 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEventVGGT: Exploring Cross-Modal Distillation for Consistent Event-based Depth Estimation
Mar 10, 2026Event cameras offer superior sensitivity to high-speed motion and extreme lighting, making event-based monocular depth estimation a promising approach for robust 3D perception in challenging conditions. However, progress is severely hindered by the scarcity of dense depth annotations. While recent annotation-free approaches mitigate this by distilling knowledge from Vision Foundation Models (VFMs), a critical limitation persists: they process event streams as independent frames. By neglecting the inherent temporal continuity of event data, these methods fail to leverage the rich temporal priors encoded in VFMs, ultimately yielding temporally inconsistent and less accurate depth predictions. To address this, we introduce EventVGGT, a novel framework that explicitly models the event stream as a coherent video sequence. To the best of our knowledge, we are the first to distill spatio-temporal and multi-view geometric priors from the Visual Geometry Grounded Transformer (VGGT) into the event domain. We achieve this via a comprehensive tri-level distillation strategy: (i) Cross-Modal Feature Mixture (CMFM) bridges the modality gap at the output level by fusing RGB and event features to generate auxiliary depth predictions; (ii) Spatio-Temporal Feature Distillation (STFD) distills VGGT's powerful spatio-temporal representations at the feature level; and (iii) Temporal Consistency Distillation (TCD) enforces cross-frame coherence at the temporal level by aligning inter-frame depth changes. Extensive experiments demonstrate that EventVGGT consistently outperforms existing methods -- reducing the absolute mean depth error at 30m by over 53\% on EventScape (from 2.30 to 1.06) -- while exhibiting robust zero-shot generalization on the unseen DENSE and MVSEC datasets.
Native Intelligence Emerges from Large-Scale Clinical Practice: A Retinal Foundation Model with Deployment Efficiency
Dec 16, 2025Current retinal foundation models remain constrained by curated research datasets that lack authentic clinical context, and require extensive task-specific optimization for each application, limiting their deployment efficiency in low-resource settings. Here, we show that these barriers can be overcome by building clinical native intelligence directly from real-world medical practice. Our key insight is that large-scale telemedicine programs, where expert centers provide remote consultations across distributed facilities, represent a natural reservoir for learning clinical image interpretation. We present ReVision, a retinal foundation model that learns from the natural alignment between 485,980 color fundus photographs and their corresponding diagnostic reports, accumulated through a decade-long telemedicine program spanning 162 medical institutions across China. Through extensive evaluation across 27 ophthalmic benchmarks, we demonstrate that ReVison enables deployment efficiency with minimal local resources. Without any task-specific training, ReVision achieves zero-shot disease detection with an average AUROC of 0.946 across 12 public benchmarks and 0.952 on 3 independent clinical cohorts. When minimal adaptation is feasible, ReVision matches extensively fine-tuned alternatives while requiring orders of magnitude fewer trainable parameters and labeled examples. The learned representations also transfer effectively to new clinical sites, imaging domains, imaging modalities, and systemic health prediction tasks. In a prospective reader study with 33 ophthalmologists, ReVision's zero-shot assistance improved diagnostic accuracy by 14.8% across all experience levels. These results demonstrate that clinical native intelligence can be directly extracted from clinical archives without any further annotation to build medical AI systems suited to various low-resource settings.
VisionCLIP: An Med-AIGC based Ethical Language-Image Foundation Model for Generalizable Retina Image Analysis
Mar 16, 2024Generalist foundation model has ushered in newfound capabilities in medical domain. However, the contradiction between the growing demand for high-quality annotated data with patient privacy continues to intensify. The utilization of medical artificial intelligence generated content (Med-AIGC) as an inexhaustible resource repository arises as a potential solution to address the aforementioned challenge. Here we harness 1 million open-source synthetic fundus images paired with natural language descriptions, to curate an ethical language-image foundation model for retina image analysis named VisionCLIP. VisionCLIP achieves competitive performance on three external datasets compared with the existing method pre-trained on real-world data in a zero-shot fashion. The employment of artificially synthetic images alongside corresponding textual data for training enables the medical foundation model to successfully assimilate knowledge of disease symptomatology, thereby circumventing potential breaches of patient confidentiality.
Leveraging Multimodal Fusion for Enhanced Diagnosis of Multiple Retinal Diseases in Ultra-wide OCTA
Nov 17, 2023



Ultra-wide optical coherence tomography angiography (UW-OCTA) is an emerging imaging technique that offers significant advantages over traditional OCTA by providing an exceptionally wide scanning range of up to 24 x 20 $mm^{2}$, covering both the anterior and posterior regions of the retina. However, the currently accessible UW-OCTA datasets suffer from limited comprehensive hierarchical information and corresponding disease annotations. To address this limitation, we have curated the pioneering M3OCTA dataset, which is the first multimodal (i.e., multilayer), multi-disease, and widest field-of-view UW-OCTA dataset. Furthermore, the effective utilization of multi-layer ultra-wide ocular vasculature information from UW-OCTA remains underdeveloped. To tackle this challenge, we propose the first cross-modal fusion framework that leverages multi-modal information for diagnosing multiple diseases. Through extensive experiments conducted on our openly available M3OCTA dataset, we demonstrate the effectiveness and superior performance of our method, both in fixed and varying modalities settings. The construction of the M3OCTA dataset, the first multimodal OCTA dataset encompassing multiple diseases, aims to advance research in the ophthalmic image analysis community.
VisionFM: a Multi-Modal Multi-Task Vision Foundation Model for Generalist Ophthalmic Artificial Intelligence
Oct 08, 2023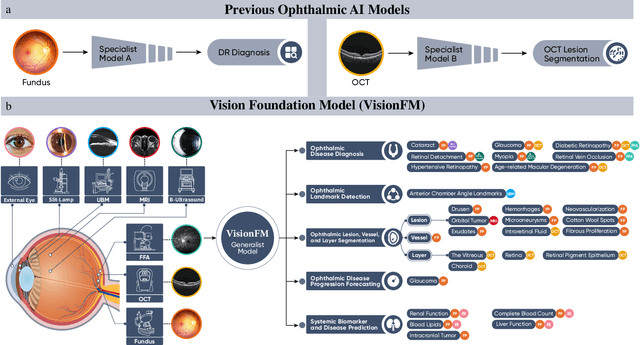
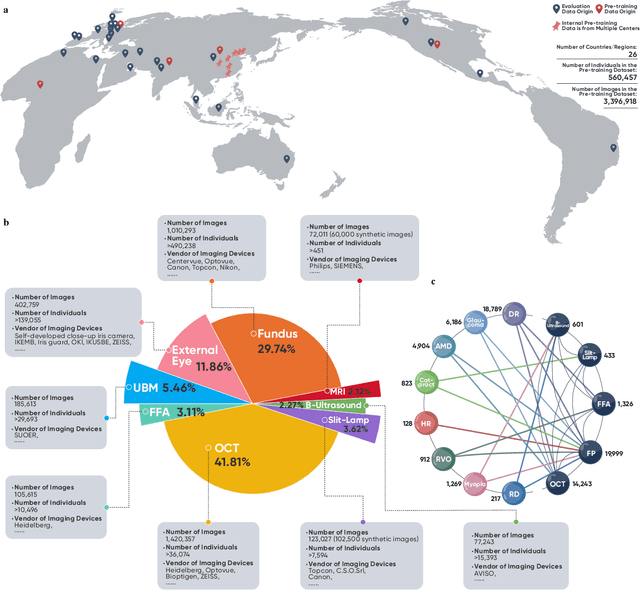

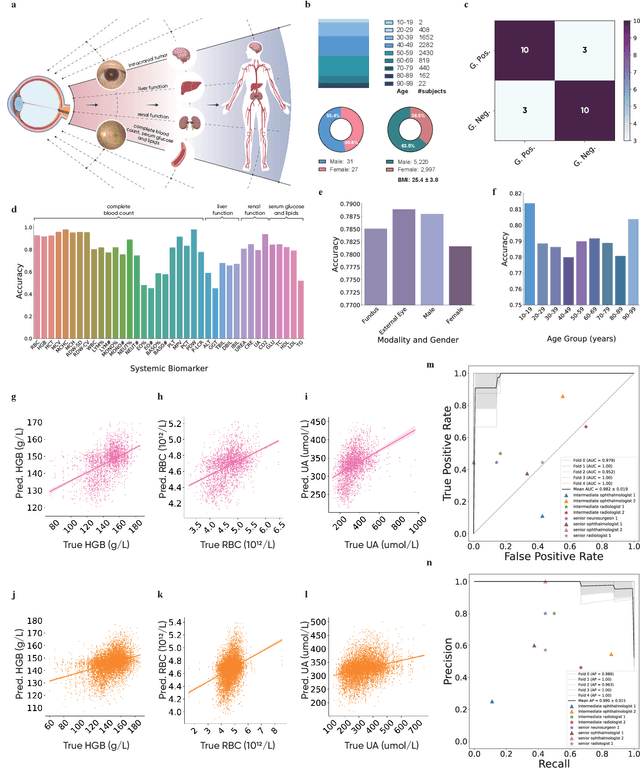
We present VisionFM, a foundation model pre-trained with 3.4 million ophthalmic images from 560,457 individuals, covering a broad range of ophthalmic diseases, modalities, imaging devices, and demography. After pre-training, VisionFM provides a foundation to foster multiple ophthalmic artificial intelligence (AI) applications, such as disease screening and diagnosis, disease prognosis, subclassification of disease phenotype, and systemic biomarker and disease prediction, with each application enhanced with expert-level intelligence and accuracy. The generalist intelligence of VisionFM outperformed ophthalmologists with basic and intermediate levels in jointly diagnosing 12 common ophthalmic diseases. Evaluated on a new large-scale ophthalmic disease diagnosis benchmark database, as well as a new large-scale segmentation and detection benchmark database, VisionFM outperformed strong baseline deep neural networks. The ophthalmic image representations learned by VisionFM exhibited noteworthy explainability, and demonstrated strong generalizability to new ophthalmic modalities, disease spectrum, and imaging devices. As a foundation model, VisionFM has a large capacity to learn from diverse ophthalmic imaging data and disparate datasets. To be commensurate with this capacity, in addition to the real data used for pre-training, we also generated and leveraged synthetic ophthalmic imaging data. Experimental results revealed that synthetic data that passed visual Turing tests, can also enhance the representation learning capability of VisionFM, leading to substantial performance gains on downstream ophthalmic AI tasks. Beyond the ophthalmic AI applications developed, validated, and demonstrated in this work, substantial further applications can be achieved in an efficient and cost-effective manner using VisionFM as the foundation.
CauDR: A Causality-inspired Domain Generalization Framework for Fundus-based Diabetic Retinopathy Grading
Sep 27, 2023Diabetic retinopathy (DR) is the most common diabetic complication, which usually leads to retinal damage, vision loss, and even blindness. A computer-aided DR grading system has a significant impact on helping ophthalmologists with rapid screening and diagnosis. Recent advances in fundus photography have precipitated the development of novel retinal imaging cameras and their subsequent implementation in clinical practice. However, most deep learning-based algorithms for DR grading demonstrate limited generalization across domains. This inferior performance stems from variance in imaging protocols and devices inducing domain shifts. We posit that declining model performance between domains arises from learning spurious correlations in the data. Incorporating do-operations from causality analysis into model architectures may mitigate this issue and improve generalizability. Specifically, a novel universal structural causal model (SCM) was proposed to analyze spurious correlations in fundus imaging. Building on this, a causality-inspired diabetic retinopathy grading framework named CauDR was developed to eliminate spurious correlations and achieve more generalizable DR diagnostics. Furthermore, existing datasets were reorganized into 4DR benchmark for DG scenario. Results demonstrate the effectiveness and the state-of-the-art (SOTA) performance of CauDR.
Generalist Vision Foundation Models for Medical Imaging: A Case Study of Segment Anything Model on Zero-Shot Medical Segmentation
Apr 25, 2023
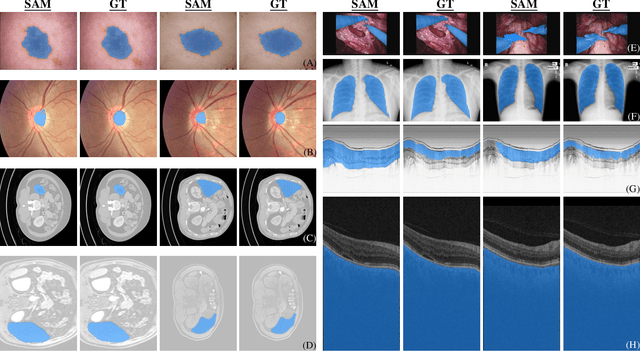
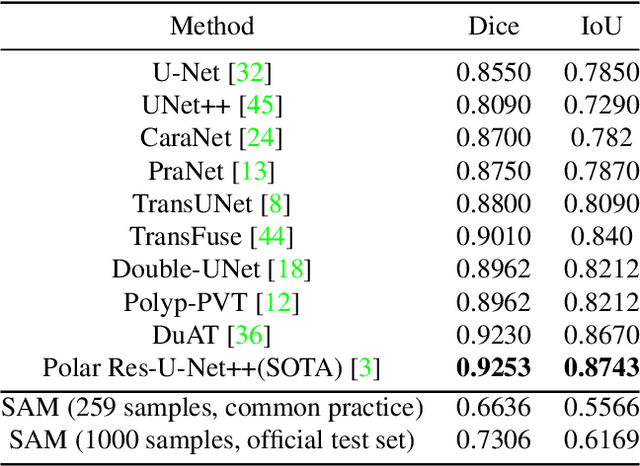
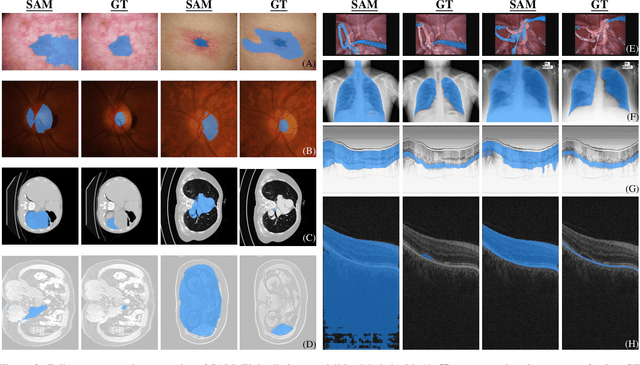
We examine the recent Segment Anything Model (SAM) on medical images, and report both quantitative and qualitative zero-shot segmentation results on nine medical image segmentation benchmarks, covering various imaging modalities, such as optical coherence tomography (OCT), magnetic resonance imaging (MRI), and computed tomography (CT), as well as different applications including dermatology, ophthalmology, and radiology. Our experiments reveal that while SAM demonstrates stunning segmentation performance on images from the general domain, for those out-of-distribution images, e.g., medical images, its zero-shot segmentation performance is still limited. Furthermore, SAM demonstrated varying zero-shot segmentation performance across different unseen medical domains. For example, it had a 0.8704 mean Dice score on segmenting under-bruch's membrane layer of retinal OCT, whereas the segmentation accuracy drops to 0.0688 when segmenting retinal pigment epithelium. For certain structured targets, e.g., blood vessels, the zero-shot segmentation of SAM completely failed, whereas a simple fine-tuning of it with small amount of data could lead to remarkable improvements of the segmentation quality. Our study indicates the versatility of generalist vision foundation models on solving specific tasks in medical imaging, and their great potential to achieve desired performance through fine-turning and eventually tackle the challenges of accessing large diverse medical datasets and the complexity of medical domains.
Large AI Models in Health Informatics: Applications, Challenges, and the Future
Mar 21, 2023



Large AI models, or foundation models, are models recently emerging with massive scales both parameter-wise and data-wise, the magnitudes of which often reach beyond billions. Once pretrained, large AI models demonstrate impressive performance in various downstream tasks. A concrete example is the recent debut of ChatGPT, whose capability has compelled people's imagination about the far-reaching influence that large AI models can have and their potential to transform different domains of our life. In health informatics, the advent of large AI models has brought new paradigms for the design of methodologies. The scale of multimodality data in the biomedical and health domain has been ever-expanding especially since the community embraced the era of deep learning, which provides the ground to develop, validate, and advance large AI models for breakthroughs in health-related areas. This article presents an up-to-date comprehensive review of large AI models, from background to their applications. We identify seven key sectors that large AI models are applicable and might have substantial influence, including 1) molecular biology and drug discovery; 2) medical diagnosis and decision-making; 3) medical imaging and vision; 4) medical informatics; 5) medical education; 6) public health; and 7) medical robotics. We examine their challenges in health informatics, followed by a critical discussion about potential future directions and pitfalls of large AI models in transforming the field of health informatics.
EVEN: An Event-Based Framework for Monocular Depth Estimation at Adverse Night Conditions
Feb 08, 2023



Accurate depth estimation under adverse night conditions has practical impact and applications, such as on autonomous driving and rescue robots. In this work, we studied monocular depth estimation at night time in which various adverse weather, light, and different road conditions exist, with data captured in both RGB and event modalities. Event camera can better capture intensity changes by virtue of its high dynamic range (HDR), which is particularly suitable to be applied at adverse night conditions in which the amount of light is limited in the scene. Although event data can retain visual perception that conventional RGB camera may fail to capture, the lack of texture and color information of event data hinders its applicability to accurately estimate depth alone. To tackle this problem, we propose an event-vision based framework that integrates low-light enhancement for the RGB source, and exploits the complementary merits of RGB and event data. A dataset that includes paired RGB and event streams, and ground truth depth maps has been constructed. Comprehensive experiments have been conducted, and the impact of different adverse weather combinations on the performance of framework has also been investigated. The results have shown that our proposed framework can better estimate monocular depth at adverse nights than six baselines.
MenuAI: Restaurant Food Recommendation System via a Transformer-based Deep Learning Model
Oct 15, 2022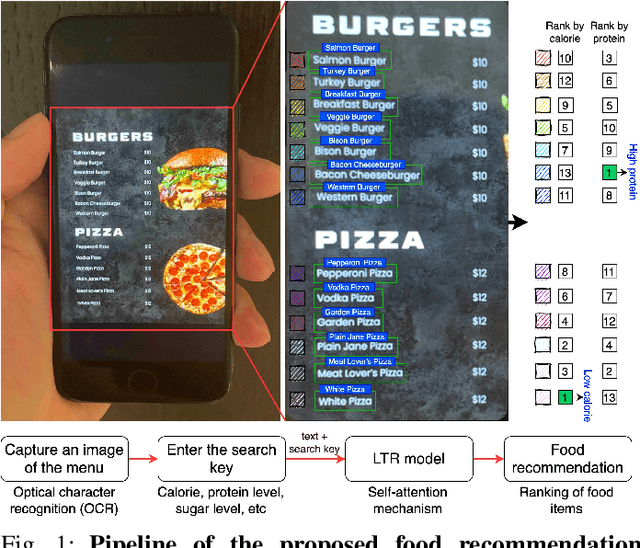
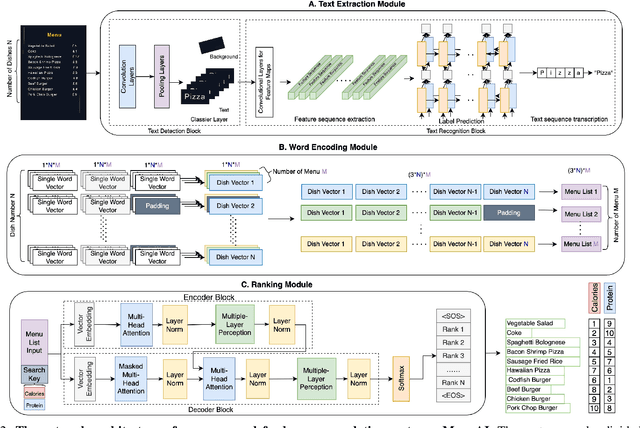
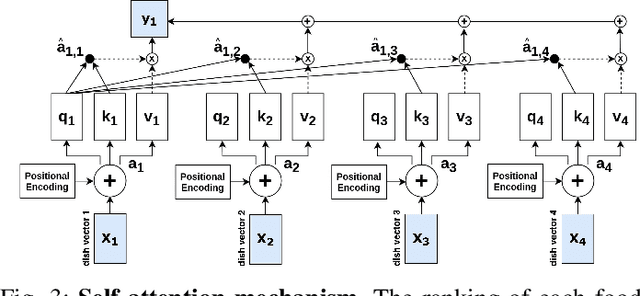
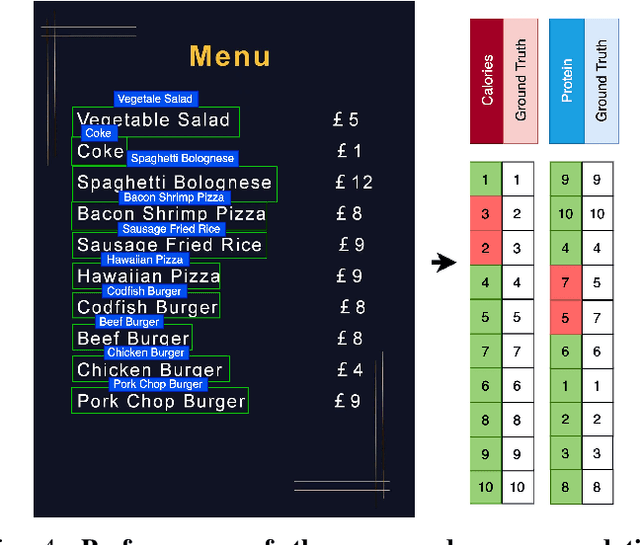
Food recommendation system has proven as an effective technology to provide guidance on dietary choices, and this is especially important for patients suffering from chronic diseases. Unlike other multimedia recommendations, such as books and movies, food recommendation task is highly relied on the context at the moment, since users' food preference can be highly dynamic over time. For example, individuals tend to eat more calories earlier in the day and eat a little less at dinner. However, there are still limited research works trying to incorporate both current context and nutritional knowledge for food recommendation. Thus, a novel restaurant food recommendation system is proposed in this paper to recommend food dishes to users according to their special nutritional needs. Our proposed system utilises Optical Character Recognition (OCR) technology and a transformer-based deep learning model, Learning to Rank (LTR) model, to conduct food recommendation. Given a single RGB image of the menu, the system is then able to rank the food dishes in terms of the input search key (e.g., calorie, protein level). Due to the property of the transformer, our system can also rank unseen food dishes. Comprehensive experiments are conducted to validate our methods on a self-constructed menu dataset, known as MenuRank dataset. The promising results, with accuracy ranging from 77.2% to 99.5%, have demonstrated the great potential of LTR model in addressing food recommendation problems.