 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlant detection from ultra high resolution remote sensing images: A Semantic Segmentation approach based on fuzzy loss
Aug 31, 2024



In this study, we tackle the challenge of identifying plant species from ultra high resolution (UHR) remote sensing images. Our approach involves introducing an RGB remote sensing dataset, characterized by millimeter-level spatial resolution, meticulously curated through several field expeditions across a mountainous region in France covering various landscapes. The task of plant species identification is framed as a semantic segmentation problem for its practical and efficient implementation across vast geographical areas. However, when dealing with segmentation masks, we confront instances where distinguishing boundaries between plant species and their background is challenging. We tackle this issue by introducing a fuzzy loss within the segmentation model. Instead of utilizing one-hot encoded ground truth (GT), our model incorporates Gaussian filter refined GT, introducing stochasticity during training. First experimental results obtained on both our UHR dataset and a public dataset are presented, showing the relevance of the proposed methodology, as well as the need for future improvement.
Mapping earth mounds from space
Aug 31, 2024Regular patterns of vegetation are considered widespread landscapes, although their global extent has never been estimated. Among them, spotted landscapes are of particular interest in the context of climate change. Indeed, regularly spaced vegetation spots in semi-arid shrublands result from extreme resource depletion and prefigure catastrophic shift of the ecosystem to a homogeneous desert, while termite mounds also producing spotted landscapes were shown to increase robustness to climate change. Yet, their identification at large scale calls for automatic methods, for instance using the popular deep learning framework, able to cope with a vast amount of remote sensing data, e.g., optical satellite imagery. In this paper, we tackle this problem and benchmark some state-of-the-art deep networks on several landscapes and geographical areas. Despite the promising results we obtained, we found that more research is needed to be able to map automatically these earth mounds from space.
Hyperspectral Image Analysis in Single-Modal and Multimodal setting using Deep Learning Techniques
Mar 03, 2024



Hyperspectral imaging provides precise classification for land use and cover due to its exceptional spectral resolution. However, the challenges of high dimensionality and limited spatial resolution hinder its effectiveness. This study addresses these challenges by employing deep learning techniques to efficiently process, extract features, and classify data in an integrated manner. To enhance spatial resolution, we integrate information from complementary modalities such as LiDAR and SAR data through multimodal learning. Moreover, adversarial learning and knowledge distillation are utilized to overcome issues stemming from domain disparities and missing modalities. We also tailor deep learning architectures to suit the unique characteristics of HSI data, utilizing 1D convolutional and recurrent neural networks to handle its continuous spectral dimension. Techniques like visual attention and feedback connections within the architecture bolster the robustness of feature extraction. Additionally, we tackle the issue of limited training samples through self-supervised learning methods, employing autoencoders for dimensionality reduction and exploring semi-supervised learning techniques that leverage unlabeled data. Our proposed approaches are evaluated across various HSI datasets, consistently outperforming existing state-of-the-art techniques.
Land use/land cover classification of fused Sentinel-1 and Sentinel-2 imageries using ensembles of Random Forests
Dec 19, 2023The study explores the synergistic combination of Synthetic Aperture Radar (SAR) and Visible-Near Infrared-Short Wave Infrared (VNIR-SWIR) imageries for land use/land cover (LULC) classification. Image fusion, employing Bayesian fusion, merges SAR texture bands with VNIR-SWIR imageries. The research aims to investigate the impact of this fusion on LULC classification. Despite the popularity of random forests for supervised classification, their limitations, such as suboptimal performance with fewer features and accuracy stagnation, are addressed. To overcome these issues, ensembles of random forests (RFE) are created, introducing random rotations using the Forest-RC algorithm. Three rotation approaches: principal component analysis (PCA), sparse random rotation (SRP) matrix, and complete random rotation (CRP) matrix are employed. Sentinel-1 SAR data and Sentinel-2 VNIR-SWIR data from the IIT-Kanpur region constitute the training datasets, including SAR, SAR with texture, VNIR-SWIR, VNIR-SWIR with texture, and fused VNIR-SWIR with texture. The study evaluates classifier efficacy, explores the impact of SAR and VNIR-SWIR fusion on classification, and significantly enhances the execution speed of Bayesian fusion code. The SRP-based RFE outperforms other ensembles for the first two datasets, yielding average overall kappa values of 61.80% and 68.18%, while the CRP-based RFE excels for the last three datasets with average overall kappa values of 95.99%, 96.93%, and 96.30%. The fourth dataset achieves the highest overall kappa of 96.93%. Furthermore, incorporating texture with SAR bands results in a maximum overall kappa increment of 10.00%, while adding texture to VNIR-SWIR bands yields a maximum increment of approximately 3.45%.
Visual Question Answering in Remote Sensing with Cross-Attention and Multimodal Information Bottleneck
Jun 25, 2023



In this research, we deal with the problem of visual question answering (VQA) in remote sensing. While remotely sensed images contain information significant for the task of identification and object detection, they pose a great challenge in their processing because of high dimensionality, volume and redundancy. Furthermore, processing image information jointly with language features adds additional constraints, such as mapping the corresponding image and language features. To handle this problem, we propose a cross attention based approach combined with information maximization. The CNN-LSTM based cross-attention highlights the information in the image and language modalities and establishes a connection between the two, while information maximization learns a low dimensional bottleneck layer, that has all the relevant information required to carry out the VQA task. We evaluate our method on two VQA remote sensing datasets of different resolutions. For the high resolution dataset, we achieve an overall accuracy of 79.11% and 73.87% for the two test sets while for the low resolution dataset, we achieve an overall accuracy of 85.98%.
Semi-Supervised Learning for hyperspectral images by non parametrically predicting view assignment
Jun 19, 2023Hyperspectral image (HSI) classification is gaining a lot of momentum in present time because of high inherent spectral information within the images. However, these images suffer from the problem of curse of dimensionality and usually require a large number samples for tasks such as classification, especially in supervised setting. Recently, to effectively train the deep learning models with minimal labelled samples, the unlabeled samples are also being leveraged in self-supervised and semi-supervised setting. In this work, we leverage the idea of semi-supervised learning to assist the discriminative self-supervised pretraining of the models. The proposed method takes different augmented views of the unlabeled samples as input and assigns them the same pseudo-label corresponding to the labelled sample from the downstream task. We train our model on two HSI datasets, namely Houston dataset (from data fusion contest, 2013) and Pavia university dataset, and show that the proposed approach performs better than self-supervised approach and supervised training.
RSINet: Inpainting Remotely Sensed Images Using Triple GAN Framework
Feb 12, 2022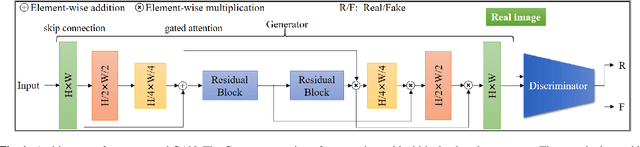
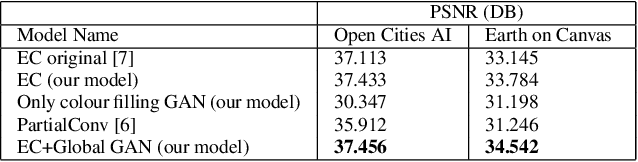
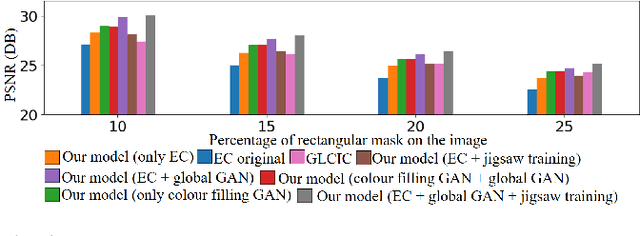

We tackle the problem of image inpainting in the remote sensing domain. Remote sensing images possess high resolution and geographical variations, that render the conventional inpainting methods less effective. This further entails the requirement of models with high complexity to sufficiently capture the spectral, spatial and textural nuances within an image, emerging from its high spatial variability. To this end, we propose a novel inpainting method that individually focuses on each aspect of an image such as edges, colour and texture using a task specific GAN. Moreover, each individual GAN also incorporates the attention mechanism that explicitly extracts the spectral and spatial features. To ensure consistent gradient flow, the model uses residual learning paradigm, thus simultaneously working with high and low level features. We evaluate our model, alongwith previous state of the art models, on the two well known remote sensing datasets, Open Cities AI and Earth on Canvas, and achieve competitive performance.
Two Headed Dragons: Multimodal Fusion and Cross Modal Transactions
Jul 24, 2021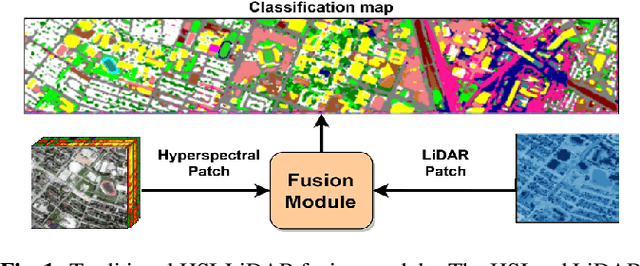
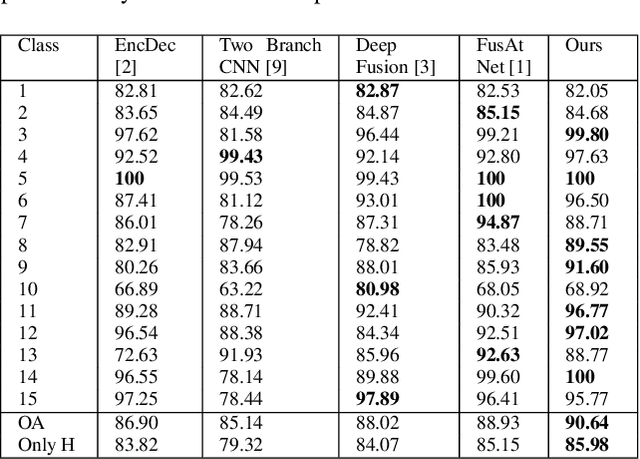
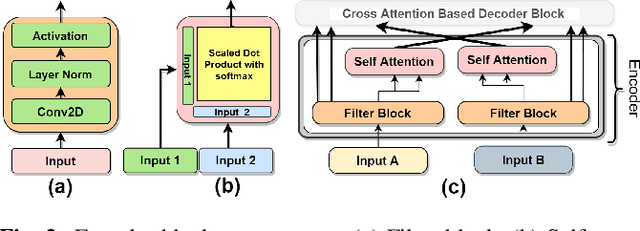
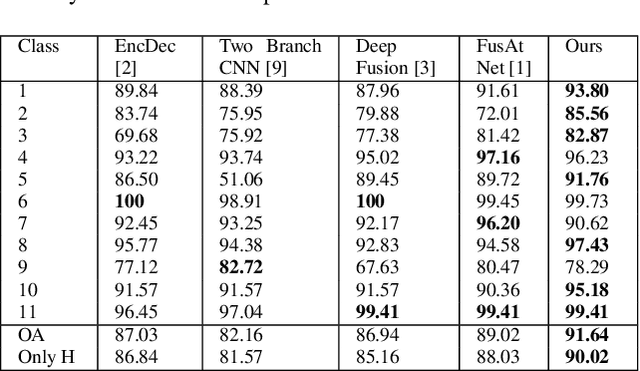
As the field of remote sensing is evolving, we witness the accumulation of information from several modalities, such as multispectral (MS), hyperspectral (HSI), LiDAR etc. Each of these modalities possess its own distinct characteristics and when combined synergistically, perform very well in the recognition and classification tasks. However, fusing multiple modalities in remote sensing is cumbersome due to highly disparate domains. Furthermore, the existing methods do not facilitate cross-modal interactions. To this end, we propose a novel transformer based fusion method for HSI and LiDAR modalities. The model is composed of stacked auto encoders that harness the cross key-value pairs for HSI and LiDAR, thus establishing a communication between the two modalities, while simultaneously using the CNNs to extract the spectral and spatial information from HSI and LiDAR. We test our model on Houston (Data Fusion Contest - 2013) and MUUFL Gulfport datasets and achieve competitive results.