 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Mixing Approach for Detecting Intraoperative Adverse Events in Laparoscopic Roux-en-Y Gastric Bypass Surgery
Apr 23, 2025Intraoperative adverse events (IAEs), such as bleeding or thermal injury, can lead to severe postoperative complications if undetected. However, their rarity results in highly imbalanced datasets, posing challenges for AI-based detection and severity quantification. We propose BetaMixer, a novel deep learning model that addresses these challenges through a Beta distribution-based mixing approach, converting discrete IAE severity scores into continuous values for precise severity regression (0-5 scale). BetaMixer employs Beta distribution-based sampling to enhance underrepresented classes and regularizes intermediate embeddings to maintain a structured feature space. A generative approach aligns the feature space with sampled IAE severity, enabling robust classification and severity regression via a transformer. Evaluated on the MultiBypass140 dataset, which we extended with IAE labels, BetaMixer achieves a weighted F1 score of 0.76, recall of 0.81, PPV of 0.73, and NPV of 0.84, demonstrating strong performance on imbalanced data. By integrating Beta distribution-based sampling, feature mixing, and generative modeling, BetaMixer offers a robust solution for IAE detection and quantification in clinical settings.
CoSimGen: Controllable Diffusion Model for Simultaneous Image and Mask Generation
Mar 25, 2025The acquisition of annotated datasets with paired images and segmentation masks is a critical challenge in domains such as medical imaging, remote sensing, and computer vision. Manual annotation demands significant resources, faces ethical constraints, and depends heavily on domain expertise. Existing generative models often target single-modality outputs, either images or segmentation masks, failing to address the need for high-quality, simultaneous image-mask generation. Additionally, these models frequently lack adaptable conditioning mechanisms, restricting control over the generated outputs and limiting their applicability for dataset augmentation and rare scenario simulation. We propose CoSimGen, a diffusion-based framework for controllable simultaneous image and mask generation. Conditioning is intuitively achieved through (1) text prompts grounded in class semantics, (2) spatial embedding of context prompts to provide spatial coherence, and (3) spectral embedding of timestep information to model noise levels during diffusion. To enhance controllability and training efficiency, the framework incorporates contrastive triplet loss between text and class embeddings, alongside diffusion and adversarial losses. Initial low-resolution outputs 128 x 128 are super-resolved to 512 x 512, producing high-fidelity images and masks with strict adherence to conditions. We evaluate CoSimGen on metrics such as FID, KID, LPIPS, Class FID, Positive predicted value for image fidelity and semantic alignment of generated samples over 4 diverse datasets. CoSimGen achieves state-of-the-art performance across all datasets, achieving the lowest KID of 0.11 and LPIPS of 0.53 across datasets.
SimGen: A Diffusion-Based Framework for Simultaneous Surgical Image and Segmentation Mask Generation
Jan 15, 2025



Acquiring and annotating surgical data is often resource-intensive, ethical constraining, and requiring significant expert involvement. While generative AI models like text-to-image can alleviate data scarcity, incorporating spatial annotations, such as segmentation masks, is crucial for precision-driven surgical applications, simulation, and education. This study introduces both a novel task and method, SimGen, for Simultaneous Image and Mask Generation. SimGen is a diffusion model based on the DDPM framework and Residual U-Net, designed to jointly generate high-fidelity surgical images and their corresponding segmentation masks. The model leverages cross-correlation priors to capture dependencies between continuous image and discrete mask distributions. Additionally, a Canonical Fibonacci Lattice (CFL) is employed to enhance class separability and uniformity in the RGB space of the masks. SimGen delivers high-fidelity images and accurate segmentation masks, outperforming baselines across six public datasets assessed on image and semantic inception distance metrics. Ablation study shows that the CFL improves mask quality and spatial separation. Downstream experiments suggest generated image-mask pairs are usable if regulations limit human data release for research. This work offers a cost-effective solution for generating paired surgical images and complex labels, advancing surgical AI development by reducing the need for expensive manual annotations.
Surgical Text-to-Image Generation
Jul 12, 2024



Acquiring surgical data for research and development is significantly hindered by high annotation costs and practical and ethical constraints. Utilizing synthetically generated images could offer a valuable alternative. In this work, we conduct an in-depth analysis on adapting text-to-image generative models for the surgical domain, leveraging the CholecT50 dataset, which provides surgical images annotated with surgical action triplets (instrument, verb, target). We investigate various language models and find T5 to offer more distinct features for differentiating surgical actions based on triplet-based textual inputs. Our analysis demonstrates strong alignment between long and triplet-based captions, supporting the use of triplet-based labels. We address the challenges in training text-to-image models on triplet-based captions without additional input signals by uncovering that triplet text embeddings are instrument-centric in the latent space and then, by designing an instrument-based class balancing technique to counteract the imbalance and skewness in the surgical data, improving training convergence. Extending Imagen, a diffusion-based generative model, we develop Surgical Imagen to generate photorealistic and activity-aligned surgical images from triplet-based textual prompts. We evaluate our model using diverse metrics, including human expert surveys and automated methods like FID and CLIP scores. We assess the model performance on key aspects: quality, alignment, reasoning, knowledge, and robustness, demonstrating the effectiveness of our approach in providing a realistic alternative to real data collection.
SurgiTrack: Fine-Grained Multi-Class Multi-Tool Tracking in Surgical Videos
May 30, 2024

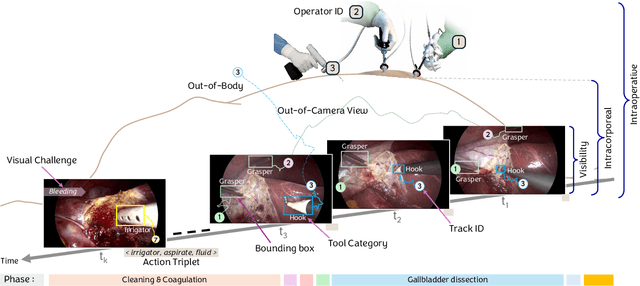

Accurate tool tracking is essential for the success of computer-assisted intervention. Previous efforts often modeled tool trajectories rigidly, overlooking the dynamic nature of surgical procedures, especially tracking scenarios like out-of-body and out-of-camera views. Addressing this limitation, the new CholecTrack20 dataset provides detailed labels that account for multiple tool trajectories in three perspectives: (1) intraoperative, (2) intracorporeal, and (3) visibility, representing the different types of temporal duration of tool tracks. These fine-grained labels enhance tracking flexibility but also increase the task complexity. Re-identifying tools after occlusion or re-insertion into the body remains challenging due to high visual similarity, especially among tools of the same category. This work recognizes the critical role of the tool operators in distinguishing tool track instances, especially those belonging to the same tool category. The operators' information are however not explicitly captured in surgical videos. We therefore propose SurgiTrack, a novel deep learning method that leverages YOLOv7 for precise tool detection and employs an attention mechanism to model the originating direction of the tools, as a proxy to their operators, for tool re-identification. To handle diverse tool trajectory perspectives, SurgiTrack employs a harmonizing bipartite matching graph, minimizing conflicts and ensuring accurate tool identity association. Experimental results on CholecTrack20 demonstrate SurgiTrack's effectiveness, outperforming baselines and state-of-the-art methods with real-time inference capability. This work sets a new standard in surgical tool tracking, providing dynamic trajectories for more adaptable and precise assistance in minimally invasive surgeries.
CholecTrack20: A Dataset for Multi-Class Multiple Tool Tracking in Laparoscopic Surgery
Dec 12, 2023Tool tracking in surgical videos is vital in computer-assisted intervention for tasks like surgeon skill assessment, safety zone estimation, and human-machine collaboration during minimally invasive procedures. The lack of large-scale datasets hampers Artificial Intelligence implementation in this domain. Current datasets exhibit overly generic tracking formalization, often lacking surgical context: a deficiency that becomes evident when tools move out of the camera's scope, resulting in rigid trajectories that hinder realistic surgical representation. This paper addresses the need for a more precise and adaptable tracking formalization tailored to the intricacies of endoscopic procedures by introducing CholecTrack20, an extensive dataset meticulously annotated for multi-class multi-tool tracking across three perspectives representing the various ways of considering the temporal duration of a tool trajectory: (1) intraoperative, (2) intracorporeal, and (3) visibility within the camera's scope. The dataset comprises 20 laparoscopic videos with over 35,000 frames and 65,000 annotated tool instances with details on spatial location, category, identity, operator, phase, and surgical visual conditions. This detailed dataset caters to the evolving assistive requirements within a procedure.
Surgical Action Triplet Detection by Mixed Supervised Learning of Instrument-Tissue Interactions
Jul 18, 2023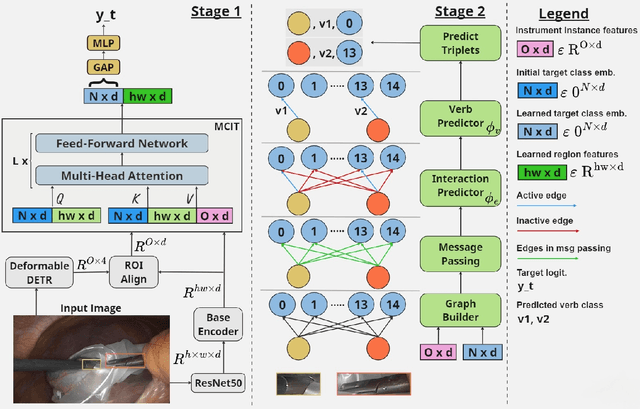

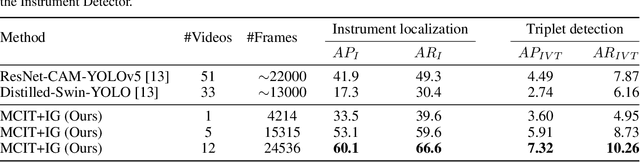

Surgical action triplets describe instrument-tissue interactions as (instrument, verb, target) combinations, thereby supporting a detailed analysis of surgical scene activities and workflow. This work focuses on surgical action triplet detection, which is challenging but more precise than the traditional triplet recognition task as it consists of joint (1) localization of surgical instruments and (2) recognition of the surgical action triplet associated with every localized instrument. Triplet detection is highly complex due to the lack of spatial triplet annotation. We analyze how the amount of instrument spatial annotations affects triplet detection and observe that accurate instrument localization does not guarantee better triplet detection due to the risk of erroneous associations with the verbs and targets. To solve the two tasks, we propose MCIT-IG, a two-stage network, that stands for Multi-Class Instrument-aware Transformer-Interaction Graph. The MCIT stage of our network models per class embedding of the targets as additional features to reduce the risk of misassociating triplets. Furthermore, the IG stage constructs a bipartite dynamic graph to model the interaction between the instruments and targets, cast as the verbs. We utilize a mixed-supervised learning strategy that combines weak target presence labels for MCIT and pseudo triplet labels for IG to train our network. We observed that complementing minimal instrument spatial annotations with target embeddings results in better triplet detection. We evaluate our model on the CholecT50 dataset and show improved performance on both instrument localization and triplet detection, topping the leaderboard of the CholecTriplet challenge in MICCAI 2022.
CholecTriplet2022: Show me a tool and tell me the triplet -- an endoscopic vision challenge for surgical action triplet detection
Feb 13, 2023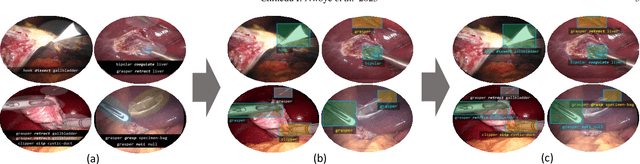
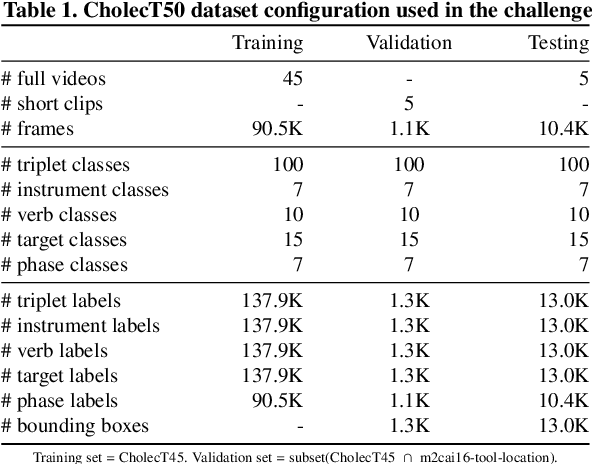
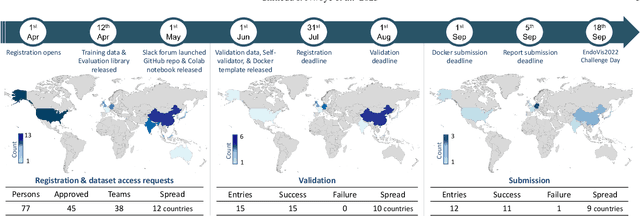
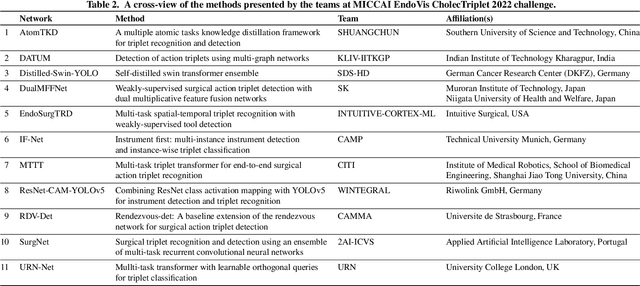
Formalizing surgical activities as triplets of the used instruments, actions performed, and target anatomies is becoming a gold standard approach for surgical activity modeling. The benefit is that this formalization helps to obtain a more detailed understanding of tool-tissue interaction which can be used to develop better Artificial Intelligence assistance for image-guided surgery. Earlier efforts and the CholecTriplet challenge introduced in 2021 have put together techniques aimed at recognizing these triplets from surgical footage. Estimating also the spatial locations of the triplets would offer a more precise intraoperative context-aware decision support for computer-assisted intervention. This paper presents the CholecTriplet2022 challenge, which extends surgical action triplet modeling from recognition to detection. It includes weakly-supervised bounding box localization of every visible surgical instrument (or tool), as the key actors, and the modeling of each tool-activity in the form of <instrument, verb, target> triplet. The paper describes a baseline method and 10 new deep learning algorithms presented at the challenge to solve the task. It also provides thorough methodological comparisons of the methods, an in-depth analysis of the obtained results, their significance, and useful insights for future research directions and applications in surgery.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
Rendezvous in Time: An Attention-based Temporal Fusion approach for Surgical Triplet Recognition
Nov 30, 2022One of the recent advances in surgical AI is the recognition of surgical activities as triplets of (instrument, verb, target). Albeit providing detailed information for computer-assisted intervention, current triplet recognition approaches rely only on single frame features. Exploiting the temporal cues from earlier frames would improve the recognition of surgical action triplets from videos. In this paper, we propose Rendezvous in Time (RiT) - a deep learning model that extends the state-of-the-art model, Rendezvous, with temporal modeling. Focusing more on the verbs, our RiT explores the connectedness of current and past frames to learn temporal attention-based features for enhanced triplet recognition. We validate our proposal on the challenging surgical triplet dataset, CholecT45, demonstrating an improved recognition of the verb and triplet along with other interactions involving the verb such as (instrument, verb). Qualitative results show that the RiT produces smoother predictions for most triplet instances than the state-of-the-arts. We present a novel attention-based approach that leverages the temporal fusion of video frames to model the evolution of surgical actions and exploit their benefits for surgical triplet recognition.