 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards deployment-centric multimodal AI beyond vision and language
Apr 04, 2025Multimodal artificial intelligence (AI) integrates diverse types of data via machine learning to improve understanding, prediction, and decision-making across disciplines such as healthcare, science, and engineering. However, most multimodal AI advances focus on models for vision and language data, while their deployability remains a key challenge. We advocate a deployment-centric workflow that incorporates deployment constraints early to reduce the likelihood of undeployable solutions, complementing data-centric and model-centric approaches. We also emphasise deeper integration across multiple levels of multimodality and multidisciplinary collaboration to significantly broaden the research scope beyond vision and language. To facilitate this approach, we identify common multimodal-AI-specific challenges shared across disciplines and examine three real-world use cases: pandemic response, self-driving car design, and climate change adaptation, drawing expertise from healthcare, social science, engineering, science, sustainability, and finance. By fostering multidisciplinary dialogue and open research practices, our community can accelerate deployment-centric development for broad societal impact.
Divide and Conquer Self-Supervised Learning for High-Content Imaging
Mar 10, 2025



Self-supervised representation learning methods often fail to learn subtle or complex features, which can be dominated by simpler patterns which are much easier to learn. This limitation is particularly problematic in applications to science and engineering, as complex features can be critical for discovery and analysis. To address this, we introduce Split Component Embedding Registration (SpliCER), a novel architecture which splits the image into sections and distils information from each section to guide the model to learn more subtle and complex features without compromising on simpler features. SpliCER is compatible with any self-supervised loss function and can be integrated into existing methods without modification. The primary contributions of this work are as follows: i) we demonstrate that existing self-supervised methods can learn shortcut solutions when simple and complex features are both present; ii) we introduce a novel self-supervised training method, SpliCER, to overcome the limitations of existing methods, and achieve significant downstream performance improvements; iii) we demonstrate the effectiveness of SpliCER in cutting-edge medical and geospatial imaging settings. SpliCER offers a powerful new tool for representation learning, enabling models to uncover complex features which could be overlooked by other methods.
Synthetic Privileged Information Enhances Medical Image Representation Learning
Mar 08, 2024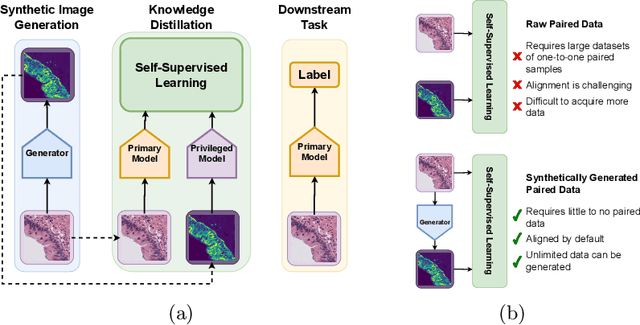
Multimodal self-supervised representation learning has consistently proven to be a highly effective method in medical image analysis, offering strong task performance and producing biologically informed insights. However, these methods heavily rely on large, paired datasets, which is prohibitive for their use in scenarios where paired data does not exist, or there is only a small amount available. In contrast, image generation methods can work well on very small datasets, and can find mappings between unpaired datasets, meaning an effectively unlimited amount of paired synthetic data can be generated. In this work, we demonstrate that representation learning can be significantly improved by synthetically generating paired information, both compared to training on either single-modality (up to 4.4x error reduction) or authentic multi-modal paired datasets (up to 5.6x error reduction).
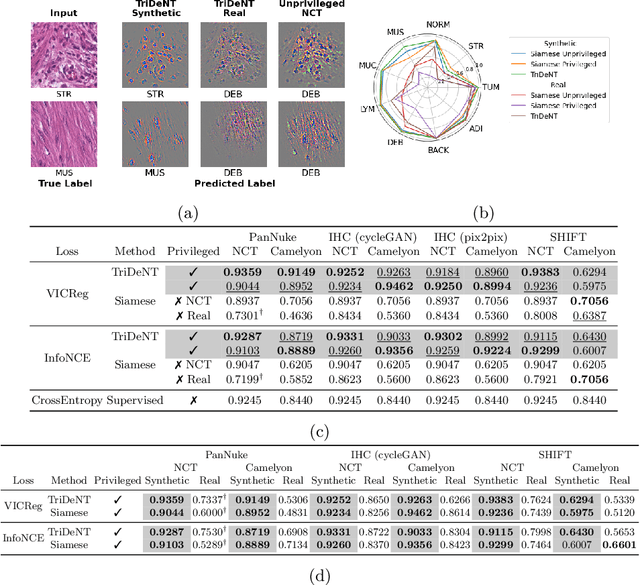
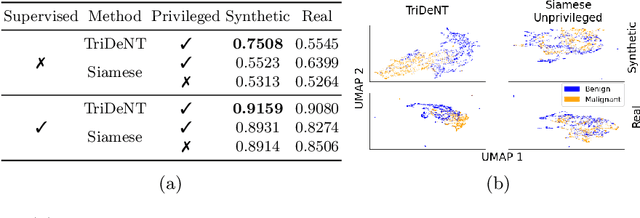
TriDeNT: Triple Deep Network Training for Privileged Knowledge Distillation in Histopathology
Dec 05, 2023Computational pathology models rarely utilise data that will not be available for inference. This means most models cannot learn from highly informative data such as additional immunohistochemical (IHC) stains and spatial transcriptomics. We present TriDeNT, a novel self-supervised method for utilising privileged data that is not available during inference to improve performance. We demonstrate the efficacy of this method for a range of different paired data including immunohistochemistry, spatial transcriptomics and expert nuclei annotations. In all settings, TriDeNT outperforms other state-of-the-art methods in downstream tasks, with observed improvements of up to 101%. Furthermore, we provide qualitative and quantitative measurements of the features learned by these models and how they differ from baselines. TriDeNT offers a novel method to distil knowledge from scarce or costly data during training, to create significantly better models for routine inputs.
More From Less: Self-Supervised Knowledge Distillation for Information-Sparse Histopathology Data
Mar 19, 2023Medical imaging technologies are generating increasingly large amounts of high-quality, information-dense data. Despite the progress, practical use of advanced imaging technologies for research and diagnosis remains limited by cost and availability, so information-sparse data such as H\&E stains are relied on in practice. The study of diseased tissue requires methods which can leverage these information-dense data to extract more value from routine, information-sparse data. Using self-supervised deep learning, we demonstrate that it is possible to distil knowledge during training from information-dense data into models which only require information-sparse data for inference. This improves downstream classification accuracy on information-sparse data, making it comparable with the fully-supervised baseline. We find substantial effects on the learned representations, and this training process identifies subtle features which otherwise go undetected. This approach enables the design of models which require only routine images, but contain insights from state-of-the-art data, allowing better use of the available resources.