 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgesbi reloaded: a toolkit for simulation-based inference workflows
Nov 26, 2024
Scientists and engineers use simulators to model empirically observed phenomena. However, tuning the parameters of a simulator to ensure its outputs match observed data presents a significant challenge. Simulation-based inference (SBI) addresses this by enabling Bayesian inference for simulators, identifying parameters that match observed data and align with prior knowledge. Unlike traditional Bayesian inference, SBI only needs access to simulations from the model and does not require evaluations of the likelihood-function. In addition, SBI algorithms do not require gradients through the simulator, allow for massive parallelization of simulations, and can perform inference for different observations without further simulations or training, thereby amortizing inference. Over the past years, we have developed, maintained, and extended $\texttt{sbi}$, a PyTorch-based package that implements Bayesian SBI algorithms based on neural networks. The $\texttt{sbi}$ toolkit implements a wide range of inference methods, neural network architectures, sampling methods, and diagnostic tools. In addition, it provides well-tested default settings but also offers flexibility to fully customize every step of the simulation-based inference workflow. Taken together, the $\texttt{sbi}$ toolkit enables scientists and engineers to apply state-of-the-art SBI methods to black-box simulators, opening up new possibilities for aligning simulations with empirically observed data.
A Practical Guide to Statistical Distances for Evaluating Generative Models in Science
Mar 19, 2024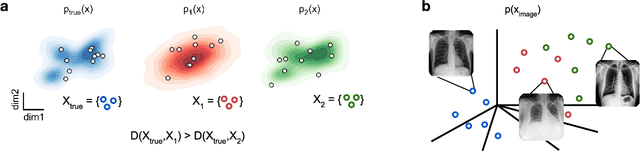
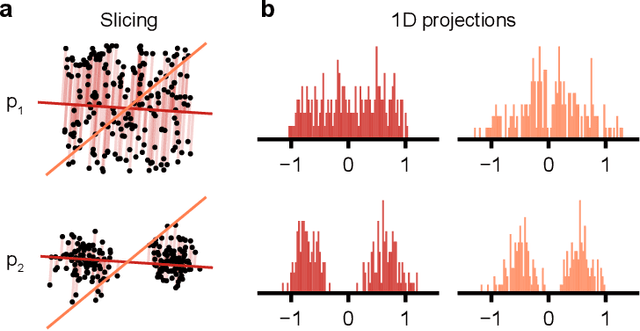
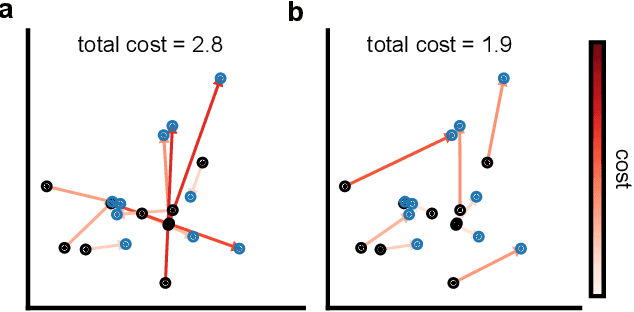
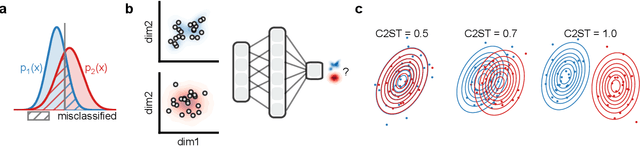
Generative models are invaluable in many fields of science because of their ability to capture high-dimensional and complicated distributions, such as photo-realistic images, protein structures, and connectomes. How do we evaluate the samples these models generate? This work aims to provide an accessible entry point to understanding popular notions of statistical distances, requiring only foundational knowledge in mathematics and statistics. We focus on four commonly used notions of statistical distances representing different methodologies: Using low-dimensional projections (Sliced-Wasserstein; SW), obtaining a distance using classifiers (Classifier Two-Sample Tests; C2ST), using embeddings through kernels (Maximum Mean Discrepancy; MMD), or neural networks (Fr\'echet Inception Distance; FID). We highlight the intuition behind each distance and explain their merits, scalability, complexity, and pitfalls. To demonstrate how these distances are used in practice, we evaluate generative models from different scientific domains, namely a model of decision making and a model generating medical images. We showcase that distinct distances can give different results on similar data. Through this guide, we aim to help researchers to use, interpret, and evaluate statistical distances for generative models in science.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
On Second-order Optimization Methods for Federated Learning
Sep 06, 2021

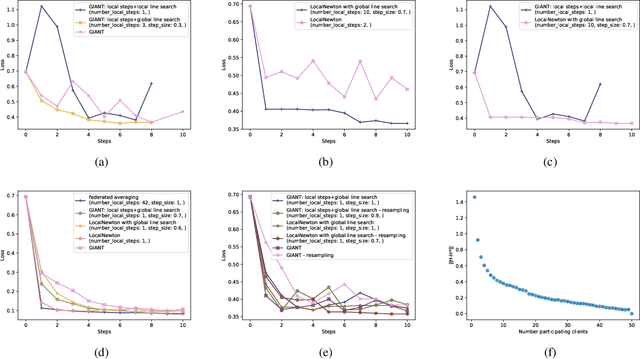
We consider federated learning (FL), where the training data is distributed across a large number of clients. The standard optimization method in this setting is Federated Averaging (FedAvg), which performs multiple local first-order optimization steps between communication rounds. In this work, we evaluate the performance of several second-order distributed methods with local steps in the FL setting which promise to have favorable convergence properties. We (i) show that FedAvg performs surprisingly well against its second-order competitors when evaluated under fair metrics (equal amount of local computations)-in contrast to the results of previous work. Based on our numerical study, we propose (ii) a novel variant that uses second-order local information for updates and a global line search to counteract the resulting local specificity.
The Importance of Suppressing Domain Style in Authorship Analysis
May 29, 2020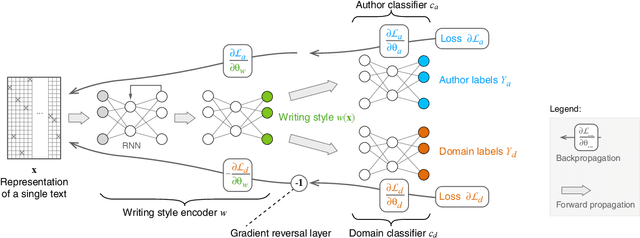
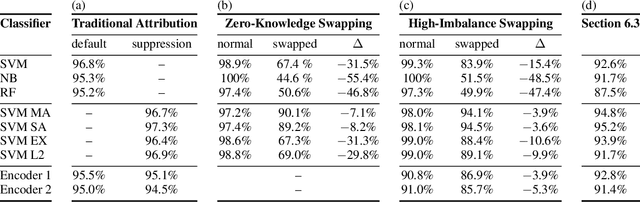

The prerequisite of many approaches to authorship analysis is a representation of writing style. But despite decades of research, it still remains unclear to what extent commonly used and widely accepted representations like character trigram frequencies actually represent an author's writing style, in contrast to more domain-specific style components or even topic. We address this shortcoming for the first time in a novel experimental setup of fixed authors but swapped domains between training and testing. With this setup, we reveal that approaches using character trigram features are highly susceptible to favor domain information when applied without attention to domains, suffering drops of up to 55.4 percentage points in classification accuracy under domain swapping. We further propose a new remedy based on domain-adversarial learning and compare it to ones from the literature based on heuristic rules. Both can work well, reducing accuracy losses under domain swapping to 3.6% and 3.9%, respectively.
Feature Learning for Meta-Paths in Knowledge Graphs
Sep 07, 2018


In this thesis, we study the problem of feature learning on heterogeneous knowledge graphs. These features can be used to perform tasks such as link prediction, classification and clustering on graphs. Knowledge graphs provide rich semantics encoded in the edge and node types. Meta-paths consist of these types and abstract paths in the graph. Until now, meta-paths can only be used as categorical features with high redundancy and are therefore unsuitable for machine learning models. We propose meta-path embeddings to solve this problem by learning semantical and compact vector representations of them. Current graph embedding methods only embed nodes and edge types and therefore miss semantics encoded in the combination of them. Our method embeds meta-paths using the skipgram model with an extension to deal with the redundancy and high amount of meta-paths in big knowledge graphs. We critically evaluate our embedding approach by predicting links on Wikidata. The experiments indicate that we learn a sensible embedding of the meta-paths but can improve it further.