 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Unified Copernicus Foundation Model for Earth Vision
Mar 14, 2025Advances in Earth observation (EO) foundation models have unlocked the potential of big satellite data to learn generic representations from space, benefiting a wide range of downstream applications crucial to our planet. However, most existing efforts remain limited to fixed spectral sensors, focus solely on the Earth's surface, and overlook valuable metadata beyond imagery. In this work, we take a step towards next-generation EO foundation models with three key components: 1) Copernicus-Pretrain, a massive-scale pretraining dataset that integrates 18.7M aligned images from all major Copernicus Sentinel missions, spanning from the Earth's surface to its atmosphere; 2) Copernicus-FM, a unified foundation model capable of processing any spectral or non-spectral sensor modality using extended dynamic hypernetworks and flexible metadata encoding; and 3) Copernicus-Bench, a systematic evaluation benchmark with 15 hierarchical downstream tasks ranging from preprocessing to specialized applications for each Sentinel mission. Our dataset, model, and benchmark greatly improve the scalability, versatility, and multimodal adaptability of EO foundation models, while also creating new opportunities to connect EO, weather, and climate research. Codes, datasets and models are available at https://github.com/zhu-xlab/Copernicus-FM.
A Practical Guide to Statistical Distances for Evaluating Generative Models in Science
Mar 19, 2024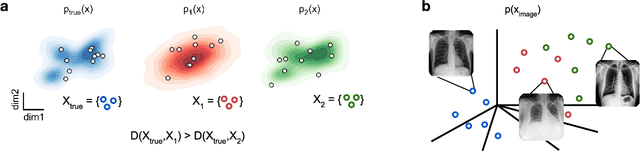
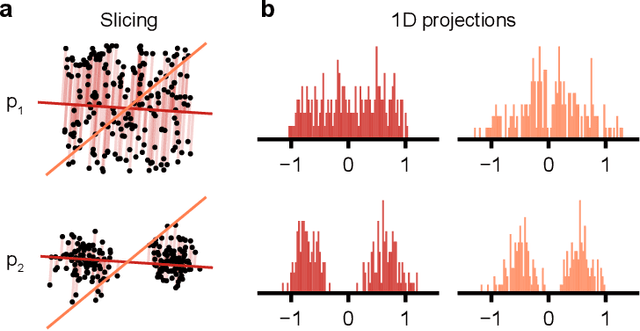
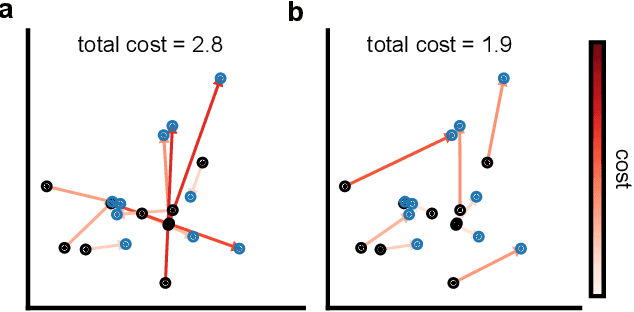
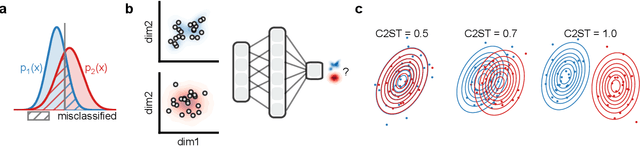
Generative models are invaluable in many fields of science because of their ability to capture high-dimensional and complicated distributions, such as photo-realistic images, protein structures, and connectomes. How do we evaluate the samples these models generate? This work aims to provide an accessible entry point to understanding popular notions of statistical distances, requiring only foundational knowledge in mathematics and statistics. We focus on four commonly used notions of statistical distances representing different methodologies: Using low-dimensional projections (Sliced-Wasserstein; SW), obtaining a distance using classifiers (Classifier Two-Sample Tests; C2ST), using embeddings through kernels (Maximum Mean Discrepancy; MMD), or neural networks (Fr\'echet Inception Distance; FID). We highlight the intuition behind each distance and explain their merits, scalability, complexity, and pitfalls. To demonstrate how these distances are used in practice, we evaluate generative models from different scientific domains, namely a model of decision making and a model generating medical images. We showcase that distinct distances can give different results on similar data. Through this guide, we aim to help researchers to use, interpret, and evaluate statistical distances for generative models in science.