 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBigEarthNet.txt: A Large-Scale Multi-Sensor Image-Text Dataset and Benchmark for Earth Observation
Apr 01, 2026Vision-langugage models (VLMs) have shown strong performance in computer vision (CV), yet their performance on remote sensing (RS) data remains limited due to the lack of large-scale, multi-sensor RS image-text datasets with diverse textual annotations. Existing datasets predominantly include aerial Red-Green-Blue imagery, with short or weakly grounded captions, and provide limited diversity in annotation types. To address this limitation, we introduce BigEarthNet$.$txt, a large-scale, multi-sensor image-text dataset designed to advance instruction-driven image-text learning in Earth observation across multiple tasks. BigEarthNet$.$txt contains 464044 co-registered Sentinel-1 synthetic aperture radar and Sentinel-2 multispectral images with 9.6M text annotations, including: i) geographically anchored captions describing land-use/land-cover (LULC) classes, their spatial relations, and environmental context; ii) visual question answering pairs relevant for different tasks; and iii) referring expression detection instructions for bounding box prediction. Through a comparative statistical analysis, we demonstrate that BigEarthNet$.$txt surpasses existing RS image-text datasets in textual richness and annotation type variety. We further establish a manually-verified benchmark split to evaluate VLMs in RS and CV. The results show the limitations of these models on tasks that involve complex LULC classes, whereas fine-tuning using BigEarthNet$.$txt results in consistent performance gains across all considered tasks.
Probabilistic Machine Learning for Noisy Labels in Earth Observation
Apr 04, 2025Label noise poses a significant challenge in Earth Observation (EO), often degrading the performance and reliability of supervised Machine Learning (ML) models. Yet, given the critical nature of several EO applications, developing robust and trustworthy ML solutions is essential. In this study, we take a step in this direction by leveraging probabilistic ML to model input-dependent label noise and quantify data uncertainty in EO tasks, accounting for the unique noise sources inherent in the domain. We train uncertainty-aware probabilistic models across a broad range of high-impact EO applications-spanning diverse noise sources, input modalities, and ML configurations-and introduce a dedicated pipeline to assess their accuracy and reliability. Our experimental results show that the uncertainty-aware models consistently outperform the standard deterministic approaches across most datasets and evaluation metrics. Moreover, through rigorous uncertainty evaluation, we validate the reliability of the predicted uncertainty estimates, enhancing the interpretability of model predictions. Our findings emphasize the importance of modeling label noise and incorporating uncertainty quantification in EO, paving the way for more accurate, reliable, and trustworthy ML solutions in the field.
Towards a Unified Copernicus Foundation Model for Earth Vision
Mar 14, 2025Advances in Earth observation (EO) foundation models have unlocked the potential of big satellite data to learn generic representations from space, benefiting a wide range of downstream applications crucial to our planet. However, most existing efforts remain limited to fixed spectral sensors, focus solely on the Earth's surface, and overlook valuable metadata beyond imagery. In this work, we take a step towards next-generation EO foundation models with three key components: 1) Copernicus-Pretrain, a massive-scale pretraining dataset that integrates 18.7M aligned images from all major Copernicus Sentinel missions, spanning from the Earth's surface to its atmosphere; 2) Copernicus-FM, a unified foundation model capable of processing any spectral or non-spectral sensor modality using extended dynamic hypernetworks and flexible metadata encoding; and 3) Copernicus-Bench, a systematic evaluation benchmark with 15 hierarchical downstream tasks ranging from preprocessing to specialized applications for each Sentinel mission. Our dataset, model, and benchmark greatly improve the scalability, versatility, and multimodal adaptability of EO foundation models, while also creating new opportunities to connect EO, weather, and climate research. Codes, datasets and models are available at https://github.com/zhu-xlab/Copernicus-FM.
GAIA: A Global, Multi-modal, Multi-scale Vision-Language Dataset for Remote Sensing Image Analysis
Feb 13, 2025
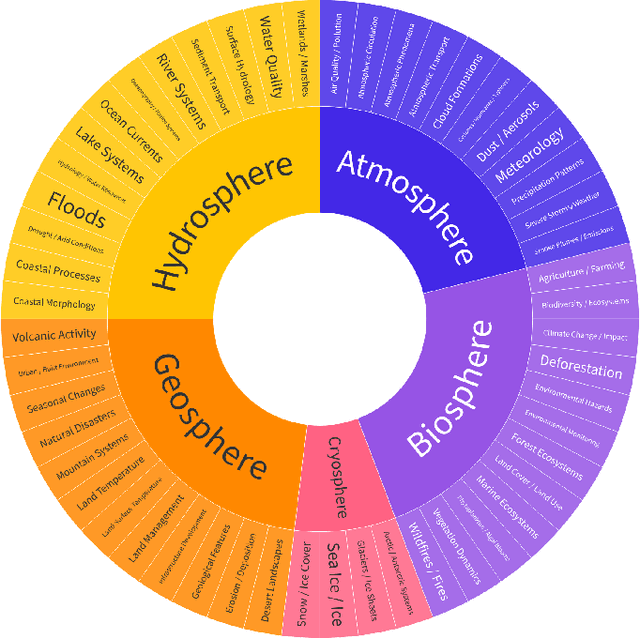
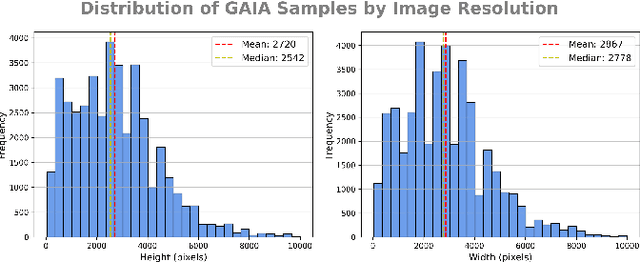

The continuous operation of Earth-orbiting satellites generates vast and ever-growing archives of Remote Sensing (RS) images. Natural language presents an intuitive interface for accessing, querying, and interpreting the data from such archives. However, existing Vision-Language Models (VLMs) are predominantly trained on web-scraped, noisy image-text data, exhibiting limited exposure to the specialized domain of RS. This deficiency results in poor performance on RS-specific tasks, as commonly used datasets often lack detailed, scientifically accurate textual descriptions and instead emphasize solely on attributes like date and location. To bridge this critical gap, we introduce GAIA, a novel dataset designed for multi-scale, multi-sensor, and multi-modal RS image analysis. GAIA comprises of 205,150 meticulously curated RS image-text pairs, representing a diverse range of RS modalities associated to different spatial resolutions. Unlike existing vision-language datasets in RS, GAIA specifically focuses on capturing a diverse range of RS applications, providing unique information about environmental changes, natural disasters, and various other dynamic phenomena. The dataset provides a spatially and temporally balanced distribution, spanning across the globe, covering the last 25 years with a balanced temporal distribution of observations. GAIA's construction involved a two-stage process: (1) targeted web-scraping of images and accompanying text from reputable RS-related sources, and (2) generation of five high-quality, scientifically grounded synthetic captions for each image using carefully crafted prompts that leverage the advanced vision-language capabilities of GPT-4o. Our extensive experiments, including fine-tuning of CLIP and BLIP2 models, demonstrate that GAIA significantly improves performance on RS image classification, cross-modal retrieval and image captioning tasks.
Mind the Modality Gap: Towards a Remote Sensing Vision-Language Model via Cross-modal Alignment
Feb 15, 2024Deep Learning (DL) is undergoing a paradigm shift with the emergence of foundation models, aptly named by their crucial, yet incomplete nature. In this work, we focus on Contrastive Language-Image Pre-training (CLIP), an open-vocabulary foundation model, which achieves high accuracy across many image classification tasks and is often competitive with a fully supervised baseline without being explicitly trained. Nevertheless, there are still domains where zero-shot CLIP performance is far from optimal, such as Remote Sensing (RS) and medical imagery. These domains do not only exhibit fundamentally different distributions compared to natural images, but also commonly rely on complementary modalities, beyond RGB, to derive meaningful insights. To this end, we propose a methodology for the purpose of aligning distinct RS imagery modalities with the visual and textual modalities of CLIP. Our two-stage procedure, comprises of robust fine-tuning CLIP in order to deal with the distribution shift, accompanied by the cross-modal alignment of a RS modality encoder, in an effort to extend the zero-shot capabilities of CLIP. We ultimately demonstrate our method on the tasks of RS imagery classification and cross-modal retrieval. We empirically show that both robust fine-tuning and cross-modal alignment translate to significant performance gains, across several RS benchmark datasets. Notably, these enhancements are achieved without the reliance on textual descriptions, without introducing any task-specific parameters, without training from scratch and without catastrophic forgetting.
Kuro Siwo: 12.1 billion $m^2$ under the water. A global multi-temporal satellite dataset for rapid flood mapping
Nov 18, 2023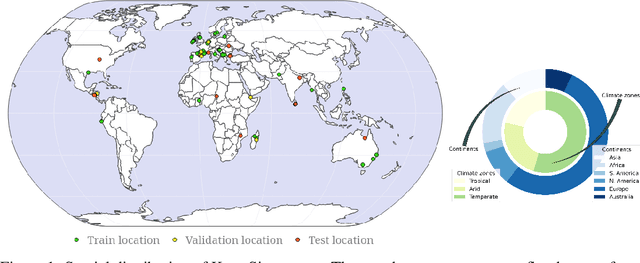
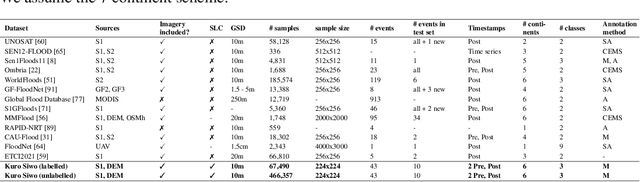
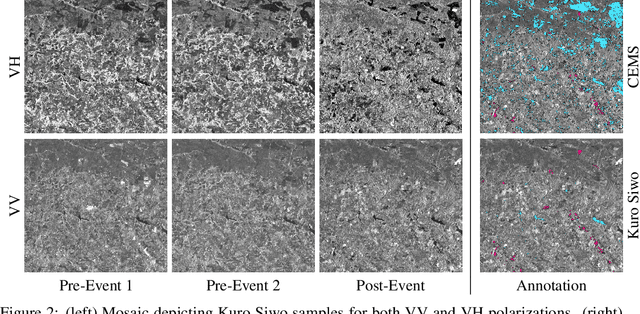
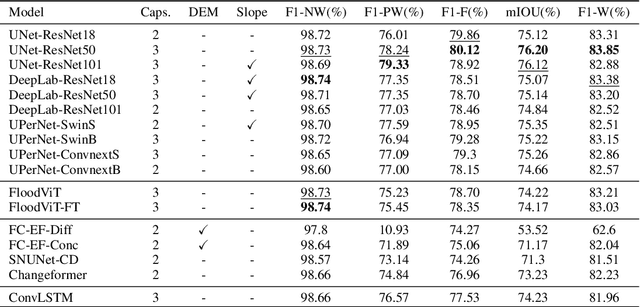
Global floods, exacerbated by climate change, pose severe threats to human life, infrastructure, and the environment. This urgency is highlighted by recent catastrophic events in Pakistan and New Zealand, underlining the critical need for precise flood mapping for guiding restoration efforts, understanding vulnerabilities, and preparing for future events. While Synthetic Aperture Radar (SAR) offers day-and-night, all-weather imaging capabilities, harnessing it for deep learning is hindered by the absence of a large annotated dataset. To bridge this gap, we introduce Kuro Siwo, a meticulously curated multi-temporal dataset, spanning 32 flood events globally. Our dataset maps more than 63 billion m2 of land, with 12.1 billion of them being either a flooded area or a permanent water body. Kuro Siwo stands out for its unparalleled annotation quality to facilitate rapid flood mapping in a supervised setting. We also augment learning by including a large unlabeled set of SAR samples, aimed at self-supervised pretraining. We provide an extensive benchmark and strong baselines for a diverse set of flood events from Europe, America, Africa and Australia. Our benchmark demonstrates the quality of Kuro Siwo annotations, training models that can achieve $\approx$ 85% and $\approx$ 87% in F1-score for flooded areas and general water detection respectively. This work calls on the deep learning community to develop solution-driven algorithms for rapid flood mapping, with the potential to aid civil protection and humanitarian agencies amid climate change challenges. Our code and data will be made available at https://github.com/Orion-AI-Lab/KuroSiwo
Efficient deep learning models for land cover image classification
Nov 18, 2021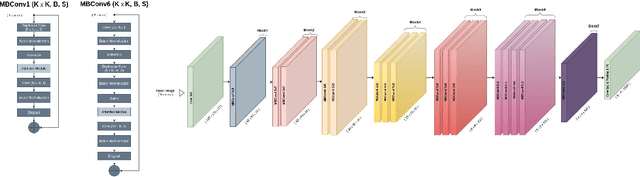
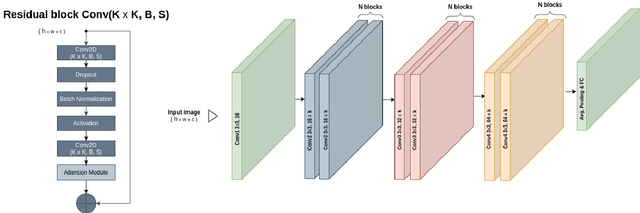
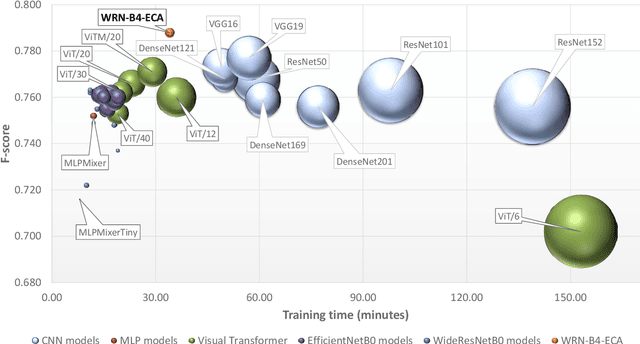

The availability of the sheer volume of Copernicus Sentinel imagery has created new opportunities for land use land cover (LULC) mapping at large scales using deep learning. Training on such large datasets though is a non-trivial task. In this work we experiment with the BigEarthNet dataset for LULC image classification and benchmark different state-of-the-art models, including Convolution Neural Networks, Multi-Layer Perceptrons, Visual Transformers, EfficientNets and Wide Residual Networks (WRN) architectures. Our aim is to leverage classification accuracy, training time and inference rate. We propose a framework based on EfficientNets for compound scaling of WRNs in terms of network depth, width and input data resolution, for efficiently training and testing different model setups. We design a novel scaled WRN architecture enhanced with an Efficient Channel Attention mechanism. Our proposed lightweight model has an order of magnitude less trainable parameters, achieves 4.5% higher averaged f-score classification accuracy for all 19 LULC classes and is trained two times faster with respect to a ResNet50 state-of-the-art model that we use as a baseline. We provide access to more than 50 trained models, along with our code for distributed training on multiple GPU nodes.