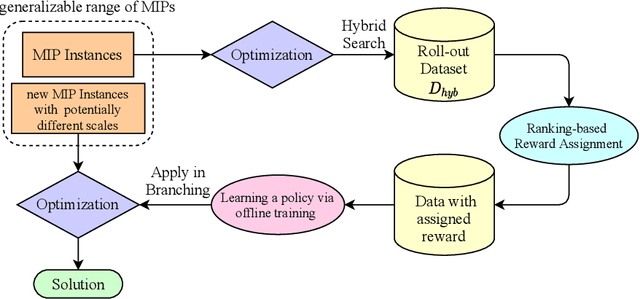

Deriving a good variable selection strategy in branch-and-bound is essential for the efficiency of modern mixed-integer programming (MIP) solvers. With MIP branching data collected during the previous solution process, learning to branch methods have recently become superior over heuristics. As branch-and-bound is naturally a sequential decision making task, one should learn to optimize the utility of the whole MIP solving process instead of being myopic on each step. In this work, we formulate learning to branch as an offline reinforcement learning (RL) problem, and propose a long-sighted hybrid search scheme to construct the offline MIP dataset, which values the long-term utilities of branching decisions. During the policy training phase, we deploy a ranking-based reward assignment scheme to distinguish the promising samples from the long-term or short-term view, and train the branching model named Branch Ranking via offline policy learning. Experiments on synthetic MIP benchmarks and real-world tasks demonstrate that Branch Rankink is more efficient and robust, and can better generalize to large scales of MIP instances compared to the widely used heuristics and state-of-the-art learning-based branching models.
Learning to Select Cuts for Efficient Mixed-Integer Programming
May 28, 2021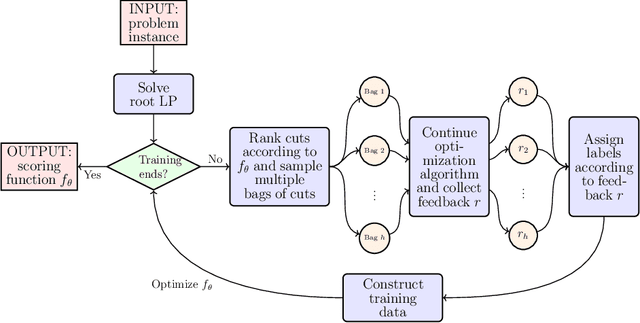
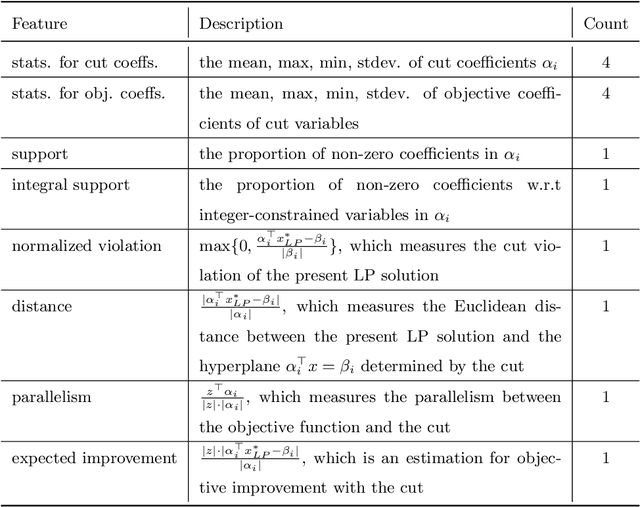

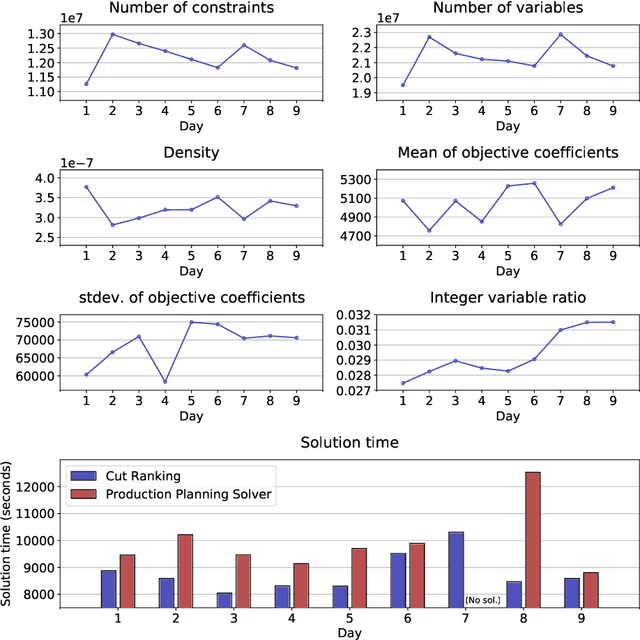
Cutting plane methods play a significant role in modern solvers for tackling mixed-integer programming (MIP) problems. Proper selection of cuts would remove infeasible solutions in the early stage, thus largely reducing the computational burden without hurting the solution accuracy. However, the major cut selection approaches heavily rely on heuristics, which strongly depend on the specific problem at hand and thus limit their generalization capability. In this paper, we propose a data-driven and generalizable cut selection approach, named Cut Ranking, in the settings of multiple instance learning. To measure the quality of the candidate cuts, a scoring function, which takes the instance-specific cut features as inputs, is trained and applied in cut ranking and selection. In order to evaluate our method, we conduct extensive experiments on both synthetic datasets and real-world datasets. Compared with commonly used heuristics for cut selection, the learning-based policy has shown to be more effective, and is capable of generalizing over multiple problems with different properties. Cut Ranking has been deployed in an industrial solver for large-scale MIPs. In the online A/B testing of the product planning problems with more than $10^7$ variables and constraints daily, Cut Ranking has achieved the average speedup ratio of 12.42% over the production solver without any accuracy loss of solution.