 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEDSYN: Benchmarking Multi-EviDence SYNthesis in Complex Clinical Cases for Multimodal Large Language Models
Feb 25, 2026Multimodal large language models (MLLMs) have shown great potential in medical applications, yet existing benchmarks inadequately capture real-world clinical complexity. We introduce MEDSYN, a multilingual, multimodal benchmark of highly complex clinical cases with up to 7 distinct visual clinical evidence (CE) types per case. Mirroring clinical workflow, we evaluate 18 MLLMs on differential diagnosis (DDx) generation and final diagnosis (FDx) selection. While top models often match or even outperform human experts on DDx generation, all MLLMs exhibit a much larger DDx--FDx performance gap compared to expert clinicians, indicating a failure mode in synthesis of heterogeneous CE types. Ablations attribute this failure to (i) overreliance on less discriminative textual CE ($\it{e.g.}$, medical history) and (ii) a cross-modal CE utilization gap. We introduce Evidence Sensitivity to quantify the latter and show that a smaller gap correlates with higher diagnostic accuracy. Finally, we demonstrate how it can be used to guide interventions to improve model performance. We will open-source our benchmark and code.
Large AI Models in Health Informatics: Applications, Challenges, and the Future
Mar 21, 2023



Large AI models, or foundation models, are models recently emerging with massive scales both parameter-wise and data-wise, the magnitudes of which often reach beyond billions. Once pretrained, large AI models demonstrate impressive performance in various downstream tasks. A concrete example is the recent debut of ChatGPT, whose capability has compelled people's imagination about the far-reaching influence that large AI models can have and their potential to transform different domains of our life. In health informatics, the advent of large AI models has brought new paradigms for the design of methodologies. The scale of multimodality data in the biomedical and health domain has been ever-expanding especially since the community embraced the era of deep learning, which provides the ground to develop, validate, and advance large AI models for breakthroughs in health-related areas. This article presents an up-to-date comprehensive review of large AI models, from background to their applications. We identify seven key sectors that large AI models are applicable and might have substantial influence, including 1) molecular biology and drug discovery; 2) medical diagnosis and decision-making; 3) medical imaging and vision; 4) medical informatics; 5) medical education; 6) public health; and 7) medical robotics. We examine their challenges in health informatics, followed by a critical discussion about potential future directions and pitfalls of large AI models in transforming the field of health informatics.
EVEN: An Event-Based Framework for Monocular Depth Estimation at Adverse Night Conditions
Feb 08, 2023



Accurate depth estimation under adverse night conditions has practical impact and applications, such as on autonomous driving and rescue robots. In this work, we studied monocular depth estimation at night time in which various adverse weather, light, and different road conditions exist, with data captured in both RGB and event modalities. Event camera can better capture intensity changes by virtue of its high dynamic range (HDR), which is particularly suitable to be applied at adverse night conditions in which the amount of light is limited in the scene. Although event data can retain visual perception that conventional RGB camera may fail to capture, the lack of texture and color information of event data hinders its applicability to accurately estimate depth alone. To tackle this problem, we propose an event-vision based framework that integrates low-light enhancement for the RGB source, and exploits the complementary merits of RGB and event data. A dataset that includes paired RGB and event streams, and ground truth depth maps has been constructed. Comprehensive experiments have been conducted, and the impact of different adverse weather combinations on the performance of framework has also been investigated. The results have shown that our proposed framework can better estimate monocular depth at adverse nights than six baselines.
MenuAI: Restaurant Food Recommendation System via a Transformer-based Deep Learning Model
Oct 15, 2022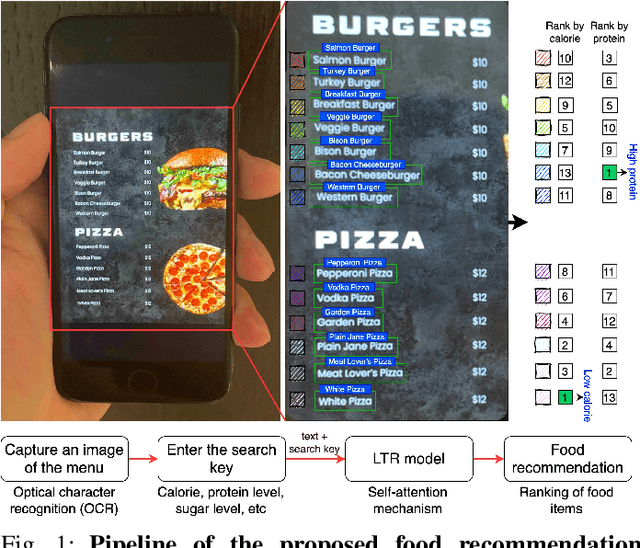
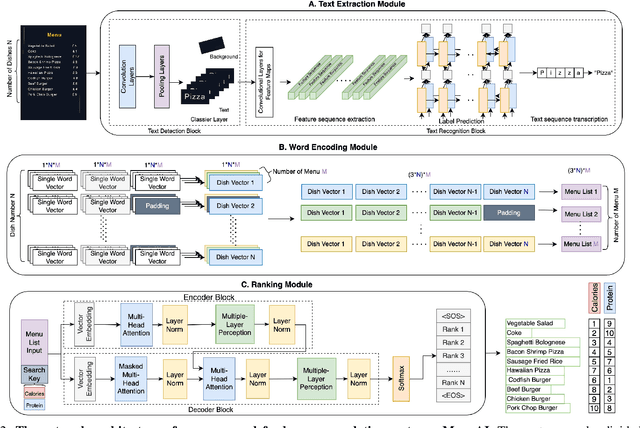
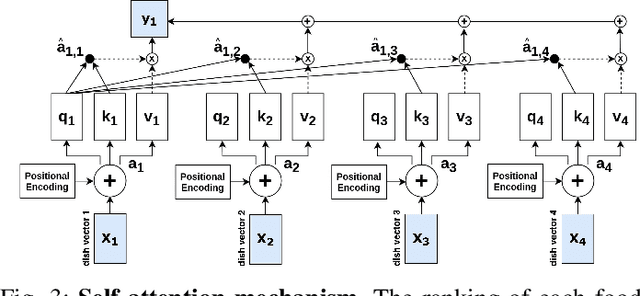
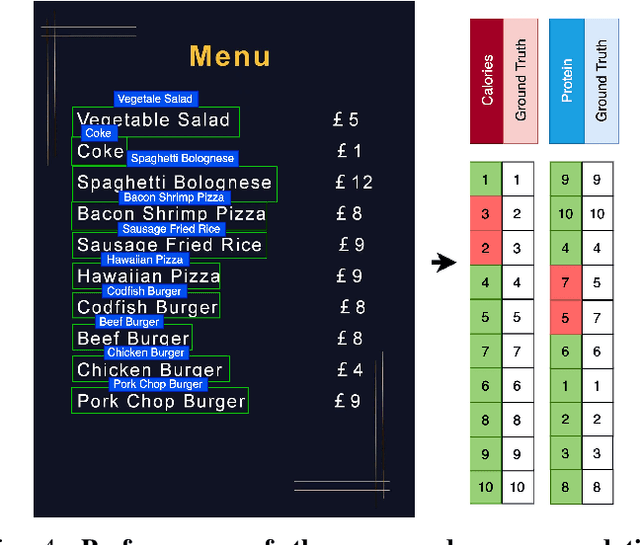
Food recommendation system has proven as an effective technology to provide guidance on dietary choices, and this is especially important for patients suffering from chronic diseases. Unlike other multimedia recommendations, such as books and movies, food recommendation task is highly relied on the context at the moment, since users' food preference can be highly dynamic over time. For example, individuals tend to eat more calories earlier in the day and eat a little less at dinner. However, there are still limited research works trying to incorporate both current context and nutritional knowledge for food recommendation. Thus, a novel restaurant food recommendation system is proposed in this paper to recommend food dishes to users according to their special nutritional needs. Our proposed system utilises Optical Character Recognition (OCR) technology and a transformer-based deep learning model, Learning to Rank (LTR) model, to conduct food recommendation. Given a single RGB image of the menu, the system is then able to rank the food dishes in terms of the input search key (e.g., calorie, protein level). Due to the property of the transformer, our system can also rank unseen food dishes. Comprehensive experiments are conducted to validate our methods on a self-constructed menu dataset, known as MenuRank dataset. The promising results, with accuracy ranging from 77.2% to 99.5%, have demonstrated the great potential of LTR model in addressing food recommendation problems.
Clustering Egocentric Images in Passive Dietary Monitoring with Self-Supervised Learning
Aug 25, 2022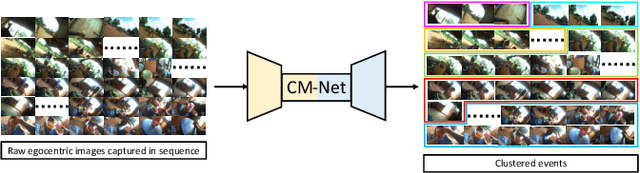
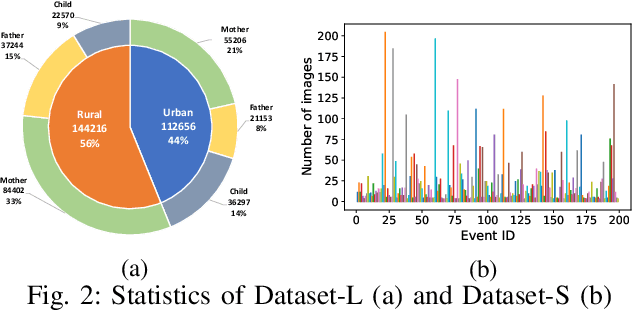
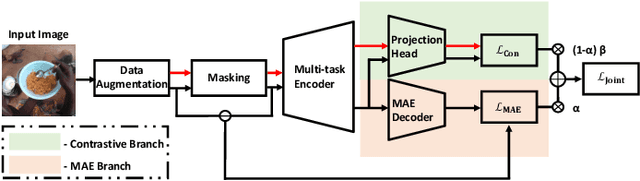
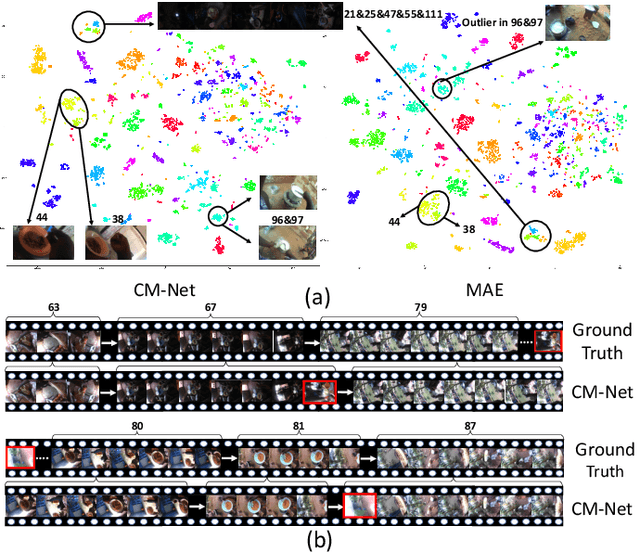
In our recent dietary assessment field studies on passive dietary monitoring in Ghana, we have collected over 250k in-the-wild images. The dataset is an ongoing effort to facilitate accurate measurement of individual food and nutrient intake in low and middle income countries with passive monitoring camera technologies. The current dataset involves 20 households (74 subjects) from both the rural and urban regions of Ghana, and two different types of wearable cameras were used in the studies. Once initiated, wearable cameras continuously capture subjects' activities, which yield massive amounts of data to be cleaned and annotated before analysis is conducted. To ease the data post-processing and annotation tasks, we propose a novel self-supervised learning framework to cluster the large volume of egocentric images into separate events. Each event consists of a sequence of temporally continuous and contextually similar images. By clustering images into separate events, annotators and dietitians can examine and analyze the data more efficiently and facilitate the subsequent dietary assessment processes. Validated on a held-out test set with ground truth labels, the proposed framework outperforms baselines in terms of clustering quality and classification accuracy.