 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe 1st PortraitCraft Challenge: A CVPR 2026 Workshop Competition on Portrait Composition Understanding and Generation
Jun 09, 2026This paper presents an overview of the inaugural PortraitCraft Challenge, held as one of the official competitions at CVPR 2026. The challenge focuses on portrait composition understanding and generation, aiming to advance AI research in portrait aesthetics analysis and controllable image synthesis. Unlike existing datasets and tasks that primarily focus on global aesthetic scoring, PortraitCraft introduces a unified evaluation framework comprising two complementary tracks. Track 1 requires models to perform structured portrait composition understanding, and Track 2 requires models to generate portrait images from structured composition descriptions under explicit compositional constraints. To support the challenge, we constructed and publicly released a large-scale portrait composition dataset consisting of approximately 50,000 curated real portrait images, providing multi-level supervision. This report describes the challenge setup, evaluation protocols, dataset composition, and final results, along with an analysis of the technical characteristics of the submitted solutions. The PortraitCraft Challenge provides a standardized and reproducible platform for research on portrait composition understanding and generation, and is expected to foster further progress in the fields of portrait aesthetics and controllable image generation.
UniSHARP: Universal Sharp Monocular View Synthesis
Jun 05, 2026In this work, we focus on extending SHARP, the popular photorealistic view synthesis method, for universal monocular rendering across a continuum of camera systems, from conventional perspective cameras to wide-field-of-view, fisheye and omnidirectional panoramic settings. To overcome the pinhole-specific assumptions of SHARP, our key idea is to align various images in a unified omnidirectional latent space. Thus, we propose UniSHARP, which performs implicit alignment in both feature and Gaussian spaces. Specifically, Gaussian primitives are arranged along rays and radial distances in a ray-based universal representation, while 2D semantic and 3D spatial features extracted from UniK3D-inspired encoders are jointly decoded to generate the complete Gaussian cloud. To comprehensively evaluate our method, we construct a benchmark covering diverse imaging systems across various scenes. The benchmark is further stratified by field of view (FoV) to enable fine-grained assessment of the universal monocular rendering task. Extensive experiments on the proposed benchmark demonstrate the effectiveness of UniSHARP, outperforming alternative methods by a large margin. The project page can be found at: https://insta360-research-team.github.io/Unisharp-website/
Demystifying Reinforcement Learning for Long-Horizon Tool-Using Agents: A Comprehensive Recipe
Mar 23, 2026Reinforcement Learning (RL) is essential for evolving Large Language Models (LLMs) into autonomous agents capable of long-horizon planning, yet a practical recipe for scaling RL in complex, multi-turn environments remains elusive. This paper presents a systematic empirical study using TravelPlanner, a challenging testbed requiring tool orchestration to satisfy multifaceted constraints. We decompose the agentic RL design space along 5 axes: reward shaping, model scaling, data composition, algorithm selection, and environmental stability. Our controlled experiments yield 7 key takeaways, e.g., (1) reward and algorithm choices are scale-dependent as smaller models benefit from staged rewards and enhanced exploration, whereas larger models converge efficiently with simpler dense rewards, (2) ~ 1K training samples with a balanced difficulty mixture mark a sweet spot for both in-domain and out-of-domain performance, and (3) environmental stability is critical to prevent policy degradation. Based on our distilled recipe, our RL-trained models achieve state-of-the-art performance on TravelPlanner, significantly outperforming leading LLMs.
VSearcher: Long-Horizon Multimodal Search Agent via Reinforcement Learning
Mar 03, 2026Large models are increasingly becoming autonomous agents that interact with real-world environments and use external tools to augment their static capabilities. However, most recent progress has focused on text-only large language models, which are limited to a single modality and therefore have narrower application scenarios. On the other hand, multimodal large models, while offering stronger perceptual capabilities, remain limited to static knowledge and lack the ability to access and leverage up-to-date web information. In this paper, we propose VSearcher, turning static multimodal model into multimodal search agent capable of long-horizon, multi-turn tool use in real-world web environments, including text search, image search, and web browsing, via reinforcement learning. Specifically, we introduce Iterative Injection Data Synthesis pipeline to generate large-scale, complex multimodal QA questions, which are further filtered with comprehensive metrics to ensure high quality and sufficient difficulty. We then adopt an SFT-then-RL training pipeline to turn base multimodal models to agent capable of multi-turn tool calling in real-world web environments. Besides, we propose a multimodal search benchmark MM-SearchExam dedicated to evaluating search capabilities of multimodal search agents, which proves highly challenging for recent proprietary models. Extensive evaluations across multiple multimodal search benchmarks reveal effectiveness of our method. VSearcher achieves superior performance compared to recent multimodal search agents and even surpasses several proprietary models on multimodal web search tasks.
SketchThinker-R1: Towards Efficient Sketch-Style Reasoning in Large Multimodal Models
Jan 06, 2026Despite the empirical success of extensive, step-by-step reasoning in large multimodal models, long reasoning processes inevitably incur substantial computational overhead, i.e., in terms of higher token costs and increased response time, which undermines inference efficiency. In contrast, humans often employ sketch-style reasoning: a concise, goal-directed cognitive process that prioritizes salient information and enables efficient problem-solving. Inspired by this cognitive efficiency, we propose SketchThinker-R1, which incentivizes sketch-style reasoning ability in large multimodal models. Our method consists of three primary stages. In the Sketch-Mode Cold Start stage, we convert standard long reasoning process into sketch-style reasoning and finetune base multimodal model, instilling initial sketch-style reasoning capability. Next, we train SketchJudge Reward Model, which explicitly evaluates thinking process of model and assigns higher scores to sketch-style reasoning. Finally, we conduct Sketch-Thinking Reinforcement Learning under supervision of SketchJudge to further generalize sketch-style reasoning ability. Experimental evaluation on four benchmarks reveals that our SketchThinker-R1 achieves over 64% reduction in reasoning token cost without compromising final answer accuracy. Qualitative analysis further shows that sketch-style reasoning focuses more on key cues during problem solving.
Uncertainty-o: One Model-agnostic Framework for Unveiling Uncertainty in Large Multimodal Models
Jun 09, 2025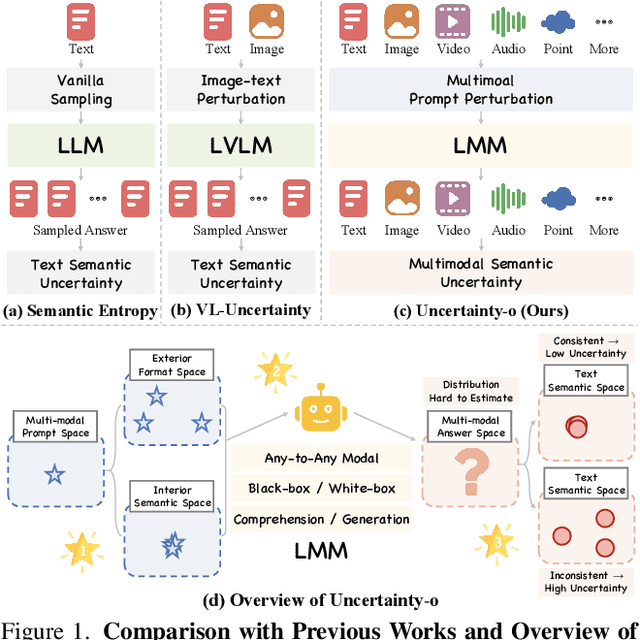
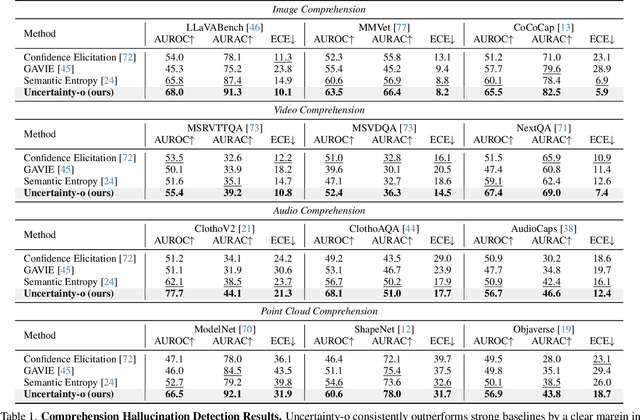
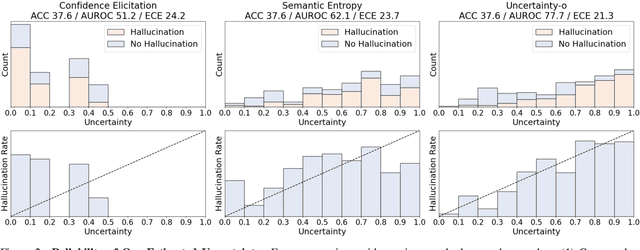

Large Multimodal Models (LMMs), harnessing the complementarity among diverse modalities, are often considered more robust than pure Language Large Models (LLMs); yet do LMMs know what they do not know? There are three key open questions remaining: (1) how to evaluate the uncertainty of diverse LMMs in a unified manner, (2) how to prompt LMMs to show its uncertainty, and (3) how to quantify uncertainty for downstream tasks. In an attempt to address these challenges, we introduce Uncertainty-o: (1) a model-agnostic framework designed to reveal uncertainty in LMMs regardless of their modalities, architectures, or capabilities, (2) an empirical exploration of multimodal prompt perturbations to uncover LMM uncertainty, offering insights and findings, and (3) derive the formulation of multimodal semantic uncertainty, which enables quantifying uncertainty from multimodal responses. Experiments across 18 benchmarks spanning various modalities and 10 LMMs (both open- and closed-source) demonstrate the effectiveness of Uncertainty-o in reliably estimating LMM uncertainty, thereby enhancing downstream tasks such as hallucination detection, hallucination mitigation, and uncertainty-aware Chain-of-Thought reasoning.
MC-GRU:a Multi-Channel GRU network for generalized nonlinear structural response prediction across structures
Mar 10, 2025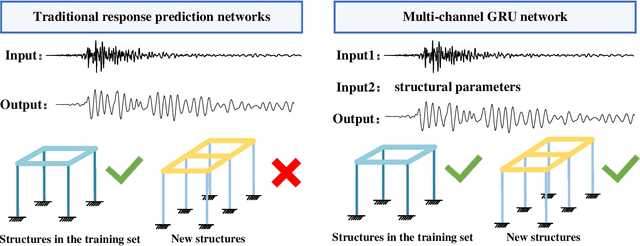
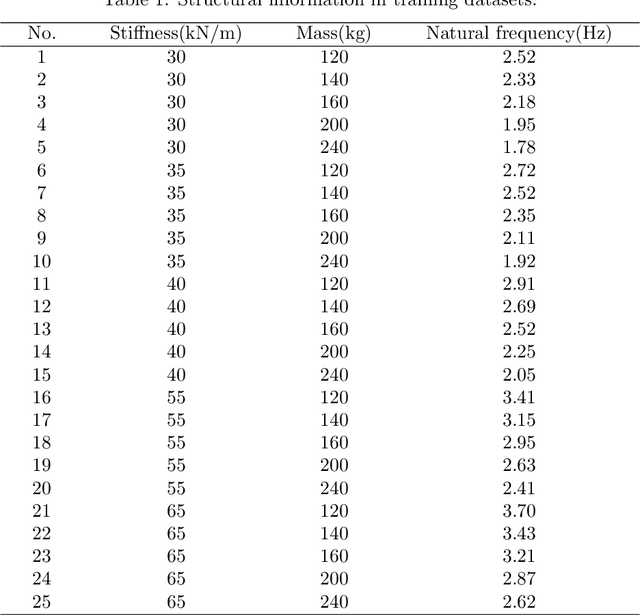
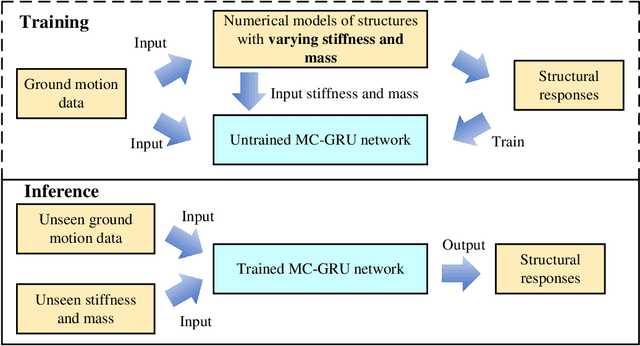
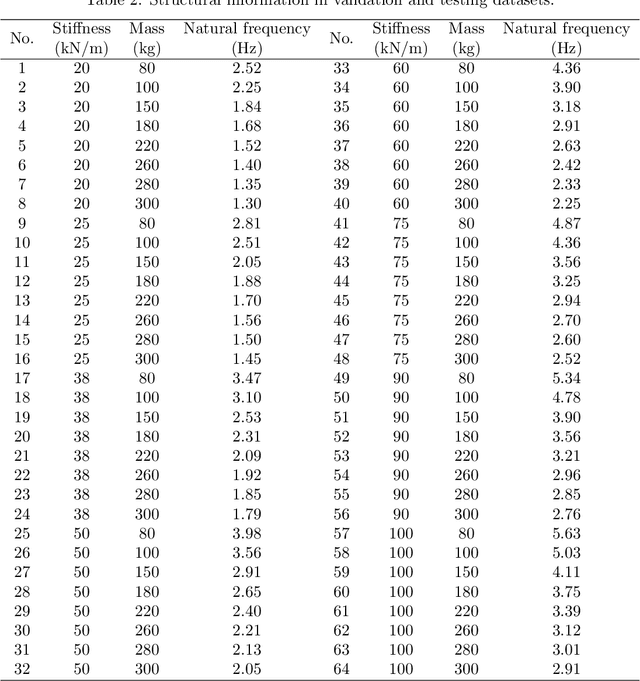
Accurate prediction of seismic responses and quantification of structural damage are critical in civil engineering. Traditional approaches such as finite element analysis could lack computational efficiency, especially for complex structural systems under extreme hazards. Recently, artificial intelligence has provided an alternative to efficiently model highly nonlinear behaviors. However, existing models face challenges in generalizing across diverse structural systems. This paper proposes a novel multi-channel gated recurrent unit (MC-GRU) network aimed at achieving generalized nonlinear structural response prediction for varying structures. The key concept lies in the integration of a multi-channel input mechanism to GRU with an extra input of structural information to the candidate hidden state, which enables the network to learn the dynamic characteristics of diverse structures and thus empower the generalizability and adaptiveness to unseen structures. The performance of the proposed MC-GRU is validated through a series of case studies, including a single-degree-of-freedom linear system, a hysteretic Bouc-Wen system, and a nonlinear reinforced concrete column from experimental testing. Results indicate that the proposed MC-GRU overcomes the major generalizability issues of existing methods, with capability of accurately inferring seismic responses of varying structures. Additionally, it demonstrates enhanced capabilities in representing nonlinear structural dynamics compared to traditional models such as GRU and LSTM.
VL-Uncertainty: Detecting Hallucination in Large Vision-Language Model via Uncertainty Estimation
Nov 18, 2024



Given the higher information load processed by large vision-language models (LVLMs) compared to single-modal LLMs, detecting LVLM hallucinations requires more human and time expense, and thus rise a wider safety concerns. In this paper, we introduce VL-Uncertainty, the first uncertainty-based framework for detecting hallucinations in LVLMs. Different from most existing methods that require ground-truth or pseudo annotations, VL-Uncertainty utilizes uncertainty as an intrinsic metric. We measure uncertainty by analyzing the prediction variance across semantically equivalent but perturbed prompts, including visual and textual data. When LVLMs are highly confident, they provide consistent responses to semantically equivalent queries. However, when uncertain, the responses of the target LVLM become more random. Considering semantically similar answers with different wordings, we cluster LVLM responses based on their semantic content and then calculate the cluster distribution entropy as the uncertainty measure to detect hallucination. Our extensive experiments on 10 LVLMs across four benchmarks, covering both free-form and multi-choice tasks, show that VL-Uncertainty significantly outperforms strong baseline methods in hallucination detection.
Harnessing Uncertainty-aware Bounding Boxes for Unsupervised 3D Object Detection
Aug 01, 2024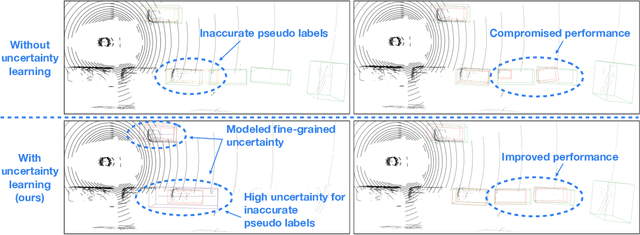
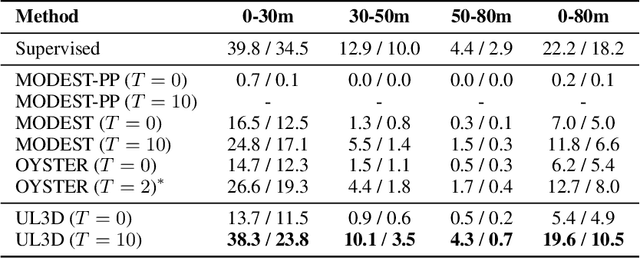
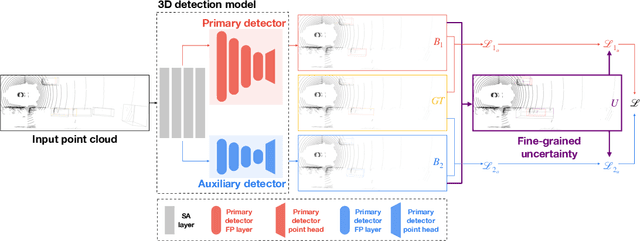
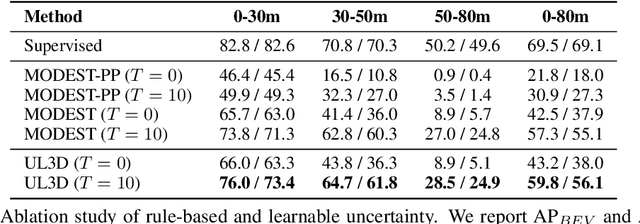
Unsupervised 3D object detection aims to identify objects of interest from unlabeled raw data, such as LiDAR points. Recent approaches usually adopt pseudo 3D bounding boxes (3D bboxes) from clustering algorithm to initialize the model training, and then iteratively updating both pseudo labels and the trained model. However, pseudo bboxes inevitably contain noises, and such inaccurate annotation accumulates to the final model, compromising the performance. Therefore, in an attempt to mitigate the negative impact of pseudo bboxes, we introduce a new uncertainty-aware framework. In particular, Our method consists of two primary components: uncertainty estimation and uncertainty regularization. (1) In the uncertainty estimation phase, we incorporate an extra auxiliary detection branch alongside the primary detector. The prediction disparity between the primary and auxiliary detectors is leveraged to estimate uncertainty at the box coordinate level, including position, shape, orientation. (2) Based on the assessed uncertainty, we regularize the model training via adaptively adjusting every 3D bboxes coordinates. For pseudo bbox coordinates with high uncertainty, we assign a relatively low loss weight. Experiment verifies that the proposed method is robust against the noisy pseudo bboxes, yielding substantial improvements on nuScenes and Lyft compared to existing techniques, with increases of 6.9% in AP$_{BEV}$ and 2.5% in AP$_{3D}$ on nuScenes, and 2.2% in AP$_{BEV}$ and 1.0% in AP$_{3D}$ on Lyft.
Approaching Outside: Scaling Unsupervised 3D Object Detection from 2D Scene
Jul 11, 2024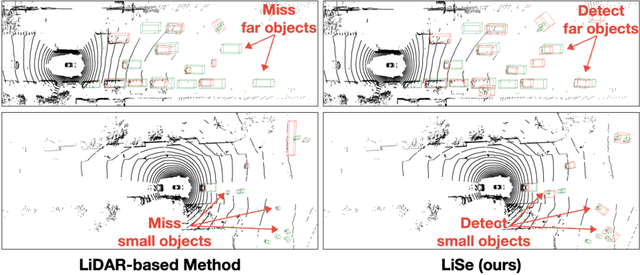

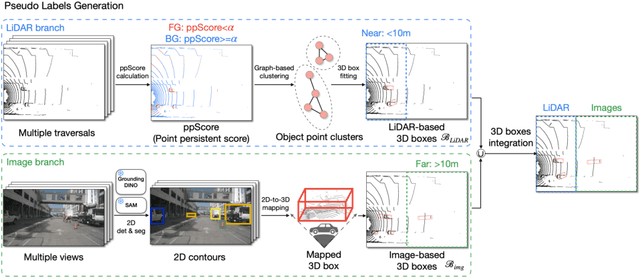

The unsupervised 3D object detection is to accurately detect objects in unstructured environments with no explicit supervisory signals. This task, given sparse LiDAR point clouds, often results in compromised performance for detecting distant or small objects due to the inherent sparsity and limited spatial resolution. In this paper, we are among the early attempts to integrate LiDAR data with 2D images for unsupervised 3D detection and introduce a new method, dubbed LiDAR-2D Self-paced Learning (LiSe). We argue that RGB images serve as a valuable complement to LiDAR data, offering precise 2D localization cues, particularly when scarce LiDAR points are available for certain objects. Considering the unique characteristics of both modalities, our framework devises a self-paced learning pipeline that incorporates adaptive sampling and weak model aggregation strategies. The adaptive sampling strategy dynamically tunes the distribution of pseudo labels during training, countering the tendency of models to overfit easily detected samples, such as nearby and large-sized objects. By doing so, it ensures a balanced learning trajectory across varying object scales and distances. The weak model aggregation component consolidates the strengths of models trained under different pseudo label distributions, culminating in a robust and powerful final model. Experimental evaluations validate the efficacy of our proposed LiSe method, manifesting significant improvements of +7.1% AP$_{BEV}$ and +3.4% AP$_{3D}$ on nuScenes, and +8.3% AP$_{BEV}$ and +7.4% AP$_{3D}$ on Lyft compared to existing techniques.