 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Ensembled Multiagent Q-Learning with Hypernet Regularizer
Feb 04, 2025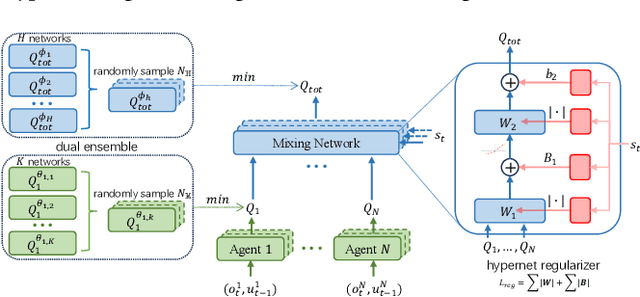
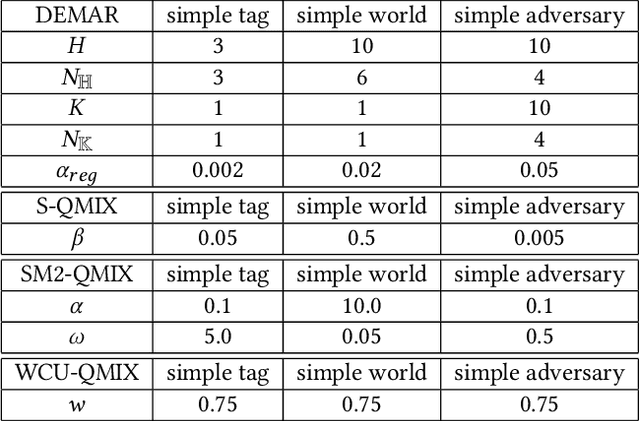
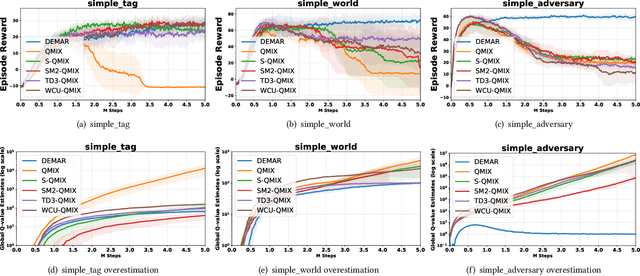
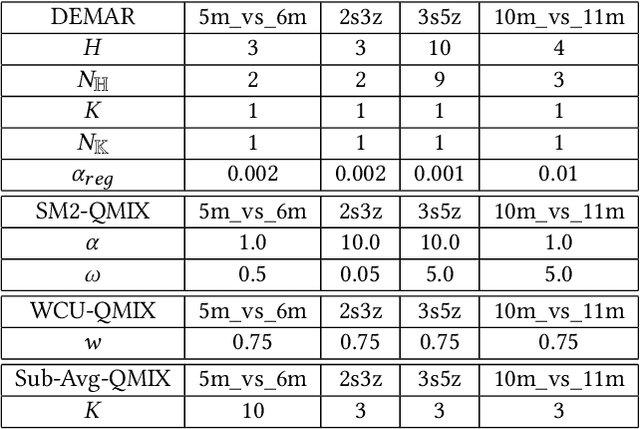
Overestimation in single-agent reinforcement learning has been extensively studied. In contrast, overestimation in the multiagent setting has received comparatively little attention although it increases with the number of agents and leads to severe learning instability. Previous works concentrate on reducing overestimation in the estimation process of target Q-value. They ignore the follow-up optimization process of online Q-network, thus making it hard to fully address the complex multiagent overestimation problem. To solve this challenge, in this study, we first establish an iterative estimation-optimization analysis framework for multiagent value-mixing Q-learning. Our analysis reveals that multiagent overestimation not only comes from the computation of target Q-value but also accumulates in the online Q-network's optimization. Motivated by it, we propose the Dual Ensembled Multiagent Q-Learning with Hypernet Regularizer algorithm to tackle multiagent overestimation from two aspects. First, we extend the random ensemble technique into the estimation of target individual and global Q-values to derive a lower update target. Second, we propose a novel hypernet regularizer on hypernetwork weights and biases to constrain the optimization of online global Q-network to prevent overestimation accumulation. Extensive experiments in MPE and SMAC show that the proposed method successfully addresses overestimation across various tasks.
SFANet: Spatial-Frequency Attention Network for Weather Forecasting
May 29, 2024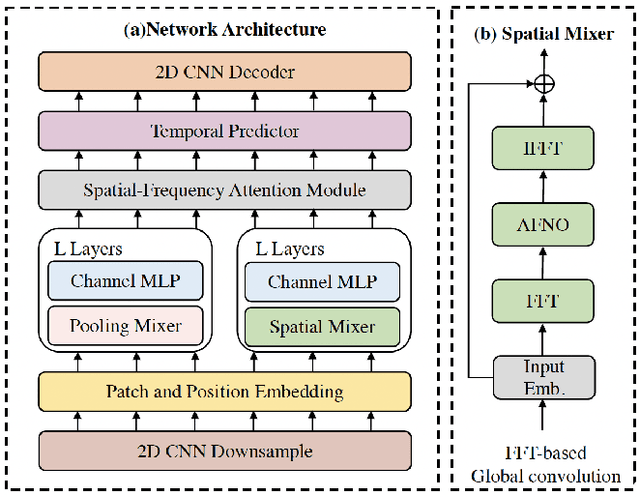

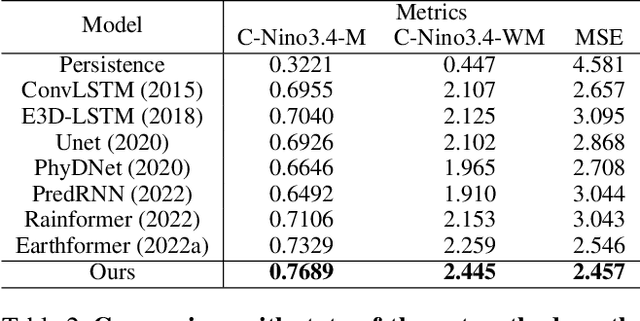
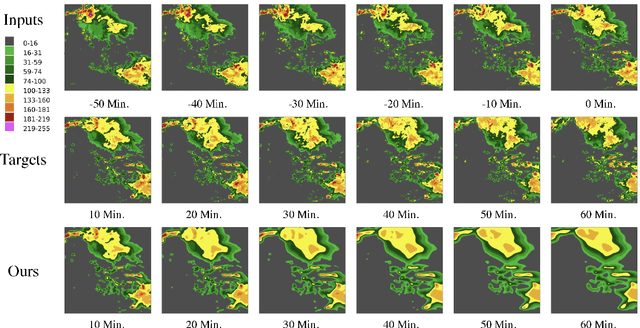
Weather forecasting plays a critical role in various sectors, driving decision-making and risk management. However, traditional methods often struggle to capture the complex dynamics of meteorological systems, particularly in the presence of high-resolution data. In this paper, we propose the Spatial-Frequency Attention Network (SFANet), a novel deep learning framework designed to address these challenges and enhance the accuracy of spatiotemporal weather prediction. Drawing inspiration from the limitations of existing methodologies, we present an innovative approach that seamlessly integrates advanced token mixing and attention mechanisms. By leveraging both pooling and spatial mixing strategies, SFANet optimizes the processing of high-dimensional spatiotemporal sequences, preserving inter-component relational information and modeling extensive long-range relationships. To further enhance feature integration, we introduce a novel spatial-frequency attention module, enabling the model to capture intricate cross-modal correlations. Our extensive experimental evaluation on two distinct datasets, the Storm EVent ImageRy (SEVIR) and the Institute for Climate and Application Research (ICAR) - El Ni\~{n}o Southern Oscillation (ENSO) dataset, demonstrates the remarkable performance of SFANet. Notably, SFANet achieves substantial advancements over state-of-the-art methods, showcasing its proficiency in forecasting precipitation patterns and predicting El Ni\~{n}o events.
Emulating Full Client Participation: A Long-Term Client Selection Strategy for Federated Learning
May 22, 2024



Client selection significantly affects the system convergence efficiency and is a crucial problem in federated learning. Existing methods often select clients by evaluating each round individually and overlook the necessity for long-term optimization, resulting in suboptimal performance and potential fairness issues. In this study, we propose a novel client selection strategy designed to emulate the performance achieved with full client participation. In a single round, we select clients by minimizing the gradient-space estimation error between the client subset and the full client set. In multi-round selection, we introduce a novel individual fairness constraint, which ensures that clients with similar data distributions have similar frequencies of being selected. This constraint guides the client selection process from a long-term perspective. We employ Lyapunov optimization and submodular functions to efficiently identify the optimal subset of clients, and provide a theoretical analysis of the convergence ability. Experiments demonstrate that the proposed strategy significantly improves both accuracy and fairness compared to previous methods while also exhibiting efficiency by incurring minimal time overhead.
Where and How to Attack? A Causality-Inspired Recipe for Generating Counterfactual Adversarial Examples
Dec 21, 2023Deep neural networks (DNNs) have been demonstrated to be vulnerable to well-crafted \emph{adversarial examples}, which are generated through either well-conceived $\mathcal{L}_p$-norm restricted or unrestricted attacks. Nevertheless, the majority of those approaches assume that adversaries can modify any features as they wish, and neglect the causal generating process of the data, which is unreasonable and unpractical. For instance, a modification in income would inevitably impact features like the debt-to-income ratio within a banking system. By considering the underappreciated causal generating process, first, we pinpoint the source of the vulnerability of DNNs via the lens of causality, then give theoretical results to answer \emph{where to attack}. Second, considering the consequences of the attack interventions on the current state of the examples to generate more realistic adversarial examples, we propose CADE, a framework that can generate \textbf{C}ounterfactual \textbf{AD}versarial \textbf{E}xamples to answer \emph{how to attack}. The empirical results demonstrate CADE's effectiveness, as evidenced by its competitive performance across diverse attack scenarios, including white-box, transfer-based, and random intervention attacks.
Specify Robust Causal Representation from Mixed Observations
Oct 21, 2023
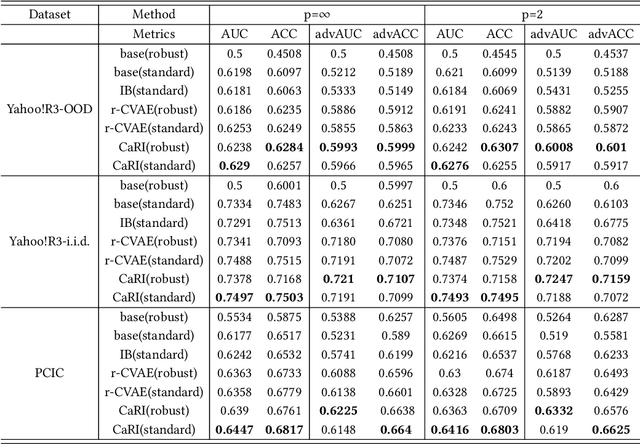
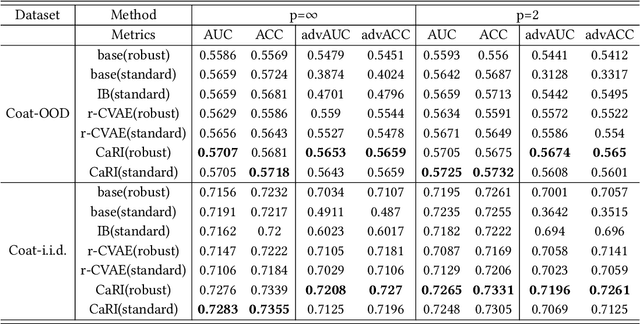

Learning representations purely from observations concerns the problem of learning a low-dimensional, compact representation which is beneficial to prediction models. Under the hypothesis that the intrinsic latent factors follow some casual generative models, we argue that by learning a causal representation, which is the minimal sufficient causes of the whole system, we can improve the robustness and generalization performance of machine learning models. In this paper, we develop a learning method to learn such representation from observational data by regularizing the learning procedure with mutual information measures, according to the hypothetical factored causal graph. We theoretically and empirically show that the models trained with the learned causal representations are more robust under adversarial attacks and distribution shifts compared with baselines. The supplementary materials are available at https://github.com/ymy $4323460 / \mathrm{CaRI} /$.
CauDR: A Causality-inspired Domain Generalization Framework for Fundus-based Diabetic Retinopathy Grading
Sep 27, 2023Diabetic retinopathy (DR) is the most common diabetic complication, which usually leads to retinal damage, vision loss, and even blindness. A computer-aided DR grading system has a significant impact on helping ophthalmologists with rapid screening and diagnosis. Recent advances in fundus photography have precipitated the development of novel retinal imaging cameras and their subsequent implementation in clinical practice. However, most deep learning-based algorithms for DR grading demonstrate limited generalization across domains. This inferior performance stems from variance in imaging protocols and devices inducing domain shifts. We posit that declining model performance between domains arises from learning spurious correlations in the data. Incorporating do-operations from causality analysis into model architectures may mitigate this issue and improve generalizability. Specifically, a novel universal structural causal model (SCM) was proposed to analyze spurious correlations in fundus imaging. Building on this, a causality-inspired diabetic retinopathy grading framework named CauDR was developed to eliminate spurious correlations and achieve more generalizable DR diagnostics. Furthermore, existing datasets were reorganized into 4DR benchmark for DG scenario. Results demonstrate the effectiveness and the state-of-the-art (SOTA) performance of CauDR.
Invariant Learning via Probability of Sufficient and Necessary Causes
Sep 22, 2023Out-of-distribution (OOD) generalization is indispensable for learning models in the wild, where testing distribution typically unknown and different from the training. Recent methods derived from causality have shown great potential in achieving OOD generalization. However, existing methods mainly focus on the invariance property of causes, while largely overlooking the property of \textit{sufficiency} and \textit{necessity} conditions. Namely, a necessary but insufficient cause (feature) is invariant to distribution shift, yet it may not have required accuracy. By contrast, a sufficient yet unnecessary cause (feature) tends to fit specific data well but may have a risk of adapting to a new domain. To capture the information of sufficient and necessary causes, we employ a classical concept, the probability of sufficiency and necessary causes (PNS), which indicates the probability of whether one is the necessary and sufficient cause. To associate PNS with OOD generalization, we propose PNS risk and formulate an algorithm to learn representation with a high PNS value. We theoretically analyze and prove the generalizability of the PNS risk. Experiments on both synthetic and real-world benchmarks demonstrate the effectiveness of the proposed method. The details of the implementation can be found at the GitHub repository: https://github.com/ymy4323460/CaSN.
Meta Adaptive Task Sampling for Few-Domain Generalization
May 25, 2023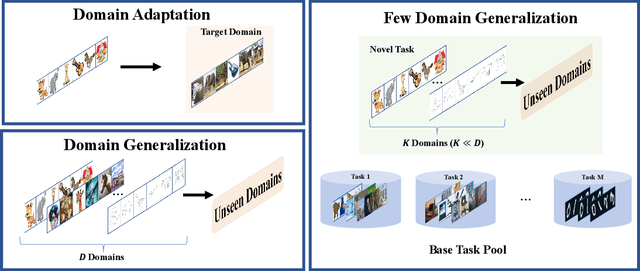


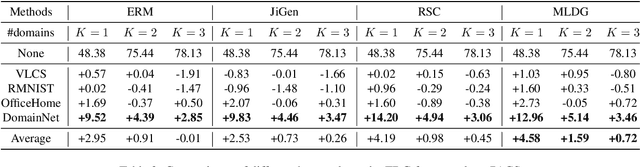
To ensure the out-of-distribution (OOD) generalization performance, traditional domain generalization (DG) methods resort to training on data from multiple sources with different underlying distributions. And the success of those DG methods largely depends on the fact that there are diverse training distributions. However, it usually needs great efforts to obtain enough heterogeneous data due to the high expenses, privacy issues or the scarcity of data. Thus an interesting yet seldom investigated problem arises: how to improve the OOD generalization performance when the perceived heterogeneity is limited. In this paper, we instantiate a new framework called few-domain generalization (FDG), which aims to learn a generalizable model from very few domains of novel tasks with the knowledge acquired from previous learning experiences on base tasks. Moreover, we propose a Meta Adaptive Task Sampling (MATS) procedure to differentiate base tasks according to their semantic and domain-shift similarity to the novel task. Empirically, we show that the newly introduced FDG framework can substantially improve the OOD generalization performance on the novel task and further combining MATS with episodic training could outperform several state-of-the-art DG baselines on widely used benchmarks like PACS and DomainNet.
Adaptive Negative Evidential Deep Learning for Open-set Semi-supervised Learning
Mar 21, 2023



Semi-supervised learning (SSL) methods assume that labeled data, unlabeled data and test data are from the same distribution. Open-set semi-supervised learning (Open-set SSL) considers a more practical scenario, where unlabeled data and test data contain new categories (outliers) not observed in labeled data (inliers). Most previous works focused on outlier detection via binary classifiers, which suffer from insufficient scalability and inability to distinguish different types of uncertainty. In this paper, we propose a novel framework, Adaptive Negative Evidential Deep Learning (ANEDL) to tackle these limitations. Concretely, we first introduce evidential deep learning (EDL) as an outlier detector to quantify different types of uncertainty, and design different uncertainty metrics for self-training and inference. Furthermore, we propose a novel adaptive negative optimization strategy, making EDL more tailored to the unlabeled dataset containing both inliers and outliers. As demonstrated empirically, our proposed method outperforms existing state-of-the-art methods across four datasets.
Uncertainty Estimation by Fisher Information-based Evidential Deep Learning
Mar 13, 2023



Uncertainty estimation is a key factor that makes deep learning reliable in practical applications. Recently proposed evidential neural networks explicitly account for different uncertainties by treating the network's outputs as evidence to parameterize the Dirichlet distribution, and achieve impressive performance in uncertainty estimation. However, for high data uncertainty samples but annotated with the one-hot label, the evidence-learning process for those mislabeled classes is over-penalized and remains hindered. To address this problem, we propose a novel method, Fisher Information-based Evidential Deep Learning ($\mathcal{I}$-EDL). In particular, we introduce Fisher Information Matrix (FIM) to measure the informativeness of evidence carried by each sample, according to which we can dynamically reweight the objective loss terms to make the network more focused on the representation learning of uncertain classes. The generalization ability of our network is further improved by optimizing the PAC-Bayesian bound. As demonstrated empirically, our proposed method consistently outperforms traditional EDL-related algorithms in multiple uncertainty estimation tasks, especially in the more challenging few-shot classification settings.