 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectralEarth-FM: Bringing Hyperspectral Imagery into Multimodal Earth Observation Pretraining
May 20, 2026Earth observation (EO) foundation models (FMs) are increasingly trained on multisensor data, spanning multispectral imagery (MSI), synthetic aperture radar (SAR), and derived geospatial layers, but hyperspectral imagery (HSI) remains underrepresented. Conversely, existing hyperspectral FMs are trained on HSI alone, leaving joint pretraining and fusion of HSI with co-located EO sensors unexplored. We introduce SpectralEarth-FM, a hierarchical transformer for multisensor EO input with heterogeneous spectral dimensionality. The architecture combines spectral tokenization for hyperspectral inputs, sensor-specific encoders, a cross-sensor fusion module, and a shared hierarchical encoder, enabling joint processing of HSI and lower-channel observations. To pretrain SpectralEarth-FM, we curate SpectralEarth-MM, a dataset that co-locates HSI from three spaceborne sensors (EnMAP, EMIT, DESIS) with Sentinel-2, Landsat-8/9 optical imagery, Landsat land surface temperature (LST), and Sentinel-1 SAR, over common geographic footprints. It comprises approximately 2M globally distributed locations, 25M georeferenced patches, and over 40TB of data. Pretraining uses a Joint-Embedding Predictive Architecture (JEPA)-style objective that matches representations between global views and single-sensor local views from the same location. We evaluate SpectralEarth-FM on hyperspectral downstream tasks and standard EO benchmarks following the PANGAEA protocol, achieving state-of-the-art results across both evaluation settings.
Data-Centric Benchmark for Label Noise Estimation and Ranking in Remote Sensing Image Segmentation
Feb 28, 2026High-quality pixel-level annotations are essential for the semantic segmentation of remote sensing imagery. However, such labels are expensive to obtain and often affected by noise due to the labor-intensive and time-consuming nature of pixel-wise annotation, which makes it challenging for human annotators to label every pixel accurately. Annotation errors can significantly degrade the performance and robustness of modern segmentation models, motivating the need for reliable mechanisms to identify and quantify noisy training samples. This paper introduces a novel Data-Centric benchmark, together with a novel, publicly available dataset and two techniques for identifying, quantifying, and ranking training samples according to their level of label noise in remote sensing semantic segmentation. Such proposed methods leverage complementary strategies based on model uncertainty, prediction consistency, and representation analysis, and consistently outperform established baselines across a range of experimental settings. The outcomes of this work are publicly available at https://github.com/keillernogueira/label_noise_segmentation.
HyBiomass: Global Hyperspectral Imagery Benchmark Dataset for Evaluating Geospatial Foundation Models in Forest Aboveground Biomass Estimation
Jun 12, 2025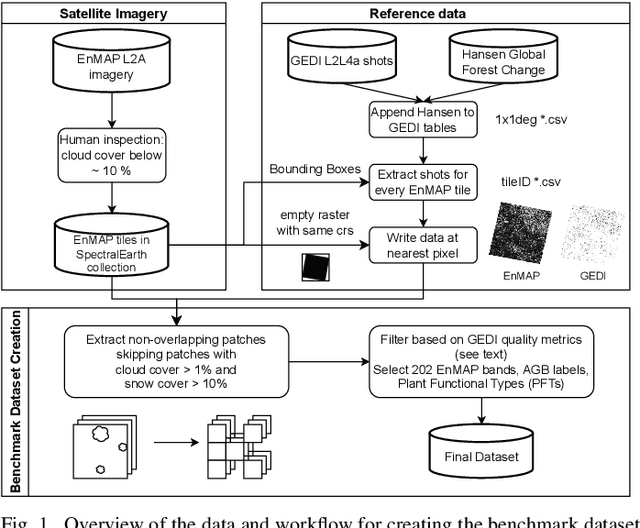
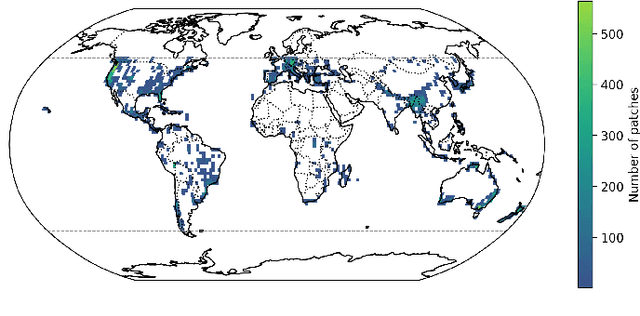
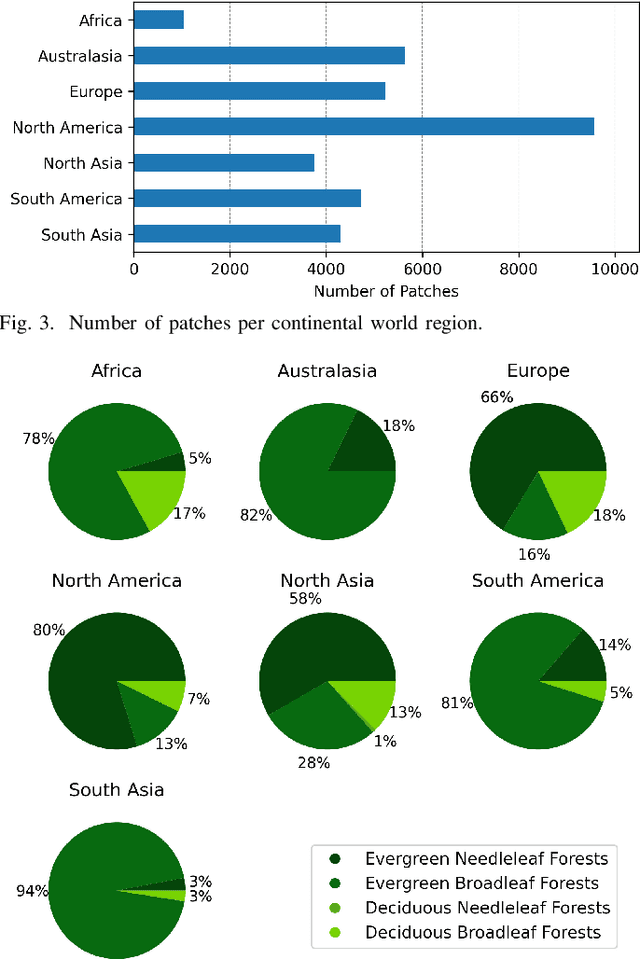
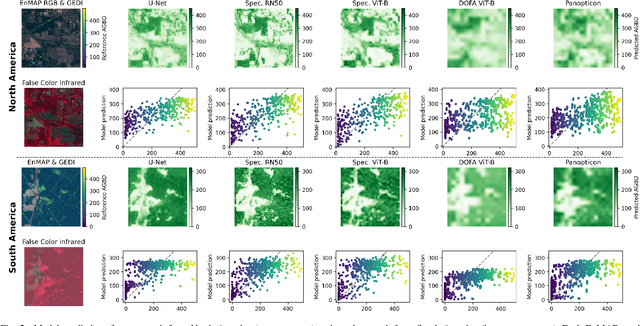
Comprehensive evaluation of geospatial foundation models (Geo-FMs) requires benchmarking across diverse tasks, sensors, and geographic regions. However, most existing benchmark datasets are limited to segmentation or classification tasks, and focus on specific geographic areas. To address this gap, we introduce a globally distributed dataset for forest aboveground biomass (AGB) estimation, a pixel-wise regression task. This benchmark dataset combines co-located hyperspectral imagery (HSI) from the Environmental Mapping and Analysis Program (EnMAP) satellite and predictions of AGB density estimates derived from the Global Ecosystem Dynamics Investigation lidars, covering seven continental regions. Our experimental results on this dataset demonstrate that the evaluated Geo-FMs can match or, in some cases, surpass the performance of a baseline U-Net, especially when fine-tuning the encoder. We also find that the performance difference between the U-Net and Geo-FMs depends on the dataset size for each region and highlight the importance of the token patch size in the Vision Transformer backbone for accurate predictions in pixel-wise regression tasks. By releasing this globally distributed hyperspectral benchmark dataset, we aim to facilitate the development and evaluation of Geo-FMs for HSI applications. Leveraging this dataset additionally enables research into geographic bias and generalization capacity of Geo-FMs. The dataset and source code will be made publicly available.
Hyperspectral Vision Transformers for Greenhouse Gas Estimations from Space
Apr 23, 2025Hyperspectral imaging provides detailed spectral information and holds significant potential for monitoring of greenhouse gases (GHGs). However, its application is constrained by limited spatial coverage and infrequent revisit times. In contrast, multispectral imaging offers broader spatial and temporal coverage but often lacks the spectral detail that can enhance GHG detection. To address these challenges, this study proposes a spectral transformer model that synthesizes hyperspectral data from multispectral inputs. The model is pre-trained via a band-wise masked autoencoder and subsequently fine-tuned on spatio-temporally aligned multispectral-hyperspectral image pairs. The resulting synthetic hyperspectral data retain the spatial and temporal benefits of multispectral imagery and improve GHG prediction accuracy relative to using multispectral data alone. This approach effectively bridges the trade-off between spectral resolution and coverage, highlighting its potential to advance atmospheric monitoring by combining the strengths of hyperspectral and multispectral systems with self-supervised deep learning.
Prospects for Mitigating Spectral Variability in Tropical Species Classification Using Self-Supervised Learning
Mar 17, 2025Airborne hyperspectral imaging is a promising method for identifying tropical species, but spectral variability between acquisitions hinders consistent results. This paper proposes using Self-Supervised Learning (SSL) to encode spectral features that are robust to abiotic variability and relevant for species identification. By employing the state-of-the-art Barlow-Twins approach on repeated spectral acquisitions, we demonstrate the ability to develop stable features. For the classification of 40 tropical species, experiments show that these features can outperform typical reflectance products in terms of robustness to spectral variability by 10 points of accuracy across dates.
* 5 pages, 3 figures, published as proceeding of the "2024 14th Workshop on Hyperspectral Imaging and Signal Processing: Evolution in Remote Sensing (WHISPERS)"
Multispectral to Hyperspectral using Pretrained Foundational model
Feb 26, 2025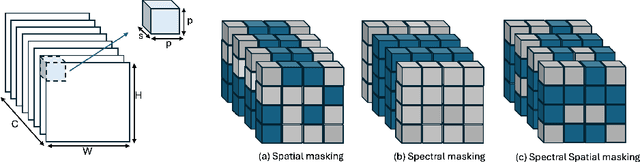
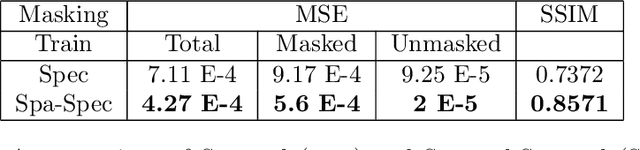
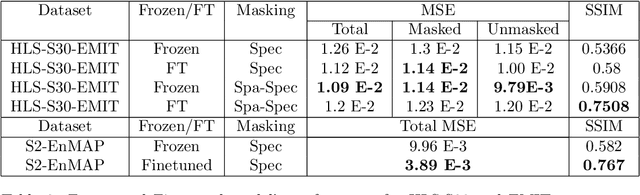
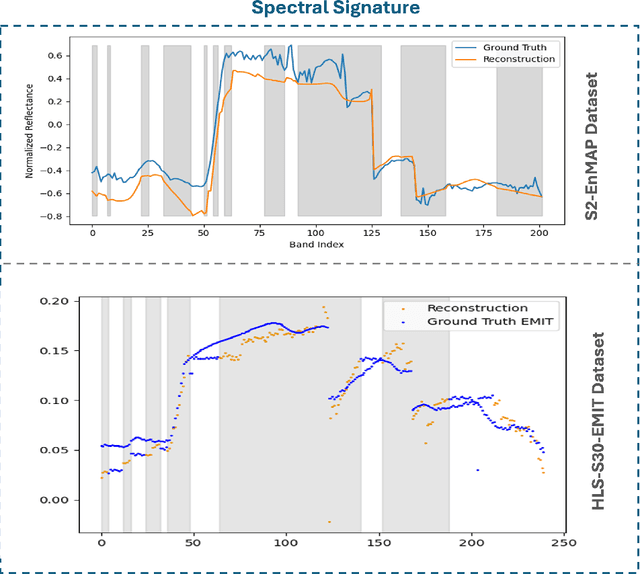
Hyperspectral imaging provides detailed spectral information, offering significant potential for monitoring greenhouse gases like CH4 and NO2. However, its application is constrained by limited spatial coverage and infrequent revisit times. In contrast, multispectral imaging delivers broader spatial and temporal coverage but lacks the spectral granularity required for precise GHG detection. To address these challenges, this study proposes Spectral and Spatial-Spectral transformer models that reconstruct hyperspectral data from multispectral inputs. The models in this paper are pretrained on EnMAP and EMIT datasets and fine-tuned on spatio-temporally aligned (Sentinel-2, EnMAP) and (HLS-S30, EMIT) image pairs respectively. Our model has the potential to enhance atmospheric monitoring by combining the strengths of hyperspectral and multispectral imaging systems.
SpectralEarth: Training Hyperspectral Foundation Models at Scale
Aug 15, 2024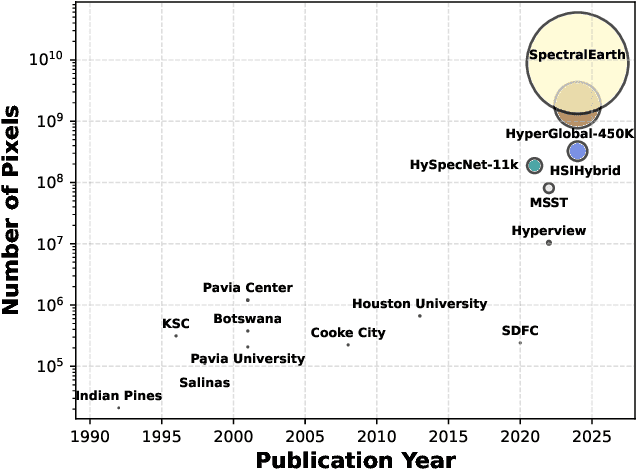
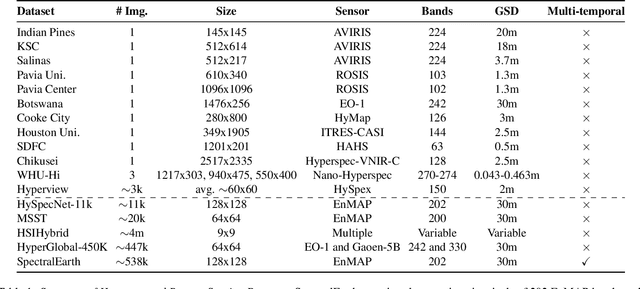

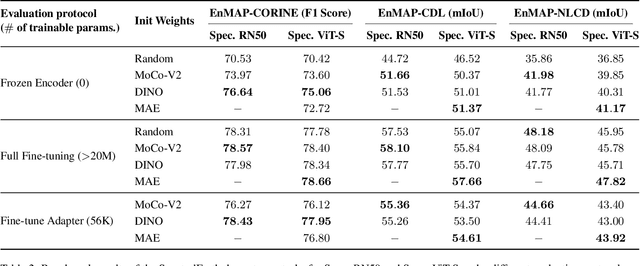
Foundation models have triggered a paradigm shift in computer vision and are increasingly being adopted in remote sensing, particularly for multispectral imagery. Yet, their potential in hyperspectral imaging (HSI) remains untapped due to the absence of comprehensive and globally representative hyperspectral datasets. To close this gap, we introduce SpectralEarth, a large-scale multi-temporal dataset designed to pretrain hyperspectral foundation models leveraging data from the Environmental Mapping and Analysis Program (EnMAP). SpectralEarth comprises 538,974 image patches covering 415,153 unique locations from more than 11,636 globally distributed EnMAP scenes spanning two years of archive. Additionally, 17.5% of these locations include multiple timestamps, enabling multi-temporal HSI analysis. Utilizing state-of-the-art self-supervised learning (SSL) algorithms, we pretrain a series of foundation models on SpectralEarth. We integrate a spectral adapter into classical vision backbones to accommodate the unique characteristics of HSI. In tandem, we construct four downstream datasets for land-cover and crop-type mapping, providing benchmarks for model evaluation. Experimental results support the versatility of our models, showcasing their generalizability across different tasks and sensors. We also highlight computational efficiency during model fine-tuning. The dataset, models, and source code will be made publicly available.
DeCUR: decoupling common & unique representations for multimodal self-supervision
Sep 15, 2023The increasing availability of multi-sensor data sparks interest in multimodal self-supervised learning. However, most existing approaches learn only common representations across modalities while ignoring intra-modal training and modality-unique representations. We propose Decoupling Common and Unique Representations (DeCUR), a simple yet effective method for multimodal self-supervised learning. By distinguishing inter- and intra-modal embeddings, DeCUR is trained to integrate complementary information across different modalities. We evaluate DeCUR in three common multimodal scenarios (radar-optical, RGB-elevation, and RGB-depth), and demonstrate its consistent benefits on scene classification and semantic segmentation downstream tasks. Notably, we get straightforward improvements by transferring our pretrained backbones to state-of-the-art supervised multimodal methods without any hyperparameter tuning. Furthermore, we conduct a comprehensive explainability analysis to shed light on the interpretation of common and unique features in our multimodal approach. Codes are available at \url{https://github.com/zhu-xlab/DeCUR}.
Semi-Supervised Learning for hyperspectral images by non parametrically predicting view assignment
Jun 19, 2023Hyperspectral image (HSI) classification is gaining a lot of momentum in present time because of high inherent spectral information within the images. However, these images suffer from the problem of curse of dimensionality and usually require a large number samples for tasks such as classification, especially in supervised setting. Recently, to effectively train the deep learning models with minimal labelled samples, the unlabeled samples are also being leveraged in self-supervised and semi-supervised setting. In this work, we leverage the idea of semi-supervised learning to assist the discriminative self-supervised pretraining of the models. The proposed method takes different augmented views of the unlabeled samples as input and assigns them the same pseudo-label corresponding to the labelled sample from the downstream task. We train our model on two HSI datasets, namely Houston dataset (from data fusion contest, 2013) and Pavia university dataset, and show that the proposed approach performs better than self-supervised approach and supervised training.
SSL4EO-L: Datasets and Foundation Models for Landsat Imagery
Jun 15, 2023



The Landsat program is the longest-running Earth observation program in history, with 50+ years of data acquisition by 8 satellites. The multispectral imagery captured by sensors onboard these satellites is critical for a wide range of scientific fields. Despite the increasing popularity of deep learning and remote sensing, the majority of researchers still use decision trees and random forests for Landsat image analysis due to the prevalence of small labeled datasets and lack of foundation models. In this paper, we introduce SSL4EO-L, the first ever dataset designed for Self-Supervised Learning for Earth Observation for the Landsat family of satellites (including 3 sensors and 2 product levels) and the largest Landsat dataset in history (5M image patches). Additionally, we modernize and re-release the L7 Irish and L8 Biome cloud detection datasets, and introduce the first ML benchmark datasets for Landsats 4-5 TM and Landsat 7 ETM+ SR. Finally, we pre-train the first foundation models for Landsat imagery using SSL4EO-L and evaluate their performance on multiple semantic segmentation tasks. All datasets and model weights are available via the TorchGeo (https://github.com/microsoft/torchgeo) library, making reproducibility and experimentation easy, and enabling scientific advancements in the burgeoning field of remote sensing for a myriad of downstream applications.