 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Mixing Approach for Detecting Intraoperative Adverse Events in Laparoscopic Roux-en-Y Gastric Bypass Surgery
Apr 23, 2025Intraoperative adverse events (IAEs), such as bleeding or thermal injury, can lead to severe postoperative complications if undetected. However, their rarity results in highly imbalanced datasets, posing challenges for AI-based detection and severity quantification. We propose BetaMixer, a novel deep learning model that addresses these challenges through a Beta distribution-based mixing approach, converting discrete IAE severity scores into continuous values for precise severity regression (0-5 scale). BetaMixer employs Beta distribution-based sampling to enhance underrepresented classes and regularizes intermediate embeddings to maintain a structured feature space. A generative approach aligns the feature space with sampled IAE severity, enabling robust classification and severity regression via a transformer. Evaluated on the MultiBypass140 dataset, which we extended with IAE labels, BetaMixer achieves a weighted F1 score of 0.76, recall of 0.81, PPV of 0.73, and NPV of 0.84, demonstrating strong performance on imbalanced data. By integrating Beta distribution-based sampling, feature mixing, and generative modeling, BetaMixer offers a robust solution for IAE detection and quantification in clinical settings.
CoSimGen: Controllable Diffusion Model for Simultaneous Image and Mask Generation
Mar 25, 2025The acquisition of annotated datasets with paired images and segmentation masks is a critical challenge in domains such as medical imaging, remote sensing, and computer vision. Manual annotation demands significant resources, faces ethical constraints, and depends heavily on domain expertise. Existing generative models often target single-modality outputs, either images or segmentation masks, failing to address the need for high-quality, simultaneous image-mask generation. Additionally, these models frequently lack adaptable conditioning mechanisms, restricting control over the generated outputs and limiting their applicability for dataset augmentation and rare scenario simulation. We propose CoSimGen, a diffusion-based framework for controllable simultaneous image and mask generation. Conditioning is intuitively achieved through (1) text prompts grounded in class semantics, (2) spatial embedding of context prompts to provide spatial coherence, and (3) spectral embedding of timestep information to model noise levels during diffusion. To enhance controllability and training efficiency, the framework incorporates contrastive triplet loss between text and class embeddings, alongside diffusion and adversarial losses. Initial low-resolution outputs 128 x 128 are super-resolved to 512 x 512, producing high-fidelity images and masks with strict adherence to conditions. We evaluate CoSimGen on metrics such as FID, KID, LPIPS, Class FID, Positive predicted value for image fidelity and semantic alignment of generated samples over 4 diverse datasets. CoSimGen achieves state-of-the-art performance across all datasets, achieving the lowest KID of 0.11 and LPIPS of 0.53 across datasets.
SimGen: A Diffusion-Based Framework for Simultaneous Surgical Image and Segmentation Mask Generation
Jan 15, 2025



Acquiring and annotating surgical data is often resource-intensive, ethical constraining, and requiring significant expert involvement. While generative AI models like text-to-image can alleviate data scarcity, incorporating spatial annotations, such as segmentation masks, is crucial for precision-driven surgical applications, simulation, and education. This study introduces both a novel task and method, SimGen, for Simultaneous Image and Mask Generation. SimGen is a diffusion model based on the DDPM framework and Residual U-Net, designed to jointly generate high-fidelity surgical images and their corresponding segmentation masks. The model leverages cross-correlation priors to capture dependencies between continuous image and discrete mask distributions. Additionally, a Canonical Fibonacci Lattice (CFL) is employed to enhance class separability and uniformity in the RGB space of the masks. SimGen delivers high-fidelity images and accurate segmentation masks, outperforming baselines across six public datasets assessed on image and semantic inception distance metrics. Ablation study shows that the CFL improves mask quality and spatial separation. Downstream experiments suggest generated image-mask pairs are usable if regulations limit human data release for research. This work offers a cost-effective solution for generating paired surgical images and complex labels, advancing surgical AI development by reducing the need for expensive manual annotations.
Surgical Text-to-Image Generation
Jul 12, 2024



Acquiring surgical data for research and development is significantly hindered by high annotation costs and practical and ethical constraints. Utilizing synthetically generated images could offer a valuable alternative. In this work, we conduct an in-depth analysis on adapting text-to-image generative models for the surgical domain, leveraging the CholecT50 dataset, which provides surgical images annotated with surgical action triplets (instrument, verb, target). We investigate various language models and find T5 to offer more distinct features for differentiating surgical actions based on triplet-based textual inputs. Our analysis demonstrates strong alignment between long and triplet-based captions, supporting the use of triplet-based labels. We address the challenges in training text-to-image models on triplet-based captions without additional input signals by uncovering that triplet text embeddings are instrument-centric in the latent space and then, by designing an instrument-based class balancing technique to counteract the imbalance and skewness in the surgical data, improving training convergence. Extending Imagen, a diffusion-based generative model, we develop Surgical Imagen to generate photorealistic and activity-aligned surgical images from triplet-based textual prompts. We evaluate our model using diverse metrics, including human expert surveys and automated methods like FID and CLIP scores. We assess the model performance on key aspects: quality, alignment, reasoning, knowledge, and robustness, demonstrating the effectiveness of our approach in providing a realistic alternative to real data collection.
Two Headed Dragons: Multimodal Fusion and Cross Modal Transactions
Jul 24, 2021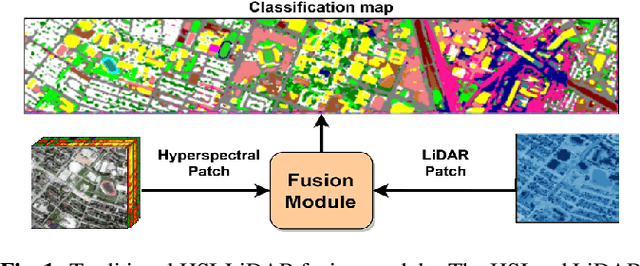
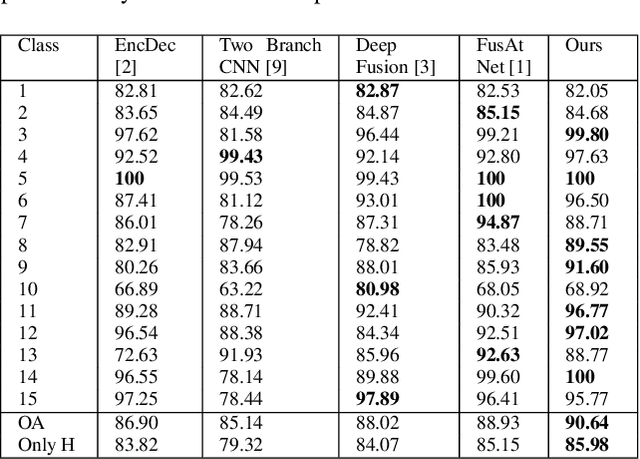
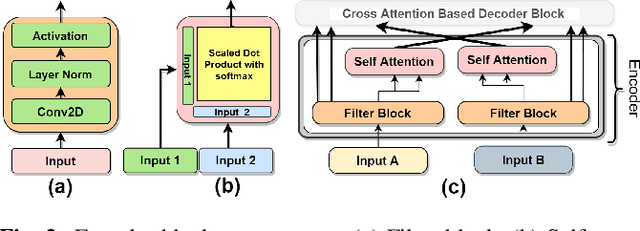
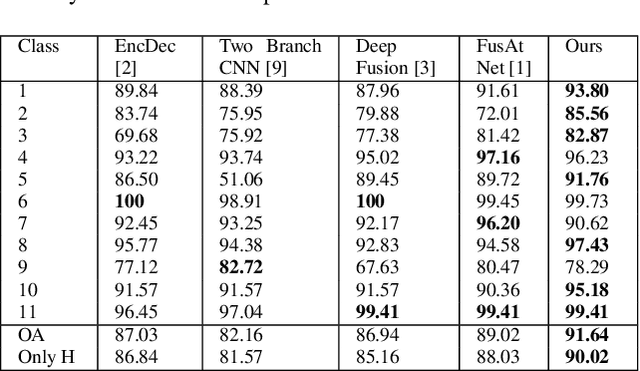
As the field of remote sensing is evolving, we witness the accumulation of information from several modalities, such as multispectral (MS), hyperspectral (HSI), LiDAR etc. Each of these modalities possess its own distinct characteristics and when combined synergistically, perform very well in the recognition and classification tasks. However, fusing multiple modalities in remote sensing is cumbersome due to highly disparate domains. Furthermore, the existing methods do not facilitate cross-modal interactions. To this end, we propose a novel transformer based fusion method for HSI and LiDAR modalities. The model is composed of stacked auto encoders that harness the cross key-value pairs for HSI and LiDAR, thus establishing a communication between the two modalities, while simultaneously using the CNNs to extract the spectral and spatial information from HSI and LiDAR. We test our model on Houston (Data Fusion Contest - 2013) and MUUFL Gulfport datasets and achieve competitive results.