 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBRIGHT: A Collaborative Generalist-Specialist Foundation Model for Breast Pathology
Mar 03, 2026Generalist pathology foundation models (PFMs), pretrained on large-scale multi-organ datasets, have demonstrated remarkable predictive capabilities across diverse clinical applications. However, their proficiency on the full spectrum of clinically essential tasks within a specific organ system remains an open question due to the lack of large-scale validation cohorts for a single organ as well as the absence of a tailored training paradigm that can effectively translate broad histomorphological knowledge into the organ-specific expertise required for specialist-level interpretation. In this study, we propose BRIGHT, the first PFM specifically designed for breast pathology, trained on approximately 210 million histopathology tiles from over 51,000 breast whole-slide images derived from a cohort of over 40,000 patients across 19 hospitals. BRIGHT employs a collaborative generalist-specialist framework to capture both universal and organ-specific features. To comprehensively evaluate the performance of PFMs on breast oncology, we curate the largest multi-institutional cohorts to date for downstream task development and evaluation, comprising over 25,000 WSIs across 10 hospitals. The validation cohorts cover the full spectrum of breast pathology across 24 distinct clinical tasks spanning diagnosis, biomarker prediction, treatment response and survival prediction. Extensive experiments demonstrate that BRIGHT outperforms three leading generalist PFMs, achieving state-of-the-art (SOTA) performance in 21 of 24 internal validation tasks and in 5 of 10 external validation tasks with excellent heatmap interpretability. By evaluating on large-scale validation cohorts, this study not only demonstrates BRIGHT's clinical utility in breast oncology but also validates a collaborative generalist-specialist paradigm, providing a scalable template for developing PFMs on a specific organ system.
LandSegmenter: Towards a Flexible Foundation Model for Land Use and Land Cover Mapping
Nov 11, 2025Land Use and Land Cover (LULC) mapping is a fundamental task in Earth Observation (EO). However, current LULC models are typically developed for a specific modality and a fixed class taxonomy, limiting their generability and broader applicability. Recent advances in foundation models (FMs) offer promising opportunities for building universal models. Yet, task-agnostic FMs often require fine-tuning for downstream applications, whereas task-specific FMs rely on massive amounts of labeled data for training, which is costly and impractical in the remote sensing (RS) domain. To address these challenges, we propose LandSegmenter, an LULC FM framework that resolves three-stage challenges at the input, model, and output levels. From the input side, to alleviate the heavy demand on labeled data for FM training, we introduce LAnd Segment (LAS), a large-scale, multi-modal, multi-source dataset built primarily with globally sampled weak labels from existing LULC products. LAS provides a scalable, cost-effective alternative to manual annotation, enabling large-scale FM training across diverse LULC domains. For model architecture, LandSegmenter integrates an RS-specific adapter for cross-modal feature extraction and a text encoder for semantic awareness enhancement. At the output stage, we introduce a class-wise confidence-guided fusion strategy to mitigate semantic omissions and further improve LandSegmenter's zero-shot performance. We evaluate LandSegmenter on six precisely annotated LULC datasets spanning diverse modalities and class taxonomies. Extensive transfer learning and zero-shot experiments demonstrate that LandSegmenter achieves competitive or superior performance, particularly in zero-shot settings when transferred to unseen datasets. These results highlight the efficacy of our proposed framework and the utility of weak supervision for building task-specific FMs.
Towards a Unified Copernicus Foundation Model for Earth Vision
Mar 14, 2025Advances in Earth observation (EO) foundation models have unlocked the potential of big satellite data to learn generic representations from space, benefiting a wide range of downstream applications crucial to our planet. However, most existing efforts remain limited to fixed spectral sensors, focus solely on the Earth's surface, and overlook valuable metadata beyond imagery. In this work, we take a step towards next-generation EO foundation models with three key components: 1) Copernicus-Pretrain, a massive-scale pretraining dataset that integrates 18.7M aligned images from all major Copernicus Sentinel missions, spanning from the Earth's surface to its atmosphere; 2) Copernicus-FM, a unified foundation model capable of processing any spectral or non-spectral sensor modality using extended dynamic hypernetworks and flexible metadata encoding; and 3) Copernicus-Bench, a systematic evaluation benchmark with 15 hierarchical downstream tasks ranging from preprocessing to specialized applications for each Sentinel mission. Our dataset, model, and benchmark greatly improve the scalability, versatility, and multimodal adaptability of EO foundation models, while also creating new opportunities to connect EO, weather, and climate research. Codes, datasets and models are available at https://github.com/zhu-xlab/Copernicus-FM.
Designing Kresling Origami for Personalised Wrist Orthosis
Jan 30, 2025The wrist plays a pivotal role in facilitating motion dexterity and hand functions. Wrist orthoses, from passive braces to active exoskeletons, provide an effective solution for the assistance and rehabilitation of motor abilities. However, the type of motions facilitated by currently available orthoses is limited, with little emphasis on personalised design. To address these gaps, this paper proposes a novel wrist orthosis design inspired by the Kresling origami. The design can be adapted to accommodate various individual shape parameters, which benefits from the topological variations and intrinsic compliance of origami. Heat-sealable fabrics are used to replicate the non-rigid nature of the Kresling origami. The orthosis is capable of six distinct motion modes with a detachable tendon-based actuation system. Experimental characterisation of the workspace has been conducted by activating tendons individually. The maximum bending angle in each direction ranges from 18.81{\deg} to 32.63{\deg}. When tendons are pulled in combination, the maximum bending angles in the dorsal, palmar, radial, and ulnar directions are 31.66{\deg}, 30.38{\deg}, 27.14{\deg}, and 14.92{\deg}, respectively. The capability to generate complex motions such as the dart-throwing motion and circumduction has also been experimentally validated. The work presents a promising foundation for the development of personalised wrist orthoses for training and rehabilitation.
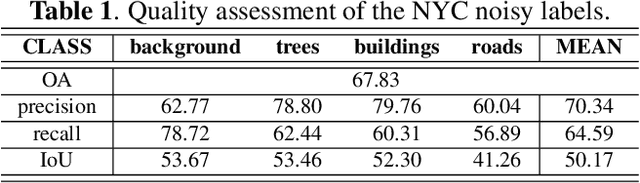
AutoLCZ: Towards Automatized Local Climate Zone Mapping from Rule-Based Remote Sensing
May 22, 2024



Local climate zones (LCZs) established a standard classification system to categorize the landscape universe for improved urban climate studies. Existing LCZ mapping is guided by human interaction with geographic information systems (GIS) or modelled from remote sensing (RS) data. GIS-based methods do not scale to large areas. However, RS-based methods leverage machine learning techniques to automatize LCZ classification from RS. Yet, RS-based methods require huge amounts of manual labels for training. We propose a novel LCZ mapping framework, termed AutoLCZ, to extract the LCZ classification features from high-resolution RS modalities. We study the definition of numerical rules designed to mimic the LCZ definitions. Those rules model geometric and surface cover properties from LiDAR data. Correspondingly, we enable LCZ classification from RS data in a GIS-based scheme. The proposed AutoLCZ method has potential to reduce the human labor to acquire accurate metadata. At the same time, AutoLCZ sheds light on the physical interpretability of RS-based methods. In a proof-of-concept for New York City (NYC) we leverage airborne LiDAR surveys to model 4 LCZ features to distinguish 10 LCZ types. The results indicate the potential of AutoLCZ as promising avenue for large-scale LCZ mapping from RS data.
CromSS: Cross-modal pre-training with noisy labels for remote sensing image segmentation
May 02, 2024


We study the potential of noisy labels y to pretrain semantic segmentation models in a multi-modal learning framework for geospatial applications. Specifically, we propose a novel Cross-modal Sample Selection method (CromSS) that utilizes the class distributions P^{(d)}(x,c) over pixels x and classes c modelled by multiple sensors/modalities d of a given geospatial scene. Consistency of predictions across sensors $d$ is jointly informed by the entropy of P^{(d)}(x,c). Noisy label sampling we determine by the confidence of each sensor d in the noisy class label, P^{(d)}(x,c=y(x)). To verify the performance of our approach, we conduct experiments with Sentinel-1 (radar) and Sentinel-2 (optical) satellite imagery from the globally-sampled SSL4EO-S12 dataset. We pair those scenes with 9-class noisy labels sourced from the Google Dynamic World project for pretraining. Transfer learning evaluations (downstream task) on the DFC2020 dataset confirm the effectiveness of the proposed method for remote sensing image segmentation.
AIO2: Online Correction of Object Labels for Deep Learning with Incomplete Annotation in Remote Sensing Image Segmentation
Mar 03, 2024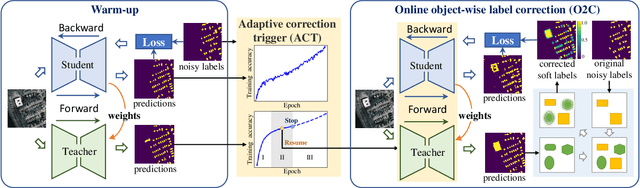
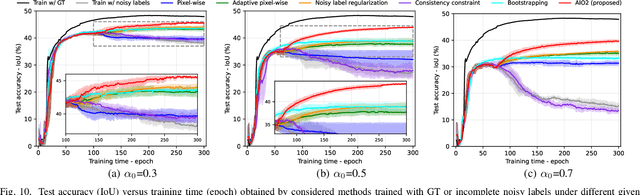

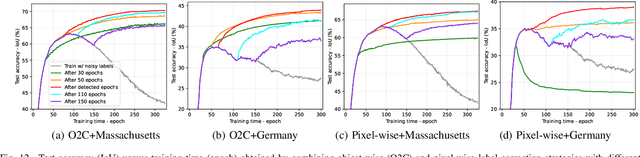
While the volume of remote sensing data is increasing daily, deep learning in Earth Observation faces lack of accurate annotations for supervised optimization. Crowdsourcing projects such as OpenStreetMap distribute the annotation load to their community. However, such annotation inevitably generates noise due to insufficient control of the label quality, lack of annotators, frequent changes of the Earth's surface as a result of natural disasters and urban development, among many other factors. We present Adaptively trIggered Online Object-wise correction (AIO2) to address annotation noise induced by incomplete label sets. AIO2 features an Adaptive Correction Trigger (ACT) module that avoids label correction when the model training under- or overfits, and an Online Object-wise Correction (O2C) methodology that employs spatial information for automated label modification. AIO2 utilizes a mean teacher model to enhance training robustness with noisy labels to both stabilize the training accuracy curve for fitting in ACT and provide pseudo labels for correction in O2C. Moreover, O2C is implemented online without the need to store updated labels every training epoch. We validate our approach on two building footprint segmentation datasets with different spatial resolutions. Experimental results with varying degrees of building label noise demonstrate the robustness of AIO2. Source code will be available at https://github.com/zhu-xlab/AIO2.git.
Task Specific Pretraining with Noisy Labels for Remote sensing Image Segmentation
Feb 25, 2024
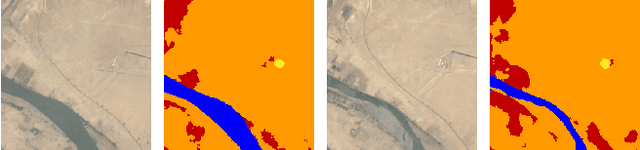
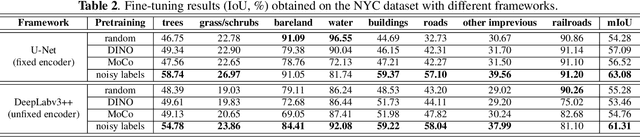
In recent years, self-supervision has drawn a lot of attention in remote sensing society due to its ability to reduce the demand of exact labels in supervised deep learning model training. Self-supervision methods generally utilize image-level information to pretrain models in an unsupervised fashion. Though these pretrained encoders show effectiveness in many downstream tasks, their performance on segmentation tasks is often not as good as that on classification tasks. On the other hand, many easily available label sources (e.g., automatic labeling tools and land cover land use products) exist, which can provide a large amount of noisy labels for segmentation model training. In this work, we propose to explore the under-exploited potential of noisy labels for segmentation task specific pretraining, and exam its robustness when confronted with mismatched categories and different decoders during fine-tuning. Specifically, we inspect the impacts of noisy labels on different layers in supervised model training to serve as the basis of our work. Experiments on two datasets indicate the effectiveness of task specific supervised pretraining with noisy labels. The findings are expected to shed light on new avenues for improving the accuracy and versatility of pretraining strategies for remote sensing image segmentation.
DeCUR: decoupling common & unique representations for multimodal self-supervision
Sep 15, 2023The increasing availability of multi-sensor data sparks interest in multimodal self-supervised learning. However, most existing approaches learn only common representations across modalities while ignoring intra-modal training and modality-unique representations. We propose Decoupling Common and Unique Representations (DeCUR), a simple yet effective method for multimodal self-supervised learning. By distinguishing inter- and intra-modal embeddings, DeCUR is trained to integrate complementary information across different modalities. We evaluate DeCUR in three common multimodal scenarios (radar-optical, RGB-elevation, and RGB-depth), and demonstrate its consistent benefits on scene classification and semantic segmentation downstream tasks. Notably, we get straightforward improvements by transferring our pretrained backbones to state-of-the-art supervised multimodal methods without any hyperparameter tuning. Furthermore, we conduct a comprehensive explainability analysis to shed light on the interpretation of common and unique features in our multimodal approach. Codes are available at \url{https://github.com/zhu-xlab/DeCUR}.
Deep Semantic Model Fusion for Ancient Agricultural Terrace Detection
Aug 04, 2023Discovering ancient agricultural terraces in desert regions is important for the monitoring of long-term climate changes on the Earth's surface. However, traditional ground surveys are both costly and limited in scale. With the increasing accessibility of aerial and satellite data, machine learning techniques bear large potential for the automatic detection and recognition of archaeological landscapes. In this paper, we propose a deep semantic model fusion method for ancient agricultural terrace detection. The input data includes aerial images and LiDAR generated terrain features in the Negev desert. Two deep semantic segmentation models, namely DeepLabv3+ and UNet, with EfficientNet backbone, are trained and fused to provide segmentation maps of ancient terraces and walls. The proposed method won the first prize in the International AI Archaeology Challenge. Codes are available at https://github.com/wangyi111/international-archaeology-ai-challenge.