 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Privileged Information Enhances Medical Image Representation Learning
Mar 08, 2024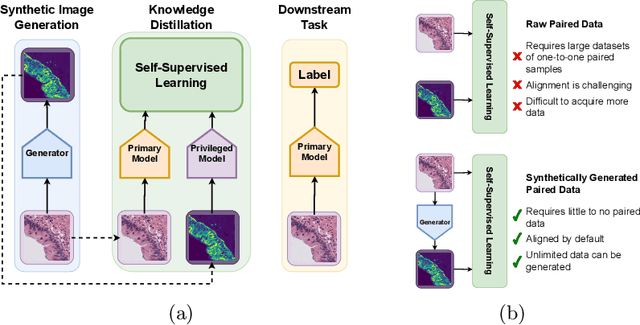
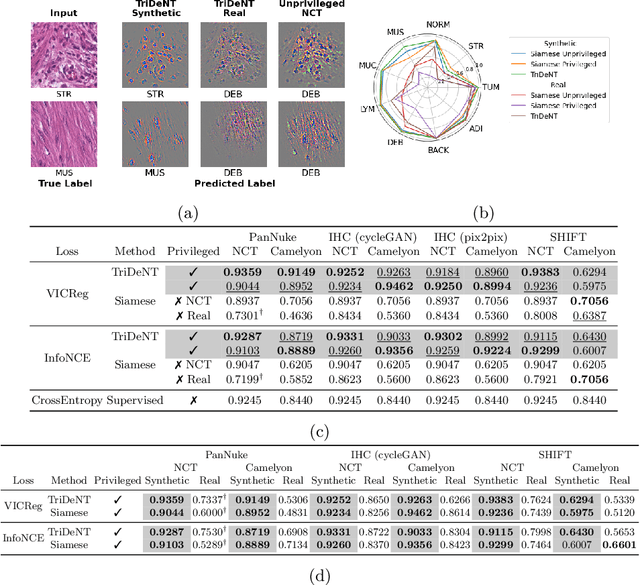
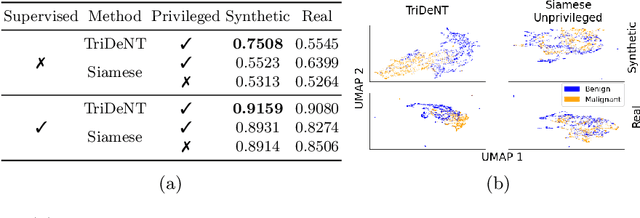
Multimodal self-supervised representation learning has consistently proven to be a highly effective method in medical image analysis, offering strong task performance and producing biologically informed insights. However, these methods heavily rely on large, paired datasets, which is prohibitive for their use in scenarios where paired data does not exist, or there is only a small amount available. In contrast, image generation methods can work well on very small datasets, and can find mappings between unpaired datasets, meaning an effectively unlimited amount of paired synthetic data can be generated. In this work, we demonstrate that representation learning can be significantly improved by synthetically generating paired information, both compared to training on either single-modality (up to 4.4x error reduction) or authentic multi-modal paired datasets (up to 5.6x error reduction).
2020 CATARACTS Semantic Segmentation Challenge
Oct 21, 2021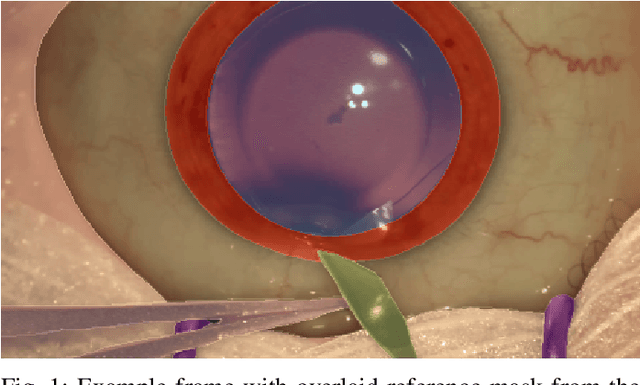
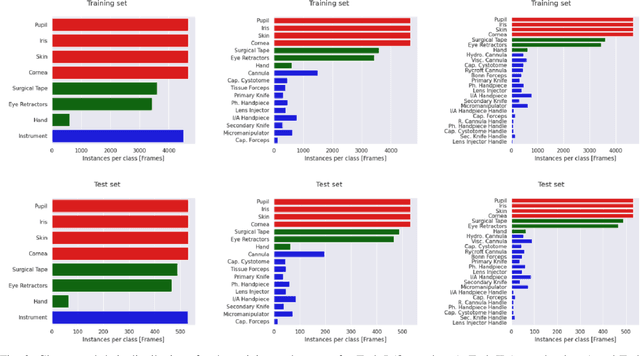
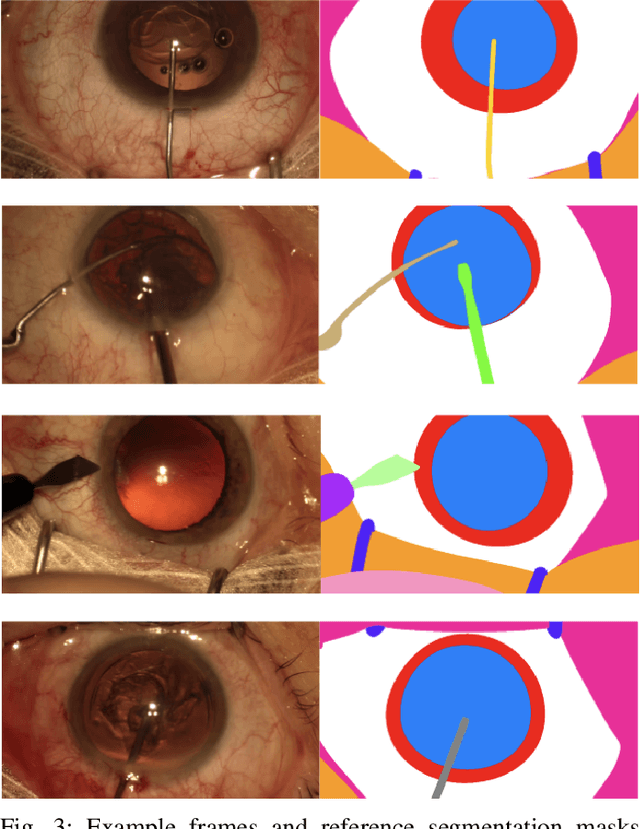
Surgical scene segmentation is essential for anatomy and instrument localization which can be further used to assess tissue-instrument interactions during a surgical procedure. In 2017, the Challenge on Automatic Tool Annotation for cataRACT Surgery (CATARACTS) released 50 cataract surgery videos accompanied by instrument usage annotations. These annotations included frame-level instrument presence information. In 2020, we released pixel-wise semantic annotations for anatomy and instruments for 4670 images sampled from 25 videos of the CATARACTS training set. The 2020 CATARACTS Semantic Segmentation Challenge, which was a sub-challenge of the 2020 MICCAI Endoscopic Vision (EndoVis) Challenge, presented three sub-tasks to assess participating solutions on anatomical structure and instrument segmentation. Their performance was assessed on a hidden test set of 531 images from 10 videos of the CATARACTS test set.