 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Explainability as a Training-Time Reliability Signal for Efficient ECG Classification
Jun 10, 2026Training deep neural networks for clinical time-series analysis is computationally demanding, yet many healthcare settings lack the resources required for repeated model development and deployment. This challenge is particularly evident in electrocardiogram classification, where large datasets and long training schedules make efficiency practically important. Progressive Data Dropout reduces training cost by excluding samples from gradient updates once they are learned, but it relies on model confidence and may retain samples that are difficult due to noise or ambiguity rather than useful signal. In this work, we introduce ERTS, an explainability-based reliability training signal for efficient ECG classification. ERTS uses explanation quality during training to distinguish between informative and unreliable uncertainty. Building on progressive data selection, we compute Grad-CAM attention maps for candidate samples and derive a focus score that measures whether model predictions are supported by coherent and localised patterns. Samples with low focus are filtered out, while those with meaningful attention are prioritised for gradient updates. We evaluate ERTS across three ECG datasets and multiple backbone architectures, showing consistent improvements in macro-F1 alongside reduced effective training cost. These results suggest that explanation quality can serve as a practical signal for improving both efficiency and reliability in clinical time-series learning. Code will be released.
Biosignal Fingerprinting: A Cross-Modal PPG-ECG Foundation Model
May 10, 2026Cardiovascular disease remains the leading cause of global mortality, yet scalable cardiac monitoring is hindered by the gap between diagnostic-rich ECG and ubiquitous wearable PPG. Bridging this gap requires representations that are compact, transferable across modalities and devices, and deployable without task-specific retraining. Here we introduce biosignal fingerprints: compact latent representations of cardiovascular state derived from a cross-modal foundation model, the Multi-modal Masked Autoencoder (M2AE), trained on over 3.4 million paired ECG and PPG signals. M2AE integrates modality-specific encoders with a shared bottleneck and dual decoders, jointly optimized using reconstruction and cross-modal contrastive objectives, yielding generalizable fingerprints that retain intra- and inter-modality features. Like a biometric fingerprint, these representations uniquely encode an individual's cardiovascular state in a modality-agnostic, privacy-preserving form reusable across clinical tasks without exposing raw waveform data or requiring model retraining. Across 7 downstream tasks, spanning cross-modal reconstruction, cardiovascular disease classification, hypertension detection, mortality prediction, and demographic inference, biosignal fingerprints achieve competitive or superior performance compared to leading domain-specialist foundation models in frozen settings, including an AUROC of 0.974 for five-class CVD classification and 0.877 for hypertension detection, with a maximum improvement of 27.7% in AUROC across 5 classification tasks. Critically, strong performance is maintained with only a single modality, enabling deployment in resource-constrained, single-sensor environments typical of real-world wearable monitoring, with direct implications for continuous cardiovascular monitoring across clinical and consumer health settings.
MECO: A Multimodal Dataset for Emotion and Cognitive Understanding in Older Adults
Apr 03, 2026While affective computing has advanced considerably, multimodal emotion prediction in aging populations remains underexplored, largely due to the scarcity of dedicated datasets. Existing multimodal benchmarks predominantly target young, cognitively healthy subjects, neglecting the influence of cognitive decline on emotional expression and physiological responses. To bridge this gap, we present MECO, a Multimodal dataset for Emotion and Cognitive understanding in Older adults. MECO includes 42 participants and provides approximately 38 hours of multimodal signals, yielding 30,592 synchronized samples. To maximize ecological validity, data collection followed standardized protocols within community-based settings. The modalities cover video, audio, electroencephalography (EEG), and electrocardiography (ECG). In addition, the dataset offers comprehensive annotations of emotional and cognitive states, including self-assessed valence, arousal, six basic emotions, and Mini-Mental State Examination cognitive scores. We further establish baseline benchmarks for both emotion and cognitive prediction. MECO serves as a foundational resource for multimodal modeling of affect and cognition in aging populations, facilitating downstream applications such as personalized emotion recognition and early detection of mild cognitive impairment (MCI) in real-world settings. The complete dataset and supplementary materials are available at https://maitrechen.github.io/meco-page/.
SignalMC-MED: A Multimodal Benchmark for Evaluating Biosignal Foundation Models on Single-Lead ECG and PPG
Mar 10, 2026Recent biosignal foundation models (FMs) have demonstrated promising performance across diverse clinical prediction tasks, yet systematic evaluation on long-duration multimodal data remains limited. We introduce SignalMC-MED, a benchmark for evaluating biosignal FMs on synchronized single-lead electrocardiogram (ECG) and photoplethysmogram (PPG) data. Derived from the MC-MED dataset, SignalMC-MED comprises 22,256 visits with 10-minute overlapping ECG and PPG signals, and includes 20 clinically relevant tasks spanning prediction of demographics, emergency department disposition, laboratory value regression, and detection of prior ICD-10 diagnoses. Using this benchmark, we perform a systematic evaluation of representative time-series and biosignal FMs across ECG-only, PPG-only, and ECG + PPG settings. We find that domain-specific biosignal FMs consistently outperform general time-series models, and that multimodal ECG + PPG fusion yields robust improvements over unimodal inputs. Moreover, using the full 10-minute signal consistently outperforms shorter segments, and larger model variants do not reliably outperform smaller ones. Hand-crafted ECG domain features provide a strong baseline and offer complementary value when combined with learned FM representations. Together, these results establish SignalMC-MED as a standardized benchmark and provide practical guidance for evaluating and deploying biosignal FMs.
Cross-Subject and Cross-Montage EEG Transfer Learning via Individual Tangent Space Alignment and Spatial-Riemannian Feature Fusion
Aug 11, 2025Personalised music-based interventions offer a powerful means of supporting motor rehabilitation by dynamically tailoring auditory stimuli to provide external timekeeping cues, modulate affective states, and stabilise gait patterns. Generalisable Brain-Computer Interfaces (BCIs) thus hold promise for adapting these interventions across individuals. However, inter-subject variability in EEG signals, further compounded by movement-induced artefacts and motor planning differences, hinders the generalisability of BCIs and results in lengthy calibration processes. We propose Individual Tangent Space Alignment (ITSA), a novel pre-alignment strategy incorporating subject-specific recentering, distribution matching, and supervised rotational alignment to enhance cross-subject generalisation. Our hybrid architecture fuses Regularised Common Spatial Patterns (RCSP) with Riemannian geometry in parallel and sequential configurations, improving class separability while maintaining the geometric structure of covariance matrices for robust statistical computation. Using leave-one-subject-out cross-validation, `ITSA' demonstrates significant performance improvements across subjects and conditions. The parallel fusion approach shows the greatest enhancement over its sequential counterpart, with robust performance maintained across varying data conditions and electrode configurations. The code will be made publicly available at the time of publication.
Distribution-Based Masked Medical Vision-Language Model Using Structured Reports
Jul 29, 2025Medical image-language pre-training aims to align medical images with clinically relevant text to improve model performance on various downstream tasks. However, existing models often struggle with the variability and ambiguity inherent in medical data, limiting their ability to capture nuanced clinical information and uncertainty. This work introduces an uncertainty-aware medical image-text pre-training model that enhances generalization capabilities in medical image analysis. Building on previous methods and focusing on Chest X-Rays, our approach utilizes structured text reports generated by a large language model (LLM) to augment image data with clinically relevant context. These reports begin with a definition of the disease, followed by the `appearance' section to highlight critical regions of interest, and finally `observations' and `verdicts' that ground model predictions in clinical semantics. By modeling both inter- and intra-modal uncertainty, our framework captures the inherent ambiguity in medical images and text, yielding improved representations and performance on downstream tasks. Our model demonstrates significant advances in medical image-text pre-training, obtaining state-of-the-art performance on multiple downstream tasks.
IV-Bench: A Benchmark for Image-Grounded Video Perception and Reasoning in Multimodal LLMs
Apr 21, 2025Existing evaluation frameworks for Multimodal Large Language Models (MLLMs) primarily focus on image reasoning or general video understanding tasks, largely overlooking the significant role of image context in video comprehension. To bridge this gap, we propose IV-Bench, the first comprehensive benchmark for evaluating Image-Grounded Video Perception and Reasoning. IV-Bench consists of 967 videos paired with 2,585 meticulously annotated image-text queries across 13 tasks (7 perception and 6 reasoning tasks) and 5 representative categories. Extensive evaluations of state-of-the-art open-source (e.g., InternVL2.5, Qwen2.5-VL) and closed-source (e.g., GPT-4o, Gemini2-Flash and Gemini2-Pro) MLLMs demonstrate that current models substantially underperform in image-grounded video Perception and Reasoning, merely achieving at most 28.9% accuracy. Further analysis reveals key factors influencing model performance on IV-Bench, including inference pattern, frame number, and resolution. Additionally, through a simple data synthesis approach, we demonstratethe challenges of IV- Bench extend beyond merely aligning the data format in the training proecss. These findings collectively provide valuable insights for future research. Our codes and data are released in https://github.com/multimodal-art-projection/IV-Bench.
Is Temporal Prompting All We Need For Limited Labeled Action Recognition?
Apr 02, 2025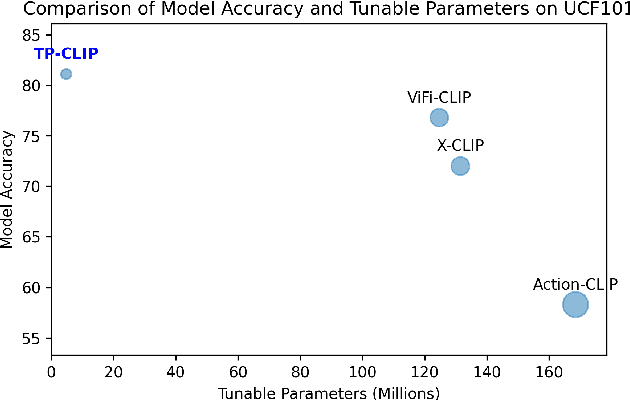
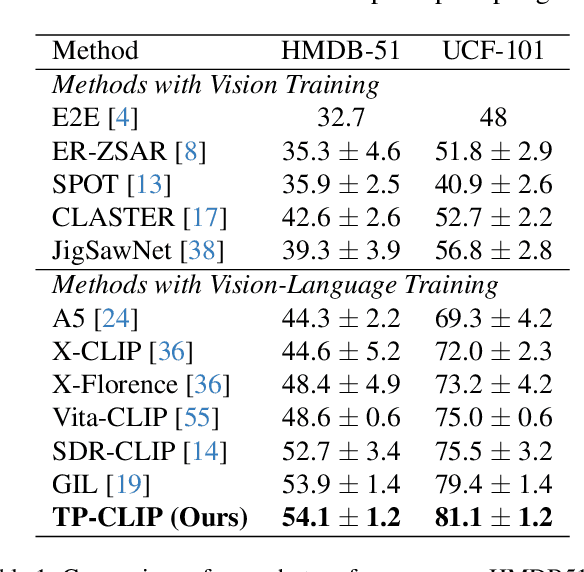
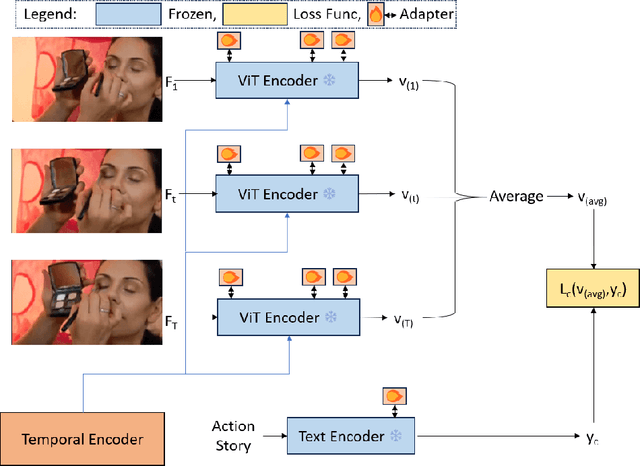
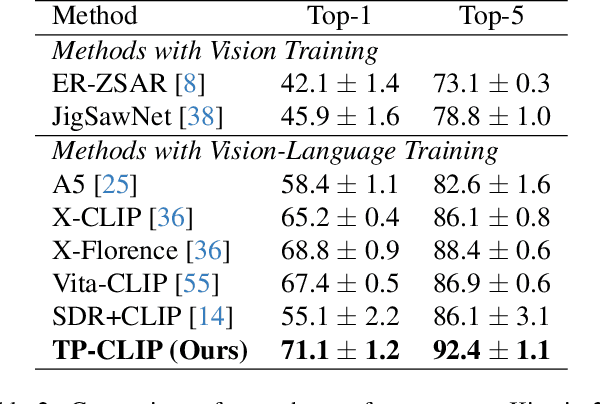
Video understanding has shown remarkable improvements in recent years, largely dependent on the availability of large scaled labeled datasets. Recent advancements in visual-language models, especially based on contrastive pretraining, have shown remarkable generalization in zero-shot tasks, helping to overcome this dependence on labeled datasets. Adaptations of such models for videos, typically involve modifying the architecture of vision-language models to cater to video data. However, this is not trivial, since such adaptations are mostly computationally intensive and struggle with temporal modeling. We present TP-CLIP, an adaptation of CLIP that leverages temporal visual prompting for temporal adaptation without modifying the core CLIP architecture. This preserves its generalization abilities. TP-CLIP efficiently integrates into the CLIP architecture, leveraging its pre-trained capabilities for video data. Extensive experiments across various datasets demonstrate its efficacy in zero-shot and few-shot learning, outperforming existing approaches with fewer parameters and computational efficiency. In particular, we use just 1/3 the GFLOPs and 1/28 the number of tuneable parameters in comparison to recent state-of-the-art and still outperform it by up to 15.8% depending on the task and dataset.
RiskAgent: Autonomous Medical AI Copilot for Generalist Risk Prediction
Mar 05, 2025The application of Large Language Models (LLMs) to various clinical applications has attracted growing research attention. However, real-world clinical decision-making differs significantly from the standardized, exam-style scenarios commonly used in current efforts. In this paper, we present the RiskAgent system to perform a broad range of medical risk predictions, covering over 387 risk scenarios across diverse complex diseases, e.g., cardiovascular disease and cancer. RiskAgent is designed to collaborate with hundreds of clinical decision tools, i.e., risk calculators and scoring systems that are supported by evidence-based medicine. To evaluate our method, we have built the first benchmark MedRisk specialized for risk prediction, including 12,352 questions spanning 154 diseases, 86 symptoms, 50 specialties, and 24 organ systems. The results show that our RiskAgent, with 8 billion model parameters, achieves 76.33% accuracy, outperforming the most recent commercial LLMs, o1, o3-mini, and GPT-4.5, and doubling the 38.39% accuracy of GPT-4o. On rare diseases, e.g., Idiopathic Pulmonary Fibrosis (IPF), RiskAgent outperforms o1 and GPT-4.5 by 27.27% and 45.46% accuracy, respectively. Finally, we further conduct a generalization evaluation on an external evidence-based diagnosis benchmark and show that our RiskAgent achieves the best results. These encouraging results demonstrate the great potential of our solution for diverse diagnosis domains. To improve the adaptability of our model in different scenarios, we have built and open-sourced a family of models ranging from 1 billion to 70 billion parameters. Our code, data, and models are all available at https://github.com/AI-in-Health/RiskAgent.
Learning Semi-Supervised Medical Image Segmentation from Spatial Registration
Sep 16, 2024



Semi-supervised medical image segmentation has shown promise in training models with limited labeled data and abundant unlabeled data. However, state-of-the-art methods ignore a potentially valuable source of unsupervised semantic information -- spatial registration transforms between image volumes. To address this, we propose CCT-R, a contrastive cross-teaching framework incorporating registration information. To leverage the semantic information available in registrations between volume pairs, CCT-R incorporates two proposed modules: Registration Supervision Loss (RSL) and Registration-Enhanced Positive Sampling (REPS). The RSL leverages segmentation knowledge derived from transforms between labeled and unlabeled volume pairs, providing an additional source of pseudo-labels. REPS enhances contrastive learning by identifying anatomically-corresponding positives across volumes using registration transforms. Experimental results on two challenging medical segmentation benchmarks demonstrate the effectiveness and superiority of CCT-R across various semi-supervised settings, with as few as one labeled case. Our code is available at https://github.com/kathyliu579/ContrastiveCross-teachingWithRegistration.