 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegCol Challenge: Semantic Segmentation for Tools and Fold Edges in Colonoscopy data
Dec 20, 2024

Colorectal cancer (CRC) remains a leading cause of cancer-related deaths worldwide, with polyp removal being an effective early screening method. However, navigating the colon for thorough polyp detection poses significant challenges. To advance camera navigation in colonoscopy, we propose the Semantic Segmentation for Tools and Fold Edges in Colonoscopy (SegCol) Challenge. This challenge introduces a dataset from the EndoMapper repository, featuring manually annotated, pixel-level semantic labels for colon folds and endoscopic tools across selected frames from 96 colonoscopy videos. By providing fold edges as anatomical landmarks and depth discontinuity information from both fold and tool labels, the dataset is aimed to improve depth perception and localization methods. Hosted as part of the Endovis Challenge at MICCAI 2024, SegCol aims to drive innovation in colonoscopy navigation systems. Details are available at https://www.synapse.org/Synapse:syn54124209/wiki/626563, and code resources at https://github.com/surgical-vision/segcol_challenge .
Mismatched: Evaluating the Limits of Image Matching Approaches and Benchmarks
Aug 29, 2024



Three-dimensional (3D) reconstruction from two-dimensional images is an active research field in computer vision, with applications ranging from navigation and object tracking to segmentation and three-dimensional modeling. Traditionally, parametric techniques have been employed for this task. However, recent advancements have seen a shift towards learning-based methods. Given the rapid pace of research and the frequent introduction of new image matching methods, it is essential to evaluate them. In this paper, we present a comprehensive evaluation of various image matching methods using a structure-from-motion pipeline. We assess the performance of these methods on both in-domain and out-of-domain datasets, identifying key limitations in both the methods and benchmarks. We also investigate the impact of edge detection as a pre-processing step. Our analysis reveals that image matching for 3D reconstruction remains an open challenge, necessitating careful selection and tuning of models for specific scenarios, while also highlighting mismatches in how metrics currently represent method performance.
EVEN: An Event-Based Framework for Monocular Depth Estimation at Adverse Night Conditions
Feb 08, 2023



Accurate depth estimation under adverse night conditions has practical impact and applications, such as on autonomous driving and rescue robots. In this work, we studied monocular depth estimation at night time in which various adverse weather, light, and different road conditions exist, with data captured in both RGB and event modalities. Event camera can better capture intensity changes by virtue of its high dynamic range (HDR), which is particularly suitable to be applied at adverse night conditions in which the amount of light is limited in the scene. Although event data can retain visual perception that conventional RGB camera may fail to capture, the lack of texture and color information of event data hinders its applicability to accurately estimate depth alone. To tackle this problem, we propose an event-vision based framework that integrates low-light enhancement for the RGB source, and exploits the complementary merits of RGB and event data. A dataset that includes paired RGB and event streams, and ground truth depth maps has been constructed. Comprehensive experiments have been conducted, and the impact of different adverse weather combinations on the performance of framework has also been investigated. The results have shown that our proposed framework can better estimate monocular depth at adverse nights than six baselines.
MenuAI: Restaurant Food Recommendation System via a Transformer-based Deep Learning Model
Oct 15, 2022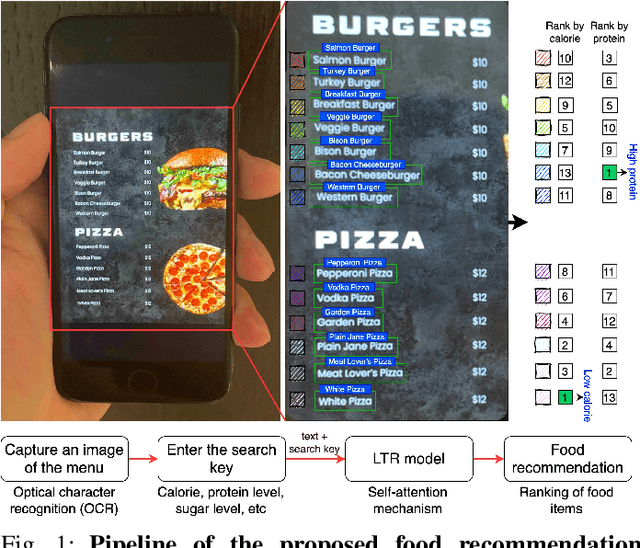
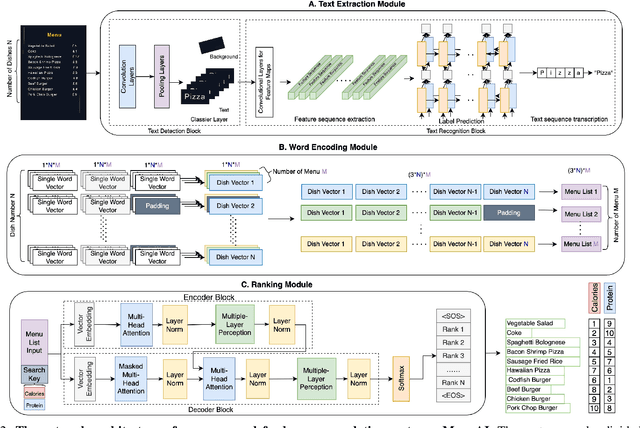
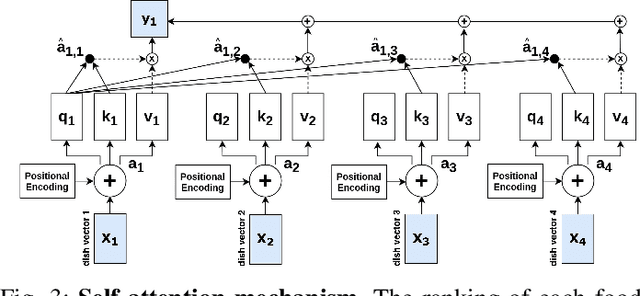
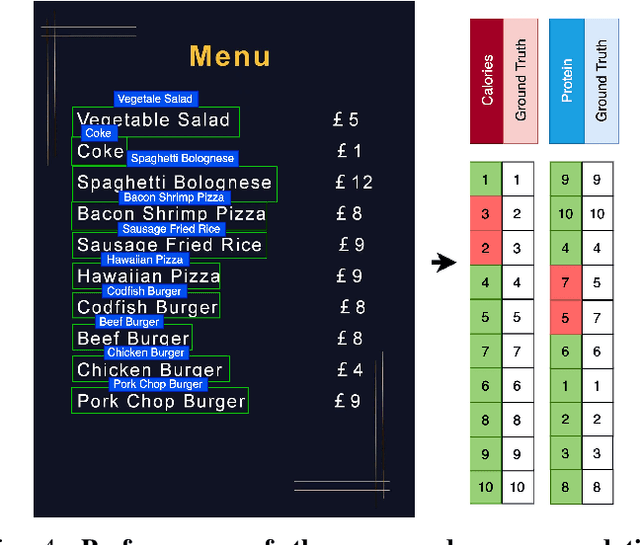
Food recommendation system has proven as an effective technology to provide guidance on dietary choices, and this is especially important for patients suffering from chronic diseases. Unlike other multimedia recommendations, such as books and movies, food recommendation task is highly relied on the context at the moment, since users' food preference can be highly dynamic over time. For example, individuals tend to eat more calories earlier in the day and eat a little less at dinner. However, there are still limited research works trying to incorporate both current context and nutritional knowledge for food recommendation. Thus, a novel restaurant food recommendation system is proposed in this paper to recommend food dishes to users according to their special nutritional needs. Our proposed system utilises Optical Character Recognition (OCR) technology and a transformer-based deep learning model, Learning to Rank (LTR) model, to conduct food recommendation. Given a single RGB image of the menu, the system is then able to rank the food dishes in terms of the input search key (e.g., calorie, protein level). Due to the property of the transformer, our system can also rank unseen food dishes. Comprehensive experiments are conducted to validate our methods on a self-constructed menu dataset, known as MenuRank dataset. The promising results, with accuracy ranging from 77.2% to 99.5%, have demonstrated the great potential of LTR model in addressing food recommendation problems.
Clustering Egocentric Images in Passive Dietary Monitoring with Self-Supervised Learning
Aug 25, 2022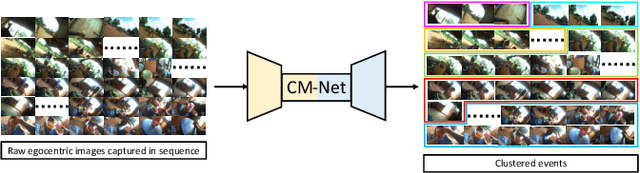
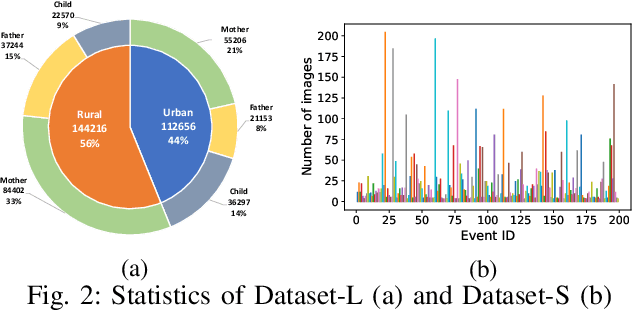
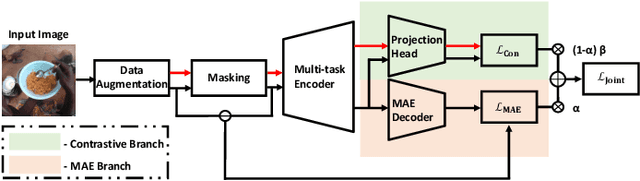
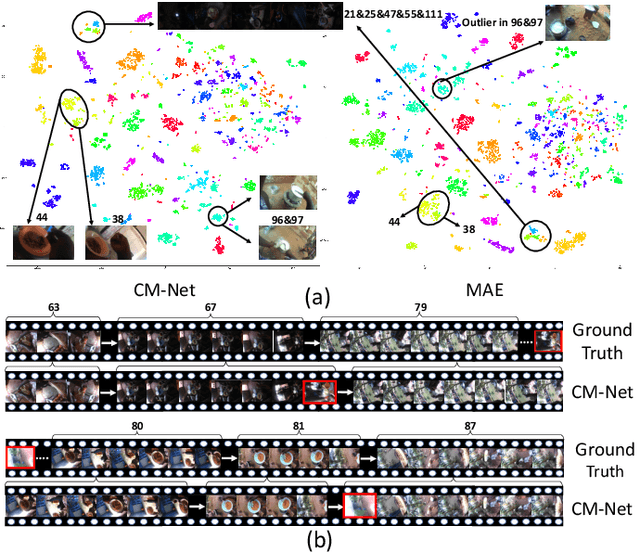
In our recent dietary assessment field studies on passive dietary monitoring in Ghana, we have collected over 250k in-the-wild images. The dataset is an ongoing effort to facilitate accurate measurement of individual food and nutrient intake in low and middle income countries with passive monitoring camera technologies. The current dataset involves 20 households (74 subjects) from both the rural and urban regions of Ghana, and two different types of wearable cameras were used in the studies. Once initiated, wearable cameras continuously capture subjects' activities, which yield massive amounts of data to be cleaned and annotated before analysis is conducted. To ease the data post-processing and annotation tasks, we propose a novel self-supervised learning framework to cluster the large volume of egocentric images into separate events. Each event consists of a sequence of temporally continuous and contextually similar images. By clustering images into separate events, annotators and dietitians can examine and analyze the data more efficiently and facilitate the subsequent dietary assessment processes. Validated on a held-out test set with ground truth labels, the proposed framework outperforms baselines in terms of clustering quality and classification accuracy.