 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Motion In-betweening by Diffusion over Continuous Implicit Representations
May 12, 2026Recent advances in generative models have yielded impressive progress on motion in-betweening, allowing for more complex, varied, and realistic motion transitions. However, recent methods still exhibit noticeable limitations in preserving keyframe information and ensuring motion continuity. In this paper, we propose a novel pipeline and sampling optimization strategy for latent diffusion models (LDM) based on motion implicit neural representations (INR). By establishing a mapping between INR and sparse spatial or temporal information within latent diffusion, our model can sample the INR parameters from extremely sparse and ambiguous keyframe data and reconstruct plausible and smooth motions from the manifold. Our experiments demonstrate the superior performance of our model, which significantly improves motion generation quality in scenarios with few keyframes while ensuring both keyframe accuracy and diversity of in-between motions.
Neural 3D Reconstruction of Planetary Surfaces from Descent-Phase Wide-Angle Imagery
Apr 14, 2026Digital elevation modeling of planetary surfaces is essential for studying past and ongoing geological processes. Wide-angle imagery acquired during spacecraft descent promises to offer a low-cost option for high-resolution terrain reconstruction. However, accurate 3D reconstruction from such imagery is challenging due to strong radial distortion and limited parallax from vertically descending, predominantly nadir-facing cameras. Conventional multi-view stereo exhibits limited depth range and reduced fidelity under these conditions and also lacks domain-specific priors. We present the first study of modern neural reconstruction methods for planetary descent imaging. We also develop a novel approach that incorporates an explicit neural height field representation, which provides a strong prior since planetary surfaces are generally continuous, smooth, solid, and free from floating objects. This study demonstrates that neural approaches offer a strong and competitive alternative to traditional multi-view stereo (MVS) methods. Experiments on simulated descent sequences over high-fidelity lunar and Mars terrains demonstrate that the proposed approach achieves increased spatial coverage while maintaining satisfactory estimation accuracy.
Ink Detection from Surface Topography of the Herculaneum Papyri
Mar 29, 2026Reading the Herculaneum papyri is challenging because both the scrolls and the ink, which is carbon-based, are carbonized. In X-ray radiography and tomography, ink detection typically relies on density- or composition-driven contrast, but carbon ink on carbonized papyrus provides little attenuation contrast. Building on the morphological hypothesis, we show that the surface morphology of written regions contains enough signal to distinguish ink from papyrus. To this end, we train machine learning models on three-dimensional optical profilometry from mechanically opened Herculaneum papyri to separate inked and uninked areas. We further quantify how lateral sampling governs learnability and how a native-resolution model behaves on coarsened inputs. We show that high-resolution topography alone contains a usable signal for ink detection. Diminishing segmentation performance with decreasing lateral resolution provides insight into the characteristic spatial scales that must be resolved on our dataset to exploit the morphological signal. These findings inform spatial resolution targets for morphology-based reading of closed scrolls through X-ray tomography.
Efficient Dense Crowd Trajectory Prediction Via Dynamic Clustering
Mar 18, 2026Crowd trajectory prediction plays a crucial role in public safety and management, where it can help prevent disasters such as stampedes. Recent works address the problem by predicting individual trajectories and considering surrounding objects based on manually annotated data. However, these approaches tend to overlook dense crowd scenarios, where the challenges of automation become more pronounced due to the massiveness, noisiness, and inaccuracy of the tracking outputs, resulting in high computational costs. To address these challenges, we propose and extensively evaluate a novel cluster-based approach that groups individuals based on similar attributes over time, enabling faster execution through accurate group summarisation. Our plug-and-play method can be combined with existing trajectory predictors by using our output centroid in place of their pedestrian input. We evaluate our proposed method on several challenging dense crowd scenes. We demonstrated that our approach leads to faster processing and lower memory usage when compared with state-of-the-art methods, while maintaining the accuracy
Is Training Necessary for Anomaly Detection?
Jan 30, 2026Current state-of-the-art multi-class unsupervised anomaly detection (MUAD) methods rely on training encoder-decoder models to reconstruct anomaly-free features. We first show these approaches have an inherent fidelity-stability dilemma in how they detect anomalies via reconstruction residuals. We then abandon the reconstruction paradigm entirely and propose Retrieval-based Anomaly Detection (RAD). RAD is a training-free approach that stores anomaly-free features in a memory and detects anomalies through multi-level retrieval, matching test patches against the memory. Experiments demonstrate that RAD achieves state-of-the-art performance across four established benchmarks (MVTec-AD, VisA, Real-IAD, 3D-ADAM) under both standard and few-shot settings. On MVTec-AD, RAD reaches 96.7\% Pixel AUROC with just a single anomaly-free image compared to 98.5\% of RAD's full-data performance. We further prove that retrieval-based scores theoretically upper-bound reconstruction-residual scores. Collectively, these findings overturn the assumption that MUAD requires task-specific training, showing that state-of-the-art anomaly detection is feasible with memory-based retrieval. Our code is available at https://github.com/longkukuhi/RAD.
Eliminating Hallucination in Diffusion-Augmented Interactive Text-to-Image Retrieval
Jan 28, 2026Diffusion-Augmented Interactive Text-to-Image Retrieval (DAI-TIR) is a promising paradigm that improves retrieval performance by generating query images via diffusion models and using them as additional ``views'' of the user's intent. However, these generative views can be incorrect because diffusion generation may introduce hallucinated visual cues that conflict with the original query text. Indeed, we empirically demonstrate that these hallucinated cues can substantially degrade DAI-TIR performance. To address this, we propose Diffusion-aware Multi-view Contrastive Learning (DMCL), a hallucination-robust training framework that casts DAI-TIR as joint optimization over representations of query intent and the target image. DMCL introduces semantic-consistency and diffusion-aware contrastive objectives to align textual and diffusion-generated query views while suppressing hallucinated query signals. This yields an encoder that acts as a semantic filter, effectively mapping hallucinated cues into a null space, improving robustness to spurious cues and better representing the user's intent. Attention visualization and geometric embedding-space analyses corroborate this filtering behavior. Across five standard benchmarks, DMCL delivers consistent improvements in multi-round Hits@10, reaching as high as 7.37\% over prior fine-tuned and zero-shot baselines, which indicates it is a general and robust training framework for DAI-TIR.
Splat-Portrait: Generalizing Talking Heads with Gaussian Splatting
Jan 26, 2026Talking Head Generation aims at synthesizing natural-looking talking videos from speech and a single portrait image. Previous 3D talking head generation methods have relied on domain-specific heuristics such as warping-based facial motion representation priors to animate talking motions, yet still produce inaccurate 3D avatar reconstructions, thus undermining the realism of generated animations. We introduce Splat-Portrait, a Gaussian-splatting-based method that addresses the challenges of 3D head reconstruction and lip motion synthesis. Our approach automatically learns to disentangle a single portrait image into a static 3D reconstruction represented as static Gaussian Splatting, and a predicted whole-image 2D background. It then generates natural lip motion conditioned on input audio, without any motion driven priors. Training is driven purely by 2D reconstruction and score-distillation losses, without 3D supervision nor landmarks. Experimental results demonstrate that Splat-Portrait exhibits superior performance on talking head generation and novel view synthesis, achieving better visual quality compared to previous works. Our project code and supplementary documents are public available at https://github.com/stonewalking/Splat-portrait.
Pixel-to-4D: Camera-Controlled Image-to-Video Generation with Dynamic 3D Gaussians
Jan 02, 2026Humans excel at forecasting the future dynamics of a scene given just a single image. Video generation models that can mimic this ability are an essential component for intelligent systems. Recent approaches have improved temporal coherence and 3D consistency in single-image-conditioned video generation. However, these methods often lack robust user controllability, such as modifying the camera path, limiting their applicability in real-world applications. Most existing camera-controlled image-to-video models struggle with accurately modeling camera motion, maintaining temporal consistency, and preserving geometric integrity. Leveraging explicit intermediate 3D representations offers a promising solution by enabling coherent video generation aligned with a given camera trajectory. Although these methods often use 3D point clouds to render scenes and introduce object motion in a later stage, this two-step process still falls short in achieving full temporal consistency, despite allowing precise control over camera movement. We propose a novel framework that constructs a 3D Gaussian scene representation and samples plausible object motion, given a single image in a single forward pass. This enables fast, camera-guided video generation without the need for iterative denoising to inject object motion into render frames. Extensive experiments on the KITTI, Waymo, RealEstate10K and DL3DV-10K datasets demonstrate that our method achieves state-of-the-art video quality and inference efficiency. The project page is available at https://melonienimasha.github.io/Pixel-to-4D-Website.
A Convolutional Neural Deferred Shader for Physics Based Rendering
Dec 22, 2025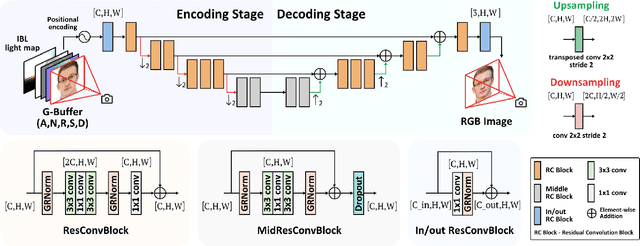
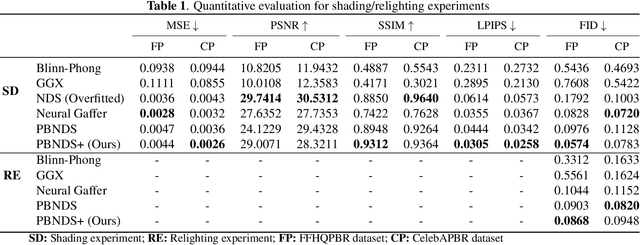


Recent advances in neural rendering have achieved impressive results on photorealistic shading and relighting, by using a multilayer perceptron (MLP) as a regression model to learn the rendering equation from a real-world dataset. Such methods show promise for photorealistically relighting real-world objects, which is difficult to classical rendering, as there is no easy-obtained material ground truth. However, significant challenges still remain the dense connections in MLPs result in a large number of parameters, which requires high computation resources, complicating the training, and reducing performance during rendering. Data driven approaches require large amounts of training data for generalization; unbalanced data might bias the model to ignore the unusual illumination conditions, e.g. dark scenes. This paper introduces pbnds+: a novel physics-based neural deferred shading pipeline utilizing convolution neural networks to decrease the parameters and improve the performance in shading and relighting tasks; Energy regularization is also proposed to restrict the model reflection during dark illumination. Extensive experiments demonstrate that our approach outperforms classical baselines, a state-of-the-art neural shading model, and a diffusion-based method.
Masked Generative Policy for Robotic Control
Dec 09, 2025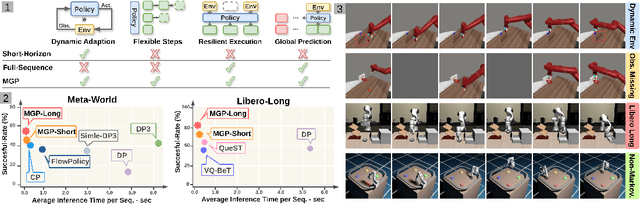

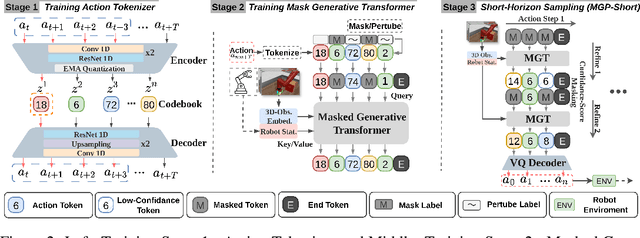

We present Masked Generative Policy (MGP), a novel framework for visuomotor imitation learning. We represent actions as discrete tokens, and train a conditional masked transformer that generates tokens in parallel and then rapidly refines only low-confidence tokens. We further propose two new sampling paradigms: MGP-Short, which performs parallel masked generation with score-based refinement for Markovian tasks, and MGP-Long, which predicts full trajectories in a single pass and dynamically refines low-confidence action tokens based on new observations. With globally coherent prediction and robust adaptive execution capabilities, MGP-Long enables reliable control on complex and non-Markovian tasks that prior methods struggle with. Extensive evaluations on 150 robotic manipulation tasks spanning the Meta-World and LIBERO benchmarks show that MGP achieves both rapid inference and superior success rates compared to state-of-the-art diffusion and autoregressive policies. Specifically, MGP increases the average success rate by 9% across 150 tasks while cutting per-sequence inference time by up to 35x. It further improves the average success rate by 60% in dynamic and missing-observation environments, and solves two non-Markovian scenarios where other state-of-the-art methods fail.